Faster R-CNN 的 RPN 是啥子?
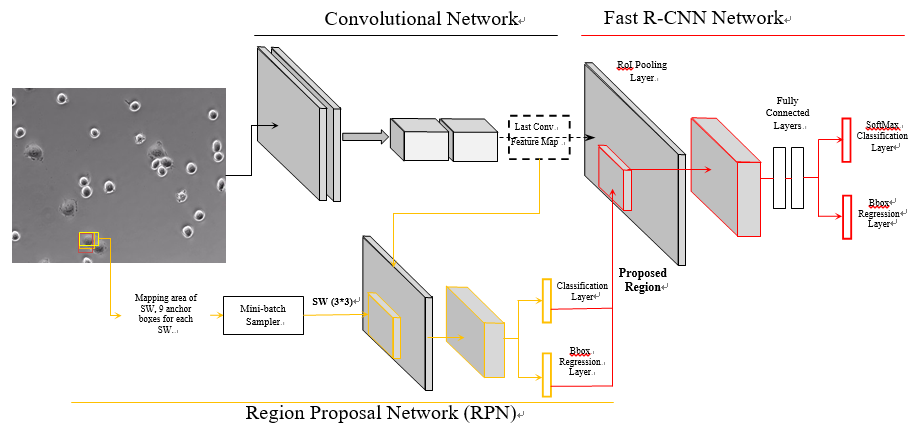 

Faster R-CNN,由两个模块组成:
第一个模块是深度全卷积网络 RPN,用于 region proposal;
第二个模块是Fast R-CNN检测器,它使用了RPN产生的region proposal进行物体检测。
通过将 region proposal 融入 CNN 网络中, 整个系统是一个单一的,统一的对象检测网络。 具体为使用 RPN 的技术代替之前 Selection Search, 完成 region proposal, 那么 RPN 需要完成两个任务:
- 判断 anchors 中是否包含将要检测的 K 类物体(是或者否), 这里只是判断是否包含物体, 而没有判断到底是什么物体, 即 objectness proposal
- 提出 anchor 对应的 bounding box 的坐标, 即 region proposal

下面不标明都是在说训练 RPN 的事!!!
下面不标明都是在说训练 RPN 的事!!!
下面不标明都是在说训练 RPN 的事!!!
那么就来具体看看 RPN 是什么?
Region Proposal Network
我对 RPN 网络的理解开始是只看最后 anchor 滑动 3x3卷积 + 2个1x1卷积层, 其实应该将之前所有卷积层算上才算是完整的 RPN, 以这种视角(把它当成一个单独的部分来看)来看 RPN, 输入输出就如下了,
输入: 整张图片
输出: objectness classification + bounding box regression
$ \color{red}{\bf来说说 RPN 中关键概念 \space anchor}$
anchor 其实就是预训练网络卷积层的最后一层 feature map 上的一个像素,以该 anchor 为中心,可以生成 k 种 anchor boxes(理解为 region proposal 就好了); 每个 anchor box 对应有一组缩放比例( scale)和宽高比(aspect). 论文中共使用 3 种 scale(128, 256, 512), 3 种 aspect(1:2, 1:1, 2:1), 所以每个 anchor 位置产生 9 个 anchor boxs.
 

