大数据系列之数据仓库Hive原理
Hive系列博文,持续更新~~~
大数据系列之数据仓库Hive原理
大数据系列之数据仓库Hive安装
大数据系列之数据仓库Hive中分区Partition如何使用
大数据系列之数据仓库Hive命令使用及JDBC连接
Hive的工作原理简单来说就是一个查询引擎
先来一张Hive的架构图:
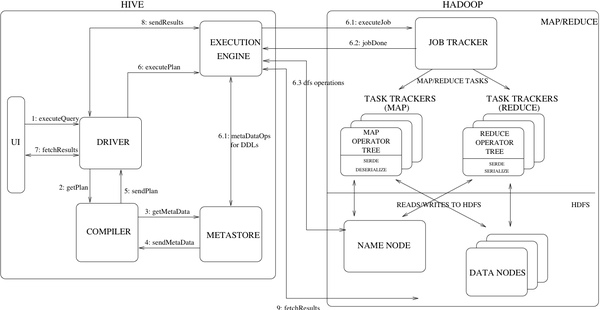
Hive的工作原理如下:
接收到一个sql,后面做的事情包括:
1.词法分析/语法分析
使用antlr将SQL语句解析成抽象语法树-AST
2.语义分析
从Megastore获取模式信息,验证SQL语句中队表名,列名,以及数据类型的检查和隐式转换,以及Hive提供的函数和用户自定义的函数(UDF/UAF)
3.逻辑计划生产
生成逻辑计划-算子树
4.逻辑计划优化
对算子树进行优化,包括列剪枝,分区剪枝,谓词下推等
5.物理计划生成
将逻辑计划生产包含由MapReduce任务组成的DAG的物理计划
6.物理计划执行
将DAG发送到Hadoop集群进行执行
7.将查询结果返回
流程如下图:
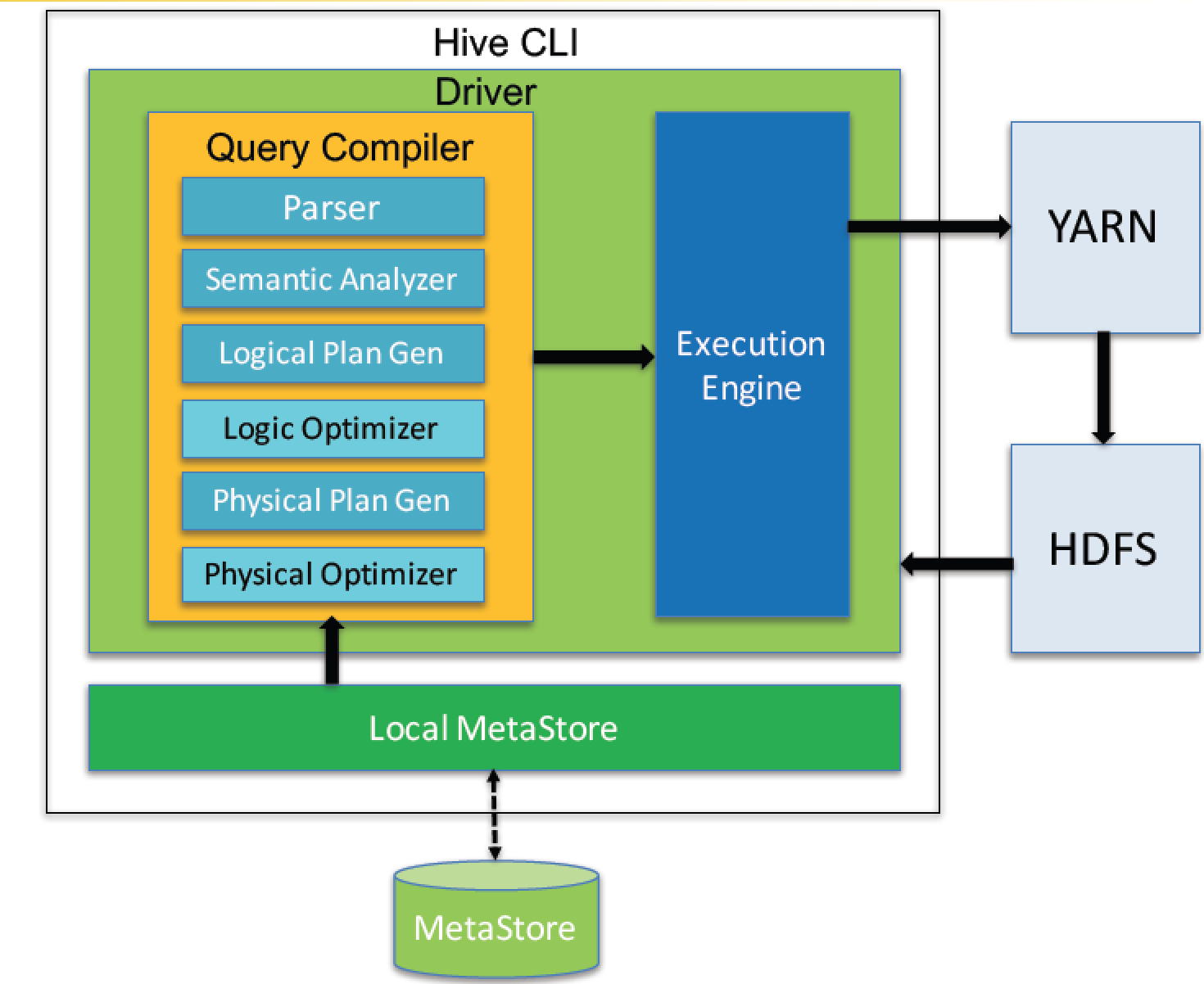
Query Compiler
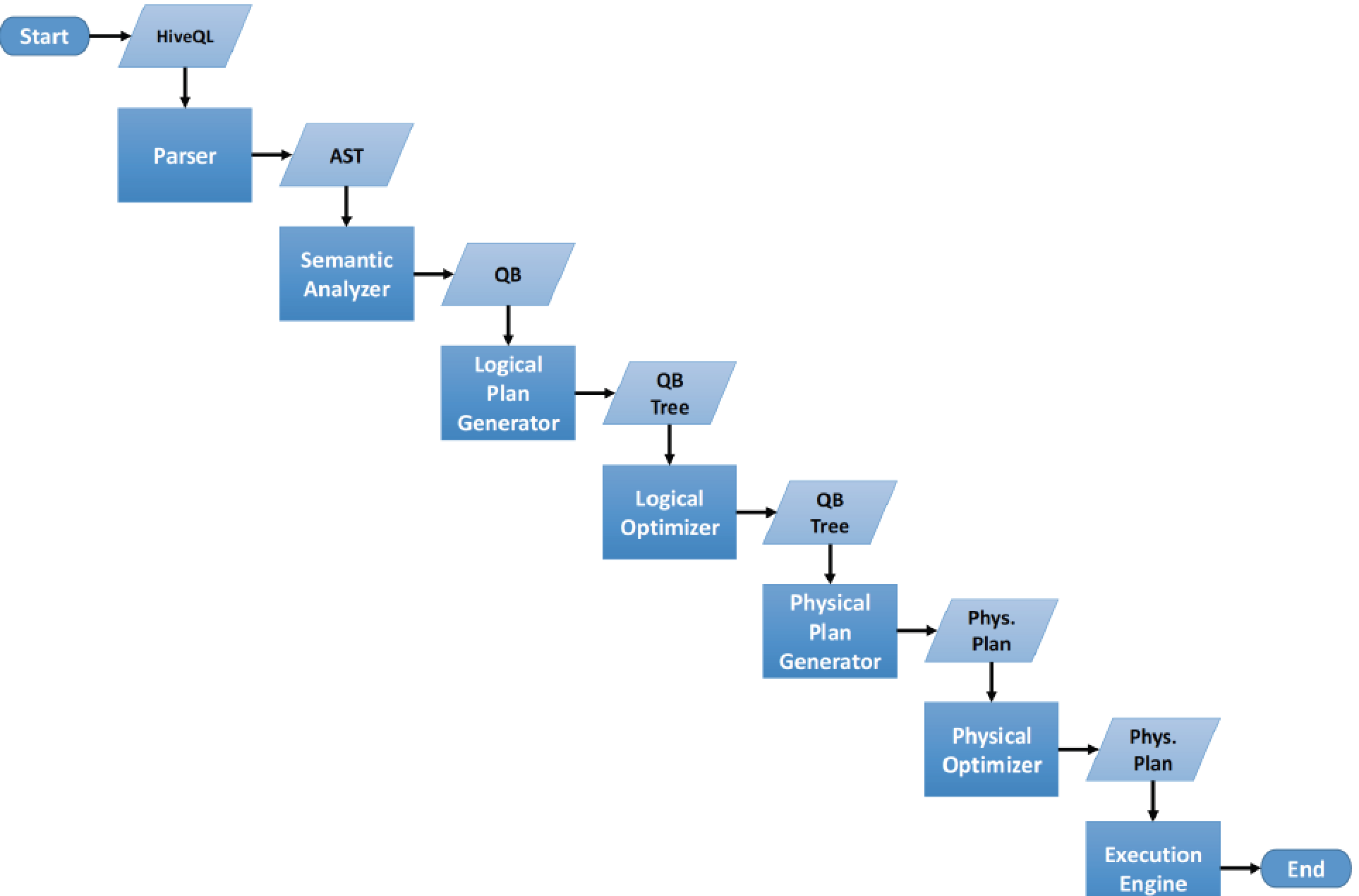
新版本的Hive也支持使用Tez或Spark作为执行引擎。
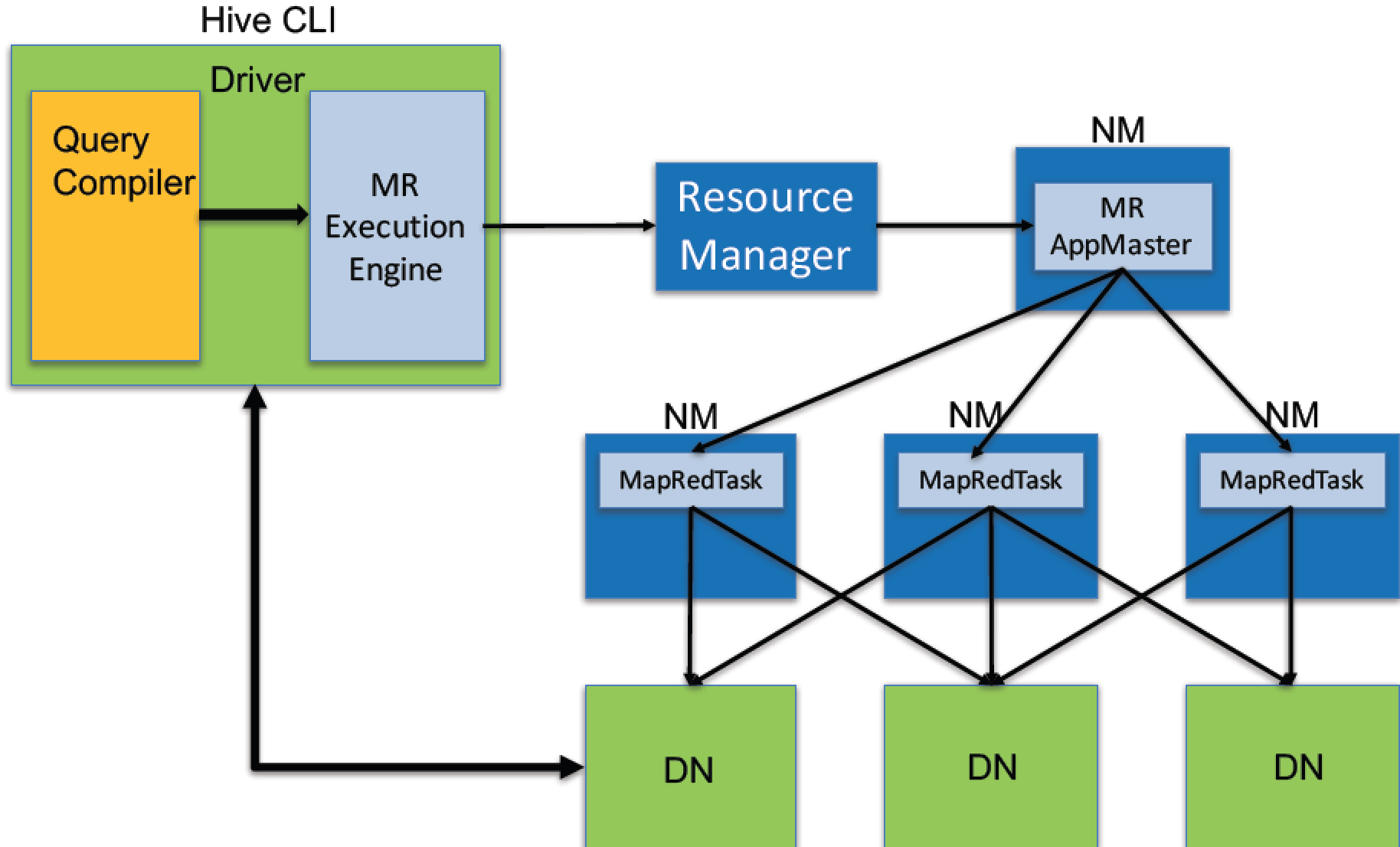

