day-7 一个简单的决策树归纳算法(ID3)python编程实现
本文介绍如何利用决策树/判定树(decision tree)中决策树归纳算法(ID3)解决机器学习中的回归问题。文中介绍基于有监督的学习方式,如何利用年龄、收入、身份、收入、信用等级等特征值来判定用户是否购买电脑的行为,最后利用python和sklearn库实现了该应用。
1、 决策树归纳算法(ID3)实例介绍
2、 如何利用python实现决策树归纳算法(ID3)
1、决策树归纳算法(ID3)实例介绍
首先介绍下算法基本概念,判定树是一个类似于流程图的树结构:其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布。树的最顶层是根结点。
决策树的优点: 直观,便于理解,小规模数据集有效
决策树的缺点:处理连续变量不好,类别较多时,错误增加的比较快,可规模性一般
以如下测试数据为例:
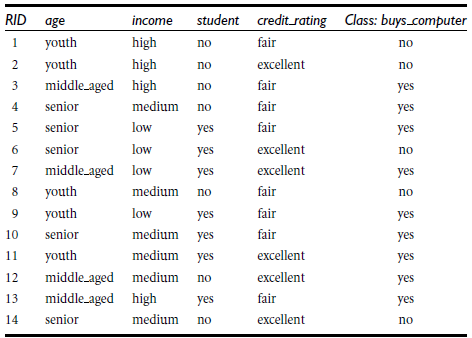
我们有一组已知训练集数据,显示用户购买电脑行为与各个特征值的关系,我们可以绘制出如下决策树图像(绘制方法后面介绍)
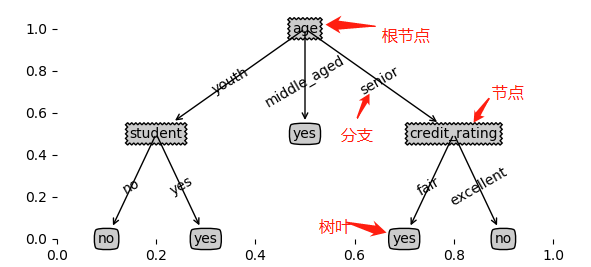
此时,输入一个新的测试数据,就能根据该决策树很容易判定出用户是否购买电脑的行为。
有两个关键点需要考虑:1、如何决定分支终止;2如何决定各个节点的位置,例如根节点如何确定。
1、如何决定分支终止
如果某个节点所有标签均为同一类,我们将不再继续绘制分支,直接标记结果。或者分支过深,可以基于少数服从多数的算法,终止该分支直接绘制结果。
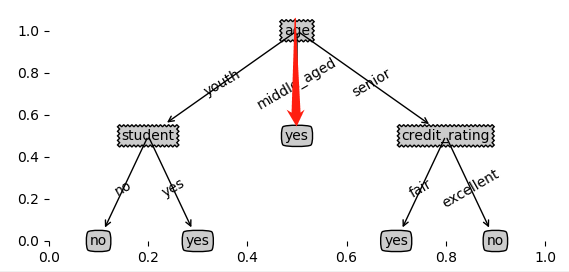
例如,通过年龄划分,所有middle_aged对象,对应的标签都为yes,尽管还有其它特征值,例如收入、身份、信用等级等,但由于标签所有都为一类,所以该分支直接标注结果为yes,不再往下细分。
2、如何决定各个节点的位置,例如根节点如何确定。
在说明这个问题之前,我们先讨论一个熵的概,信息和抽象,如何度量?1948年,香农提出了 “信息熵(entropy)”的概念,一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件非常非常不确定的事情,或者是我们一无所知的事情,需要了解大量信息==>信息量的度量就等于不确定性的多少
例子:猜世界杯冠军,假如一无所知,猜多少次?每个队夺冠的几率不是相等的,也就说明该信息熵较大。
当前样本集合 D 中第 k 类样本所占的比例为 pk ,则 D 的信息熵定义为
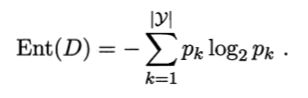
离散属性 a 有 V 个可能的取值 {a1,a2,…,aV};样本集合中,属性 a 上取值为 av 的样本集合,记为 Dv。用属性 a 对样本集 D 进行划分所获得的“信息增益”,表示得知属性 a 的信息而使得样本集合不确定度减少的程,公式如下:
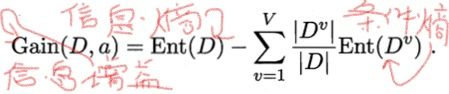
ID3算法首先计算各个特征向量的信息增益量,取最大的作为决策树的根,利用上面公式,以计算age年龄的信息增益量为例:

于是,我们选取age年龄作为决策树的根节点,依次画出最后的决策树,最后的算法如下:
- 树以代表训练样本的单个结点开始(步骤1)。
- 如果样本都在同一个类,则该结点成为树叶,并用该类标号(步骤2 和3)。
- 否则,算法使用称为信息增益的基于熵的度量作为启发信息,选择能够最好地将样本分类的属性(步骤6)。该属性成为该结点的“测试”或“判定”属性(步骤7)。在算法的该版本中,
- 所有的属性都是分类的,即离散值。连续属性必须离散化。
- 对测试属性的每个已知的值,创建一个分枝,并据此划分样本(步骤8-10)。
- 算法使用同样的过程,递归地形成每个划分上的样本判定树。一旦一个属性出现在一个结点上,就不必该结点的任何后代上考虑它(步骤13)。
- 递归划分步骤仅当下列条件之一成立停止:
- (a) 给定结点的所有样本属于同一类(步骤2 和3)。
- (b) 没有剩余属性可以用来进一步划分样本(步骤4)。在此情况下,使用多数表决(步骤5)。
- 这涉及将给定的结点转换成树叶,并用样本中的多数所在的类标记它。替换地,可以存放结
- 点样本的类分布。
- (c) 分枝
- test_attribute = a i 没有样本(步骤11)。在这种情况下,以 samples 中的多数类
- 创建一个树叶(步骤12)
除了ID3算法,还有一些其它算法可以用来绘制决策树,此处暂不讨论,例如:C4.5: Quinlan,Classification and Regression Trees (CART): (L. Breiman, J. Friedman, R. Olshen, C. Stone)。共同点:都是贪心算法,自上而下(Top-down approach)。区别:属性选择度量方法不同: C4.5 (gain ratio), CART(gini index), ID3 (Information Gain)
