Python pycharm(windows版本)部署spark环境
一 部署本地spark环境
解压下载的文件,假设解压 目录为:D:\Spark-1.6.0-bin-hadoop2.6。将D:\spark-1.6.0-bin-hadoop2.6\bin添加到系统Path变量,同时新建SPARK_HOME变量,变量值为:D:\spark-1.6.0-bin-hadoop2.6
1.3 Hadoop相关包的安装
spark是基于hadoop之上的,运行过程中会调用相关hadoop库,如果没配置相关hadoop运行环境,会提示相关出错信息,虽然也不影响运行。
去下载hadoop 2.6编译好的包https://www.barik.net/archive/2015/01/19/172716/,我下载的是hadoop-2.6.0.tar.gz,解压下载的文件夹,将相关库添加到系统Path变量中:D:\hadoop-2.6.0\bin;同时新建HADOOP_HOME变量,变量值为:D:\hadoop-2.6.0。同时去github上下载一个叫做 winutils 的组件,地址是 https://github.com/srccodes/hadoop-common-2.2.0-bin 如果没有hadoop对应的版本(此时版本是 2.6),则去csdn上下载 http://download.csdn.net/detail/luoyepiaoxin/8860033,
我的做法是把CSDN这个压缩包里的所有文件都复制到 hadoop_home的bin目录下
二 Python环境
Spark提供了2个交互式shell, 一个是pyspark(基于python), 一个是spark_shell(基于Scala). 这两个环境其实是并列的, 并没有相互依赖关系, 所以如果仅仅是使用pyspark交互环境, 而不使用spark-shell的话, 甚至连scala都不需要安装.
2.1 下载并安装Anaconda
anaconda是一个集成了python解释器和大多数python库的系统,安装anaconda 后可以不用再安装python和pandas numpy等这些组件了。下载地址是 https://www.continuum.io/downloads。将python加到path环境变量中
三 启动pyspark验证
在windows下命令行中启动pyspark,如图:


四 在pycharm中配置开发环境
4.1 配置Pycharm
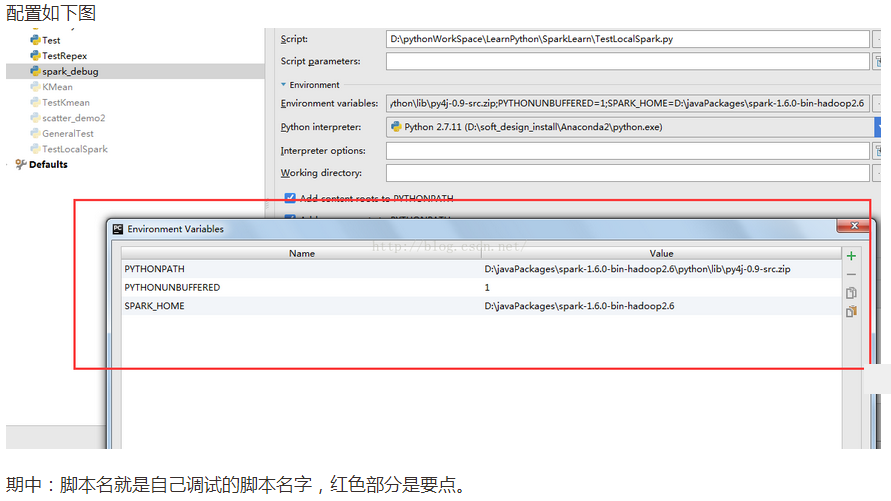
打开PyCharm,创建一个Project。然后选择“Run” ->“Edit Configurations”


SPARK_HOME:Spark安装目录
PYTHONPATH:Spark安装目录下的Python目录


4.2 测试程序
先测试环境是否正确,代码如下:
import os
import sys # Path for spark source folder
os.environ['SPARK_HOME']="D:\javaPackages\spark-1.6.0-bin-hadoop2.6" # Append pyspark to Python Path
sys.path.append("D:\javaPackages\spark-1.6.0-bin-hadoop2.6\python") try:
from pyspark import SparkContext
from pyspark import SparkConf print ("Successfully imported Spark Modules") except ImportError as e:
print ("Can not import Spark Modules", e)
sys.exit(1)