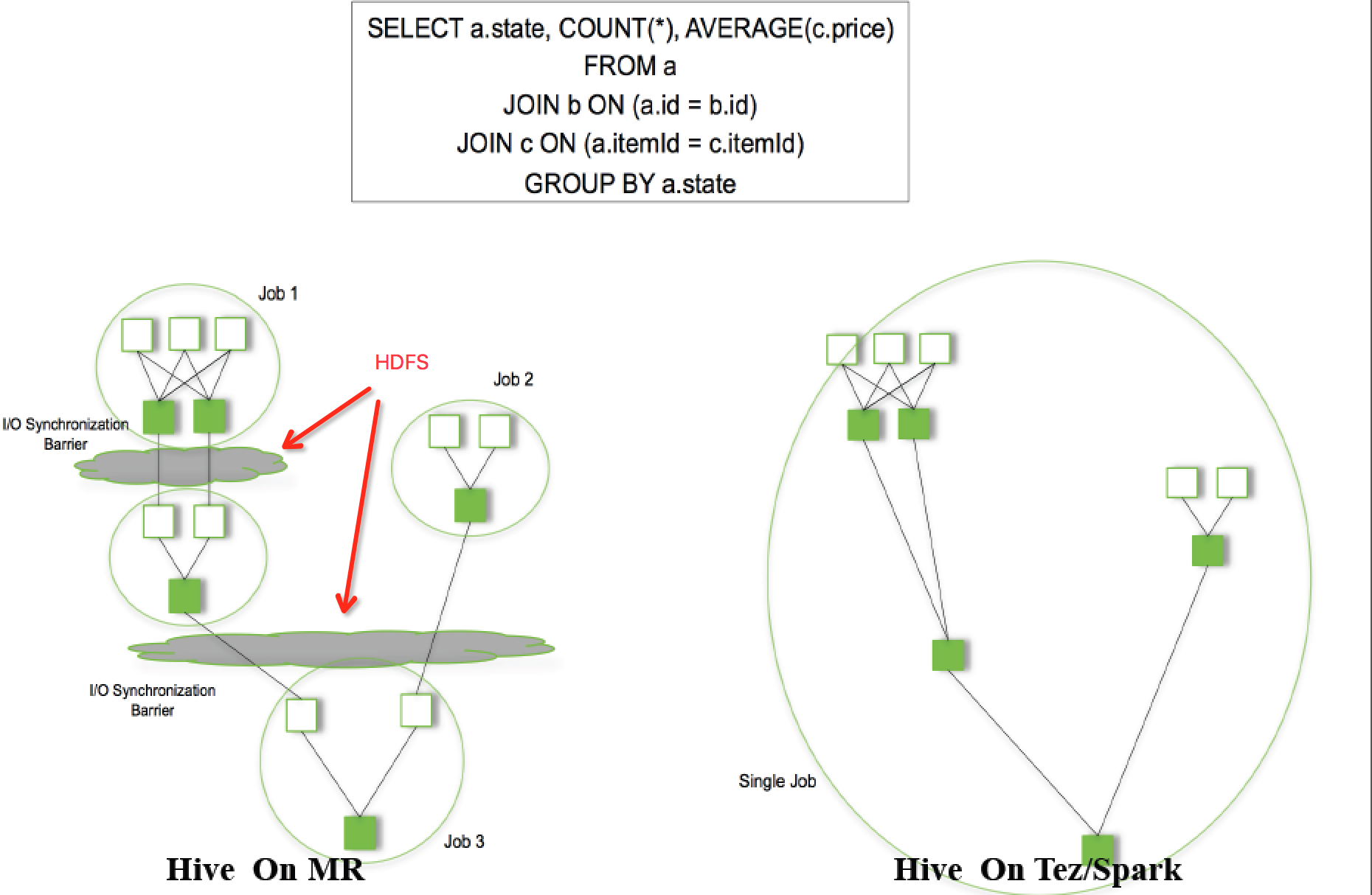
物理计划可以通过hive的Explain命令输出
例如:
: jdbc:hive2://master:10000/dbmfz> explain select count(*) from record_dimension;
+------------------------------------------------------------------------------------------------------+--+
| Explain |
+------------------------------------------------------------------------------------------------------+--+
| STAGE DEPENDENCIES: |
| Stage- is a root stage |
| Stage- depends on stages: Stage- |
| |
| STAGE PLANS: |
| Stage: Stage- |
| Map Reduce |
| Map Operator Tree: |
| TableScan |
| alias: record_dimension |
| Statistics: Num rows: Data size: Basic stats: COMPLETE Column stats: COMPLETE |