为何要提出 anchor呢?
貌似与 GPU 的运算效率有关, 这个不懂了. 来说说 anchor 的优点: 它只依赖与单个 scale 的 images 和 feature map, 滑动窗口也只使用一个尺寸的 filter. 不过却能解决 multiple scales and sizes的问题.
为何选择 128 ,256, 512? 论文中用到的网络如 ZFNet 在最后一层卷积层的 feature map 上的一个像素的感受野就有 171, filter size 3x3, 3x171=513. 而且论文中提到: 我们的算法允许比底层接受域更大的预测。 这样的预测并非不可能 - 如果只有对象的中间部分是可见的,那么仍然可以大致推断出对象的范围。
在预训练网络卷积层的最后一层 feature map 上进行 3x3 的卷积, anchor 就位于卷积核的中心位置. 记住这里 anchor boxes 坐标对应的就是在图片上的坐标, 而不是在最后一层卷积层 feature map 上的坐标.
anchor box 这么简单粗暴, 为什么有效?
列举了这么多, 相当于穷举了吧, 比如论文中所说,由于最后一层的全局 stride 为16, 那么100x600 的图片就能生成大约 60x40x9≈20000个 anchor boxes). 当然列举了这么多 anchor boxes, 这region proposal 也太粗糙啊, 总不能就这样把这么多的质量层次不齐 anchor boxes 都送给 Fast R-CNN来检测吧. 那该怎么剔除质量不好的呢? 这就是后面 RPN 的 bounding box regression 和 objectness classification 要解决的事情:)
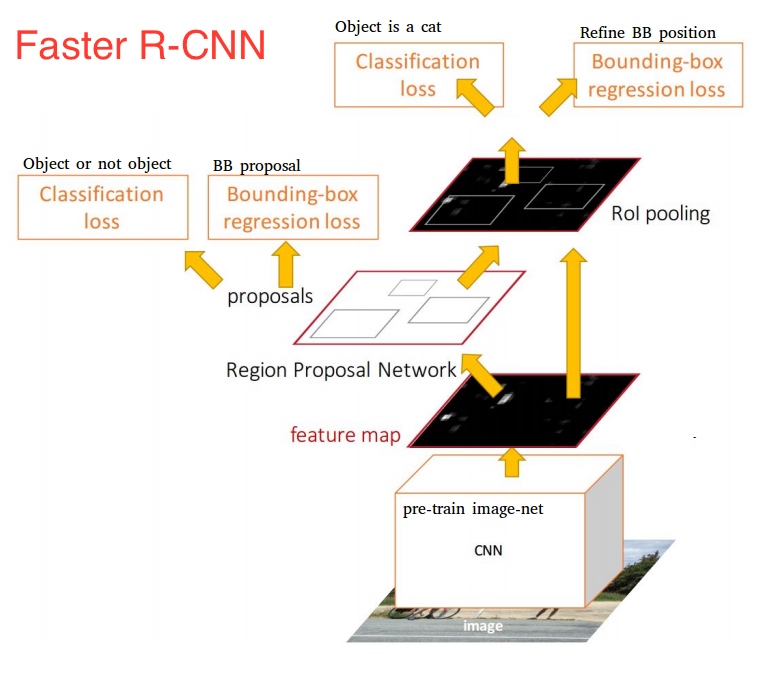
有必要先说说 RPN 的 objectness classification 和 bounding box regression 有什么用?
一句话就是 "少生优育"
bounding box regression: 调整输入的 anchor boxer 的坐标, 使它更接近真实值, 就是一个 bbox regression, 输出称为 RPN proposal, 或者 RoIs. 提高 anchor boxer 的质量
objectness classification: 一些 RPN proposal(anchor boxer经过)可能相互重叠度很高, 为了减少冗余, 通过objectness classification的输出的分数score 对这些RPN proposal做 NMS(non-maximum suppression), 论文中设置threshold 为 0.7, 只保留 threshold < 0.7 的RPN proposal, 减少 anchor boxes 的数量
RPN 的任务是什么?
训练 RPN 网络来选择那些比较好的 anchor boxes.
因为现在我们要训练 RPN, 我们只提出了 anchor boxer, 却不知道这些 anchor boxes是不是包含物体, 就是没有标签啊! 那么问题来了? objectness classification 分类时没有标签啊. 怎么办?
办法就是使用 image 检测用 gt-bbox(ground-truth bounding box), 注意这里我们只是检测图片中有没有物体, 而不判断是那类物体.
positive anchors: 与任意 gt-box 的 IoU > 0.7, 或者具有最大 IoU, 即标记为1, 就是包含物体, 当然该 gt-box 就是 anchor boxes bounding box regression任务对应的标签
negative anchors: 与任意 gt-box 的 IoU < 0.3, 即标记为 negative anchor, 标记为0, 就是不包含物体, 是背景, 从后面的损失函数知道, 背景不参与回归损失函数.
IoU 位于 positive anchors, negative anchors 之间 anchor boxer 背景和物体掺杂, 的对于训练目标没有贡献, 不使用.
bounding box regression && objectness classification
注意一点, 每个 regressor 只负责一个 , 不与它 regressor共享权重, 所以需要训练 k 个 regressor.
其他不多说, 只贴贴公式
 