测试程序代码来源于 github :https://gist.github.com/bigaidream/40fe0f8267a80e7c9cf8
转原博客地址:http://blog.csdn.net/huangxia73/article/details/51372557
注意:
可能会报没有 py4j ( 它是python用来连接java的中间件)
可以用命令安装:pip install py4j
Python pycharm(windows版本)部署spark环境的更多相关文章
- 使用Vagrant在Windows下部署开发环境
做Web开发少不了要在本地搭建好开发环境,虽然说目前各种脚本都有对应的Windows版,甚至是一键安装包,但很多时候和Windows环境的相性并不是那么好,各麻烦的问题是实际部署的环境通常是Linux ...
- Windows下安装Spark环境
根据博客总结 https://blog.csdn.net/nxw_tsp/article/details/78281533 需要的安装软件可以在网盘下载: 链接:https://pan.baidu.c ...
- python+pycharm+selenium+谷歌浏览器驱动 自动化环境部署(一)
准备工作: 第一步:安装python.打开网址https://www.python.org/downloads/windows/ 现在最新版本3.7,本人使用的是3.6. 第二步:安装pych ...
- Python & PyCharm & Django 搭建web开发环境
一.安装软件 1.安装 Python 2.7.PyCharm.pip(Python包管理工具).Django ( pip install Django) 二.部署 1.PyCharm 新建Django ...
- windows 10 安装 spark 环境(spark 2.2.1 + hadoop2.7)
安装步骤基本参考 Spark在Windows下的环境搭建.不过在安装新版本 spark2.2.1(基于 hadoop2.7)的配置时,略略有一些不同. 1. sqlContext => spar ...
- Python & PyCharm & Django 搭建web开发环境(续)
由于Django自带轻量级的server,因此在前篇博文中,默认使用该server,但实际生产中是不允许这么干的,生产环境中通常使用Apache Httpd Server结合mod_wsgi.so来做 ...
- Scala,Java,Python 3种语言编写Spark WordCount示例
首先,我先定义一个文件,hello.txt,里面的内容如下: hello sparkhello hadoophello flinkhello storm Scala方式 scala版本是2.11.8. ...
- windows下搭建spark+python 开发环境
有时候我们会在windows 下开发spark程序,测试程序运行情况,再部署到真实服务器中运行. 那么本文介绍如何在windows 环境中搭建简单的基于hadoop 的spark 环境. 我的wind ...
- [转]windows环境下使用virtualenv对python进行多版本隔离
windows环境下使用virtualenv对python进行多版本隔离 最近在用python做一个文本的情感分析的项目,用到tensorflow,需要用python3的版本,之前因为<机器学习 ...
随机推荐
- Extjs gridPanel 动态指定表头
var colMArray = new Array(); colMArray = [{header : "产品代码", dataIndex : "cpdm", ...
- 转: LDAP有啥子用? 用户认证
认证的烦恼 小明的公司有很多IT系统, 比如邮箱.SVN.Jenkins , JIRA,VPN, WIFI...... 等等 . 新人入职时需要在每个系统中申请一遍账号,每个系统对用户名和密码的要求还 ...
- java使用POI获取sheet、行数、列数
FileInputStream inp = new FileInputStream("E:\\WEIAN.xls"); HSSFWorkbook wb = new HSSFWork ...
- Android图片加载框架最全解析(四),玩转Glide的回调与监听
大家好,今天我们继续学习Glide. 在上一篇文章当中,我带着大家一起深入探究了Glide的缓存机制,我们不光掌握了Glide缓存的使用方法,还通过源码分析对缓存的工作原理进行了了解.虽说上篇文章和本 ...
- 微软企业库Unity学习笔记
本文主要介绍: 关于Unity container配置,注册映射关系.类型,单实例.已存在对象和指出一些container的基本配置,这只是我关于Unity的学习心得和笔记,希望能够大家多交流相互学习 ...
- Java文件操作大全
//1.创建文件夹 //import java.io.*; File myFolderPath = new File(str1); try { if (!myFolderPath.exists()) ...
- 第二十四章 springboot注入servlet
问:有了springMVC,为什么还要用servlet?有了servlet3的注解,为什么还要使用ServletRegistrationBean注入的方式? 使用场景:在有些场景下,比如我们要使用hy ...
- 求两个数中的较大值max(a,b)。(不用if,>)
题目:求两个数的较大值,不能使用if.>. 1.不使用if.>,还要比较大小,貌似就只能使用条件表达式: x=<表达式1>?<表达式2>:<表达式3>; ...
- 访问者模式讨论篇:java的动态绑定与双分派
java的动态绑定 所谓的动态绑定就是指程执行期间(而不是在编译期间)判断所引用对象的实际类型,根据其实际的类型调用其相应的方法.java继承体系中的覆盖就是动态绑定的,看一下如下的代码: class ...
- 中国大学MOOC-陈越、何钦铭-数据结构-笔记
中国大学MOOC-陈越.何钦铭-数据结构-2017春 跟着<中国大学MOOC-陈越.何钦铭-数据结构-2017春>学习,平时练习一下pat上的作业外:在这里记录一下:平时学习视屏的收获. ...