2、 如何利用python实现决策树归纳算法(ID3)
用Python实现上面实例前,我们需要先安装一个科学库Anaconda,anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。
同时,还需要安装一个决策树图形绘制工具graphviz
下面是具体的代码实现
# 导入库
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import tree
from sklearn import preprocessing
from sklearn.externals.six import StringIO
import math # 测试,没有age时的信息熵
result = -(5/14*math.log2(5/14) + 9/14*math.log2(9/14))
print(result) #测试,有age时的信息熵
result1 = 5/14*(-3/5*math.log2(3/5) - 2/5*math.log(2/5)) + 4/14*(-4/4*math.log2(4/4)) + 5/14*(-3/5*math.log2(3/5) - 2/5*math.log2(2/5))
print(result1) # 1 打开测试数据集
allElectronicsData = open(r'D:\test.csv','r')
reader = csv.reader(allElectronicsData)
# 读取文件头
headers = next(reader)
#print(headers) featureList = []
labelList = [] # 2 为每个测试样例,建立一个特征名和值的字典,然后加入到featureList中
for row in reader:
labelList.append(row[len(row) -1])
rowDict = {}
for i in range(1,len(row) -1):
rowDict[headers[i]] = row[i]
featureList.append(rowDict)
print(labelList)
print(featureList) # 3 把输入特征集进行转换,例如
'''
{'age': 'youth', 'income': 'high', 'student': 'no', 'credit_rating': 'fair'}
[ 0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
'''
vec = DictVectorizer()
dummyX = vec.fit_transform(featureList).toarray()
#print(type(dummyX))
print(dummyX)
#print(vec.get_feature_names()) # 4 对标签值进行0,1转换
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print(dummyY) # 5 直接调用库的决策树分类器,entropy表示信息熵
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = clf.fit(dummyX,dummyY)
#print(clf) # 6 填入feature_names,还原原有的值,写入test.dot文件
with open("test.dot",'w') as f:
f = tree.export_graphviz(clf,feature_names=vec.get_feature_names(),out_file=f) # 7 此时dumyX为一个n维的向量,取出第一行,修改一下作为一个新的测试数据
# 'age': 'middle_aged', 'income': 'high', 'student': 'no', 'credit_rating': 'fair' 正确结果应该是 买 为1
oneRowX = dummyX[0,:]
print("oneRowX: ",oneRowX)
newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print(newRowX) # 8 使用新数据进行测试验证
predictedY = clf.predict(newRowX.reshape(1, -1))
print(predictedY) # 使用graphviz工具,通过命令dot -Tpdf test.dot -o output.pdf生成决策树文档
day-7 一个简单的决策树归纳算法(ID3)python编程实现的更多相关文章
- 决策树归纳算法之ID3
学习是一个循序渐进的过程,我们首先来认识一下,什么是决策树.顾名思义,决策树就是拿来对一个事物做决策,作判断.那如何判断呢?凭什么判断呢?都是值得我们去思考的问题. 请看以下两个简单例子: 第一个例子 ...