| Select Operator |
| Statistics: Num rows: Data size: Basic stats: COMPLETE Column stats: COMPLETE |
| Group By Operator |
| aggregations: count() |
| mode: hash |
| outputColumnNames: _col0 |
| Statistics: Num rows: Data size: Basic stats: COMPLETE Column stats: COMPLETE |
| Reduce Output Operator |
| sort order: |
| Statistics: Num rows: Data size: Basic stats: COMPLETE Column stats: COMPLETE |
| value expressions: _col0 (type: bigint) |
| Reduce Operator Tree: |
| Group By Operator |
| aggregations: count(VALUE._col0) |
| mode: mergepartial |
| outputColumnNames: _col0 |
| Statistics: Num rows: Data size: Basic stats: COMPLETE Column stats: COMPLETE |
| File Output Operator |
| compressed: false |
| Statistics: Num rows: Data size: Basic stats: COMPLETE Column stats: COMPLETE |
| table: |
| input format: org.apache.hadoop.mapred.SequenceFileInputFormat |
| output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat |
| serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe |
| |
| Stage: Stage- |
| Fetch Operator |
| limit: - |
| Processor Tree: |
| ListSink |
| |
+------------------------------------------------------------------------------------------------------+--+
rows selected (0.844 seconds)
除了DML,Hive也提供DDL来创建表的schema。
Hive数据存储支持HDFS的一些文件格式,比如CSV,Sequence File,Avro,RC File,ORC,Parquet。也支持访问HBase。
Hive提供一个CLI工具,类似Oracle的sqlplus,可以交互式执行sql,提供JDBC驱动作为Java的API。
转载请注明出处:
作者:mengfanzhu
原文链接:http://www.cnblogs.com/cnmenglang/p/6684615.html
大数据系列之数据仓库Hive原理的更多相关文章
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive中分区Partition如何使用
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 【大数据系列】apache hive 官方文档翻译
GettingStarted 开始 Created by Confluence Administrator, last modified by Lefty Leverenz on Jun 15, 20 ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列之并行计算引擎Spark介绍
相关博文:大数据系列之并行计算引擎Spark部署及应用 Spark: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. Spark是UC Berkeley AMP lab ( ...
