网络爬虫BeautifulSoup库的使用
使用BeautifulSoup库提取HTML页面信息

#!/usr/bin/python3
import requests
from bs4 import BeautifulSoup url='http://python123.io/ws/demo.html'
r=requests.get(url)
if r.status_code==:
print('网络请求成功') demo=r.text
soup=BeautifulSoup(demo,'html.parser')
print(soup.prettify())
BeautifulSoup类的基本属性

#!/usr/bin/python3
import requests
from bs4 import BeautifulSoup url='http://python123.io/ws/demo.html'
r=requests.get(url)
if r.status_code==:
print('网络请求成功') demo=r.text
soup=BeautifulSoup(demo,'html.parser')
tag_title=soup.title
print(tag_title)
tag_a_attrs=soup.a.attrs
print(soup.p.string)
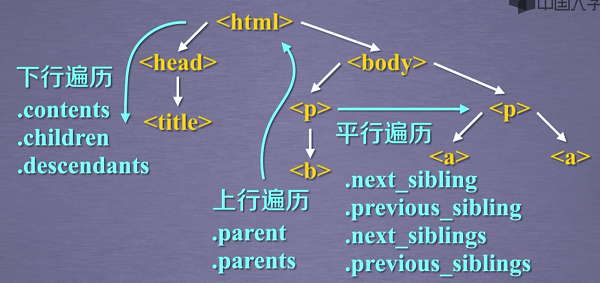
标签树的下行遍历
#!/usr/bin/python3
import requests
from bs4 import BeautifulSoup url='http://python123.io/ws/demo.html'
r=requests.get(url)
if r.status_code==200:
print('网络请求成功') demo=r.text
soup=BeautifulSoup(demo,'html.parser') print(soup.prettify())
print('我是分割线'.center(80,'-'))
#遍历子节点 for child in soup.body.children:
print(child)
#遍历子孙节点
for descendant in soup.body.descendants:
print(descendant)
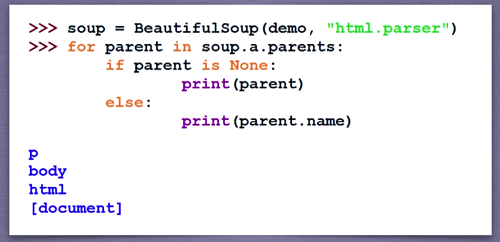
标签树的上行遍历