- 实现一个简单的虚拟demo算法
假如现在你需要写一个像下面一样的表格的应用程序,这个表格可以根据不同的字段进行升序或者降序的展示. 这个应用程序看起来很简单,你可以想出好几种不同的方式来写.最容易想到的可能是,在你的 JavaScr ...
- 决策树归纳算法之C4.5
前面学习了ID3,知道了有关“熵”以及“信息增益”的概念之后. 今天,来学习一下C4.5.都说C4.5是ID3的改进版,那么,ID3到底哪些地方做的不好?C4.5又是如何改进的呢? 在此,引用一下前人 ...
- 决策树分类算法及python代码实现案例
决策树分类算法 1.概述 决策树(decision tree)——是一种被广泛使用的分类算法. 相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置 在实际应用中,对于探测式的知识发现 ...
- 实现一个简单的邮箱地址爬虫(python)
我经常收到关于email爬虫的问题.有迹象表明那些想从网页上抓取联系方式的人对这个问题很感兴趣.在这篇文章里,我想演示一下如何使用python实现一个简单的邮箱爬虫.这个爬虫很简单,但从这个例子中你可 ...
- 通过创建一个简单的骰子游戏来探究 Python
在我的这系列的第一篇文章 中, 我已经讲解如何使用 Python 创建一个简单的.基于文本的骰子游戏.这次,我将展示如何使用 Python 模块 Pygame 来创建一个图形化游戏.它将需要几篇文章才 ...
- 算法课上机实验(一个简单的GUI排序算法比较程序)
(在家里的电脑上Linux Deepin截的图,屏幕大一点的话,deepin用着还挺不错的说) 这个应该是大二的算法课程上机实验时做的一个小程序,也是我的第一个GUI小程序,实现什么的都记不清了,只记 ...
- 通过编写一个简单的漏洞扫描程序学习Python基本语句
今天开始读<Python绝技:运用Python成为顶级黑客>一书,第一章用一个小例子来讲解Python的基本语法和语句.主要学习的内容有:1. 安装第三方库.2. 变量.字符串.列表.词典 ...
- 一个简单的多机器人编队算法实现--PID
用PID进行领航跟随法机器人编队控制 课题2:多机器人编队控制研究对象:两轮差动的移动机器人或车式移动机器人研究内容:平坦地形,编队的保持和避障,以及避障和队形切换算法等:起伏地形,还要考虑地形情况对 ...
随机推荐
- linux系统连接的概念及删除原理
硬连接:ln 源文件 目标文件 软连接:ln -s 源文件 目标文件 (目标文件不能事先存在) 硬连接是通过索引节点inode来进行连接. 在Linux文件系统中,多个文件名指向同一个索引节点,硬连接 ...
- Adaboost的意义
Adaboost是广义上的提升方法(boosting method)的一个特例.广泛应用于人脸识别等领域. 它的基本思想是,“三个臭皮匠赛过诸葛亮”,即用多个弱分类器的线性加权,来得到一个强的分类器. ...
- 开发中使用mongoTemplate进行Aggregation聚合查询
笔记:使用mongo聚合查询(一开始根本没接触过mongo,一点一点慢慢的查资料完成了工作需求) 需求:在订单表中,根据buyerNick分组,统计每个buyerNick的电话.地址.支付总金额以及总 ...
- 如何使用Vue
我在学习前端框架的时候面临了很多的选择,比较流行的有react,angularJS,还有另外一个就是Vue,Vue相对于另外两个出现时间更晚,也更符合响应式(Reactive)组件化(Composab ...
- NancyFX 第九章 Responses(响应对象)
和内容协商最最为紧密的当属Nancy的Response对象. 在本书的第一张你应该就已经看到过Response对象,之前是使用它的AsFile 方法返回一个简单文件. using Nancy; nam ...
- css学习の第六弹—样式设置小技巧
一.css样式设置小技巧>>1.行内元素水平居中是通过给父元素设置 text-align:center 来实现的.html代码:<body> <div class=&qu ...
- 基于etcd的Rabbitmq队列订阅负载均衡
go-qb Load balancer for rabbitmq queue subscribing Feature Rabbitmq queue subscription load balancin ...
- python模板:自动化执行测试函数
#!/bin/python #example 1.1 #applay def function(a,b): print(a,b) def example1(): apply(function, (&q ...
- 设计模式——策略模式(C++实现)
程序优化是用于消除程序中大量的if else这种判断语句 #include <iostream> #include <string> using namespace std; ...
- pc端响应式-媒体查询
媒体查询(@media):能在不同的条件下使用不同的样式,使页面在不同在终端设备下达到不同的渲染效果 列举常用的pc屏幕宽度: 1024 1280 1366 1440 1680 1920 ...