- 大数据系列之分布式计算批处理引擎MapReduce实践
关于MR的工作原理不做过多叙述,本文将对MapReduce的实例WordCount(单词计数程序)做实践,从而理解MapReduce的工作机制. WordCount: 1.应用场景,在大量文件中存储了 ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
随机推荐
- STL 算法介绍
STL 算法介绍 算法概述 算法部分主要由头文件<algorithm>,<numeric>和<functional>组成. <algorithm ...
- AJAX实现无刷新登录
最近学习了如何实现无刷新登录,大体的效果如下(界面比较丑,请自行忽略....): 点击登录按钮时弹出登录窗口,输入正确的用户名密码后点击登录则登录窗口关闭,状态改为当前用户名. 第一步: 首先弹出窗口 ...
- NetApp常用巡检命令
常用检查命令 environment status 查看环境信息 version 查看OS版本 sysconfig -v 查看系统信息(设备序列号 系统软.硬件信息等) sysconfig -a 查看 ...
- Codeforces Educational Round 57
这场出题人好像特别喜欢998244353,每个题里都放一个 A.Find Divisible 考察选手对输入输出的掌握 输出l 2*l即可(为啥你要放这个题,凑字数吗 #include<cstd ...
- 解题:SCOI 2010 序列操作
题面 线段树......模板题(雾? 然而两种标记会互相影响,必须保证每次只放一个(不然就不知道怎么放了),具体的影响就是: 翻转标记会使得覆盖标记一起翻转,下放的时候就是各种swap 覆盖标记会抹掉 ...
- 【OpenCV】角点检测:Harris角点及Shi-Tomasi角点检测
角点 特征检测与匹配是Computer Vision 应用总重要的一部分,这需要寻找图像之间的特征建立对应关系.点,也就是图像中的特殊位置,是很常用的一类特征,点的局部特征也可以叫做“关键特征点”(k ...
- Linux系统之路Centos7.2——安装QQ 的一些问题(附VMware的安装)
1.首先安装wine 可以通过源码安装,注意在编译的时候加参数,编译64位(如果你的系统是64位哦!) 但是我建议直接rpm安装. 安装网络源: rpm -ivh epel-release-6-8.n ...
- servlet的application对象的使用
application对象 1 什么是application对象 ? (1) 当Web服务器启动时,Web服务器会自动创建一个application对象.application对象一旦创建,它将一直存 ...
- set.seed(7)什么意思
以前虽然在每个程序都看见过,但是没注意过这个问题,也不理解是什么意思,去搜了一些帖子才明白. 其实,很好理解,就是如果你不加set.seed(7),当然代码也可以执行这个命令,但是每次执行的结果都会不 ...
- Chapter2(变量和基础类型)--C++Prime笔记
数据类型选择的准则: ①当明确知晓数值不可能为负时,选用无符号类型. ②使用int执行整数运算.在实际应用中,short常常显得太小而long一般和int有一样的尺寸.如果运算范围超过int的表示范围 ...