遍历title标签的上一级标签
print(soup.title.parent)
#a标签的下一标签
print(soup.a.next_sibling)
遍历a标签的所有前序节点以及后续节点
#遍历a标签的前序节点
for sibling in soup.a.next_siblings:
print(sibling)
#遍历a标签的前序节点
for sibling in soup.a.previous_siblings:
print(sibling)
soup标签的上一级标签为空,所以要进行判断
网络爬虫BeautifulSoup库的使用的更多相关文章
- Python爬虫-- BeautifulSoup库
BeautifulSoup库 beautifulsoup就是一个非常强大的工具,爬虫利器.一个灵活又方便的网页解析库,处理高效,支持多种解析器.利用它就不用编写正则表达式也能方便的实现网页信息的抓取 ...
- 2.03_01_Python网络爬虫urllib2库
一:urllib2库的基本使用 所谓网页抓取,就是把URL地址中指定的网络资源从网络流中抓取出来.在Python中有很多库可以用来抓取网页,我们先学习urllib2. urllib2 是 Python ...
- Python网络爬虫——BeautifulSoup4库的使用
使用requests库获取html页面并将其转换成字符串之后,需要进一步解析html页面格式,提取有用信息. BeautifulSoup4库,也被成为bs4库(后皆采用简写)用于解析和处理html和x ...
- [爬虫] BeautifulSoup库
Beautiful Soup库基础知识 Beautiful Soup库是解析xml和html的功能库.html.xml大都是一对一对的标签构成,所以Beautiful Soup库是解析.遍历.维护“标 ...
- python爬虫BeautifulSoup库class_
因为class是python的关键字,所以在写过滤的时候,应该是这样写: r = requests.get(web_url, headers=headers) # 向目标url地址发送get请求,返回 ...
- 网络爬虫--requests库中两个重要的对象
当我们使用resquests.get()时,返回的时response的对象,他包含服务器返回的所有信息,也包含请求的request的信息. 首先: response对象的属性有以下几个, r.stat ...
- 网络爬虫必备知识之urllib库
就库的范围,个人认为网络爬虫必备库知识包括urllib.requests.re.BeautifulSoup.concurrent.futures,接下来将结合爬虫示例分别对urllib库的使用方法进行 ...
- 网络爬虫必备知识之requests库
就库的范围,个人认为网络爬虫必备库知识包括urllib.requests.re.BeautifulSoup.concurrent.futures,接下来将结对requests库的使用方法进行总结 1. ...
- 网络爬虫必备知识之concurrent.futures库
就库的范围,个人认为网络爬虫必备库知识包括urllib.requests.re.BeautifulSoup.concurrent.futures,接下来将结对concurrent.futures库的使 ...
随机推荐
- Vue源码解析(二):数据驱动
一.数据驱动: 数据驱动是vue.js最大的特点.在vue.js中,数据驱动就是当数据发生变化的时候,用户界面发生相应的变化,开发者不需要手动的去修改dom.数据驱动还有一部分是数据更新驱动视图变化. ...
- Java开发笔记(八十九)缓存字节I/O流
文件输出流FileOutputStream跟FileWriter同样有个毛病,每次调用write方法都会直接写到磁盘,使得频繁的写操作性能极其低下.正如FileWriter搭上了缓存兄弟Buffere ...
- 学web前端的第一天
大家好,我是蓝颜.上次写博客是18年的4月份,不是不想写,是不知道怎么写,求写博客的技巧.从今天开始一天一更,不管写的怎么样,坚持的写下去.闲话不多说,第一次接触前端,什么都不懂,因为对这玩意的热爱, ...
- 全球第一免费开源ERP Odoo Ubuntu最佳开发环境独家首发分享
起源 近年来随着国内的互联网经济的快速腾飞,诞生了很多开源软件创造的市场价值以及企业价值神话,特别是对于企业ERP领域,一直以来都是高昂的国内外产品充实,国内的中小成长型企业越来越需要一套好看又能打, ...
- 常见dos命令行
查找本地端口占用情况 是否8080端口被占用netstat -aon|findstr "8080" 在1.txt文档当中查找java字符串type 1.txt|findstr 'j ...
- LOJ #6041. 「雅礼集训 2017 Day7」事情的相似度
我可以大喊一声这就是个套路题吗? 首先看到LCP问题,那么套路的想到SAM(SA的做法也有) LCP的长度是它们在parent树上的LCA(众所周知),所以我们考虑同时统计多个点之间的LCA对 树上问 ...
- nginx在Centos7.5下源码安装和配置
安装nginx 安装nginx依赖包 yum install -y pcre-devel zlib-devel openssl-devel wget gcc tree vim 进入目录/root/se ...
- ansible copy 模块的使用
copy copy 模块是将 ansible 管理主机上的文件拷贝上远程主机中,与 fetch 相反,如果目标路径不存在,则自动创建,如果 src 的目录带“/” 则复制该目录下的所有东西,如果 sr ...
- 网卡也能虚拟化?网卡虚拟化技术 macvlan 详解
本文首发于我的公众号 Linux云计算网络(id: cloud_dev),专注于干货分享,号内有 10T 书籍和视频资源,后台回复「1024」即可领取,欢迎大家关注,二维码文末可以扫. 01 macv ...
- Nginx安装与代理
1.第一步 - 添加Nginx存储库 要添加CentOS 7 EPEL存储库,请打开终端并使用以下命令: sudo yum install epel-release 2.第二步 - 安装Nginx 现 ...