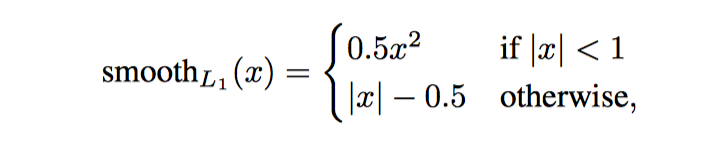 

 

- \(p^*_i\) 为一个 batch 中的第 i 个 anchor box 的真实标签, \(p_i\) 为分类器预测概率, 如果是positive anchor, \(P_i^*\)为1, 否则为0.
- $L_{reg}(t_i, t_i^) = smooth_{L1}(t_i-t_i^), $
- \(p^*_iL_{reg}\) 表示regression loss 只会被 positive anchor 激活.
- anchor boxes 的坐标表示为 (x, y, w ,h), (x, y) 为 box 的中心坐标.
- \(x,\space x_a, \space x^*\) 分别代表 bbox regressor 的预测坐标, anchor box 的坐标, 和 anchor box 对应的 gt-box 坐标.
训练
交替训练: 在这个解决方案中,我们首先训练 RPN,并使用这些 proposal 来训练 Fast R-CNN。 由 Fast R-CNN 调节的网络然后用于初始化 RPN,并且该过程被重复。
细节:
re-size image 最短边为 600 像素
total stride for ZFNet, VGGNet 16 pixels
跨图像边缘的 anchor boxes 处理
跨越图像边界的 anchor boxes 需要小心处理。 在训练期间,忽略了所有的跨界 anchor boxes,所以他们不会影响损失函数。 对于典型的1000×600图像,总共将有大约20000个(≈60×40×9)anchor boxes。 在忽略跨界锚点的情况下,每个图像有大约 6000 个 anchor boxes 用于训练。 如果跨界异常值在训练中不被忽略,它们会引入大的难以纠正误差项的,并且训练不会收敛。 然而,在测试过程中,我们仍然将完全卷积RPN应用于整个图像。 这可能会生成跨边界anchor boxes,我们将其剪切到图像边界(即将坐标限制在图片坐标内)。
一些实验总结
 

RPN+FRCN( ZFNet), mAP=59.9
RPN+FRCN( VGGNet), mAP=69.9
- Faster RCNN 使用 RPN 代替 SS 进行 region proposal, 极大的加快了检测速度, RPN 提出region proposal 的时间相比较 SS 来说,(1.5s -> 0.01s). 而且性能还要更好
- NMS 不会降低检测性能. 通过 NMS 得到 300 个 proposal的测试mAP为 55.1%, 使用top-ranked 6000个 proposal的mAP为 55.2%, 从而说明经过NMS之后的 top ranked proposal都是很精确的.
- 移除 RPN 的 classification(cls) 的话(自然没法做 NMS, NMS 就是依据cls 来做的), 当 proposal 很少时, 精确率下降很大, N = 100时, mAP 为44.6%, 这说明了cls 越高的 proposal 的准确性越高.
- 移除 RPN 的 bbox regression(reg)的话, mAP 下降到 52.1% 说明了多 scale, 多 aspect 的 anchor boxes 并不足以应对精确检测, regressed box bounds 可以产生高质量的 proposals
- 对于超参 scale, aspect 敏感性如下
 

预测过程
- 图片经过 RPN 产生anchor boxes
- anchor boxes 通过 bounding box regressor 调整位置
- 使用 objectness classification 分类器的打分进行 NMS, 减少数量
- 将 region proposal 交给 fast rcnn 检测.
Faster R-CNN 的 RPN 是啥子?的更多相关文章
- 论文阅读笔记三:R2CNN:Rotational Region CNN for Orientation Robust Scene Text Detection(CVPR2017)
进行文本的检测的学习,开始使用的是ctpn网络,由于ctpn只能检测水平的文字,而对场景图片中倾斜的文本无法进行很好的检测,故将网络换为RRCNN(全称如题).小白一枚,这里就将RRCNN的论文拿来拜 ...
- 目标检测(六)YOLOv2__YOLO9000: Better, Faster, Stronger
项目链接 Abstract 在该论文中,作者首先介绍了对YOLOv1检测系统的各种改进措施.改进后得到的模型被称为YOLOv2,它使用了一种新颖的多尺度训练方法,使得模型可以在不同尺寸的输入上运行,并 ...
- Object Detection: To Be Higher Accuracy and Faster
本系列文章由 @yhl_leo 出品,转载请注明出处. 文章链接: http://blog.csdn.net/yhl_leo/article/details/51597496 在深度学习中有一类研究热 ...
- R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN
最近在看 Mask R-CNN, 这个分割算法是基于 Faster R-CNN 的,决定看一下这个 R-CNN 系列论文,好好理一下 R-CNN 2014 1. 论文 Rich feature hie ...
- 深度学习目标检测:RCNN,Fast,Faster,YOLO,SSD比较
转载出处:http://blog.csdn.net/ikerpeng/article/details/54316814 知乎的图可以放大,更清晰,链接:https://www.zhihu.com/qu ...
- 第三节,目标检测---R-CNN网络系列
1.目标检测 检测图片中所有物体的 类别标签 位置(最小外接矩形/Bounding box) 区域卷积神经网络R-CNN 模块进化史 2.区域卷积神经网络R-CNN Region proposals+ ...
- 【AI in 美团】深度学习在OCR中的应用
AI(人工智能)技术已经广泛应用于美团的众多业务,从美团App到大众点评App,从外卖到打车出行,从旅游到婚庆亲子,美团数百名最优秀的算法工程师正致力于将AI技术应用于搜索.推荐.广告.风控.智能调度 ...
- DL for objection detection
在计算机视觉领域,"目标检测"主要解决两个问题:图像上多个目标物在哪里(位置),是什么(类别).围绕这个问题,人们一般把其发展历程分为3个阶段:1. 传统的目标检测方法2. 以R- ...
- CTPN网络理解
本文主要对常用的文本检测模型算法进行总结及分析,有的模型笔者切实run过,有的是通过论文及相关代码的分析,如有错误,请不吝指正. 一下进行各个模型的详细解析 CTPN 详解 代码链接:https:// ...
随机推荐
- [Luogu4074][WC2013]糖果公园
BZOJ权限题!提供洛谷链接 sol 树上带修改莫队 很显然吧.对吧. 所以说树上莫队要怎么写呢? 我们知道莫队=给区间排序+依次暴力处理,所以对于树上莫队而言也是一样的. 序列莫队基于序列分块(也就 ...
- [ZOJ3435]Ideal Puzzle Bobble
题面戳我 题意:你现在处于\((1,1,1)\),问可以看见多少个第一卦限的整点. 第一卦限:就是\((x,y,z)\)中\(x,y,z\)均为正 sol 首先L--,W--,H--,然后答案就变成了 ...
- 前端综合学习笔记---异步、ES6/7、Module、Promise同步 vs 异步
同步 vs 异步 先看下面的 demo,根据程序阅读起来表达的意思,应该是先打印100,1秒钟之后打印200,最后打印300.但是实际运行根本不是那么回事 console.log(100) setTi ...
- Kendo UI ASP.Net MVC 实现多图片及时显示加上传(其中有借鉴别人的代码,自己又精简了一下,如有冒犯,请多原谅!)
View: <div class="demo-section k-content"> @(Html.Kendo().Upload() .Name("files ...
- 34.Ajax
优先级 如果发送的是[普通数据] jQuery XMLHttpRequest iframe 如果发送的是[文件] iframe jQuery(FormData) XMLHttpRequest(Form ...
- 为什么覆写equals必须要覆写hashCode?
============================================= 原文链接: 为什么覆写equals必须要覆写hashCode? 转载请注明出处! ============= ...
- Database operations of Mysql
update 表名 set 字段名=replace(同一个字段名,原字符串,新字符串); --修改记录. 一.初始化 # cd /usr/local/mysql # chown -R mysql:m ...
- Java I/O 总结
Java I/O的的架构使用了装饰器的模式,我们在使用流的时候需要新建很多的装饰器对象,对源数据进行层层包装.各个包装类名以及它们的应用场景比较多,初学的时候难以摸清规律,这里我把它们归一下类,方便大 ...
- Algorithm --> 筛法求素数
一般的线性筛法 genPrime和genPrime2是筛法求素数的两种实现,一个思路,表示方法不同而已. #include<iostream> #include<math.h> ...
- ReflectASM-invoke,高效率java反射机制原理
前言:前段时间在设计公司基于netty的易用框架时,很多地方都用到了反射机制.反射的性能一直是大家有目共睹的诟病,相比于直接调用速度上差了很多.但是在很多地方,作为未知通用判断的时候,不得不调用反射类 ...