网络爬虫BeautifulSoup库的使用
使用BeautifulSoup库提取HTML页面信息

#!/usr/bin/python3
import requests
from bs4 import BeautifulSoup url='http://python123.io/ws/demo.html'
r=requests.get(url)
if r.status_code==:
print('网络请求成功') demo=r.text
soup=BeautifulSoup(demo,'html.parser')
print(soup.prettify())
BeautifulSoup类的基本属性

#!/usr/bin/python3
import requests
from bs4 import BeautifulSoup url='http://python123.io/ws/demo.html'
r=requests.get(url)
if r.status_code==:
print('网络请求成功') demo=r.text
soup=BeautifulSoup(demo,'html.parser')
tag_title=soup.title
print(tag_title)
tag_a_attrs=soup.a.attrs
print(soup.p.string)
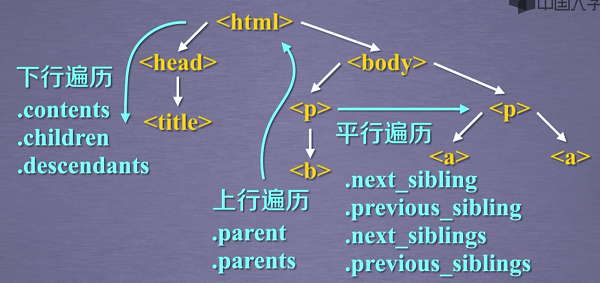
标签树的下行遍历
#!/usr/bin/python3
import requests
from bs4 import BeautifulSoup url='http://python123.io/ws/demo.html'
r=requests.get(url)
if r.status_code==200:
print('网络请求成功') demo=r.text
soup=BeautifulSoup(demo,'html.parser') print(soup.prettify())
print('我是分割线'.center(80,'-'))
#遍历子节点 for child in soup.body.children:
print(child)
#遍历子孙节点
for descendant in soup.body.descendants:
print(descendant)
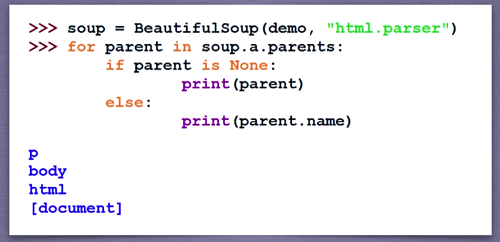
标签树的上行遍历

遍历title标签的上一级标签
print(soup.title.parent)
#a标签的下一标签
print(soup.a.next_sibling)
遍历a标签的所有前序节点以及后续节点
#遍历a标签的前序节点
for sibling in soup.a.next_siblings:
print(sibling)
#遍历a标签的前序节点
for sibling in soup.a.previous_siblings:
print(sibling)
soup标签的上一级标签为空,所以要进行判断
网络爬虫BeautifulSoup库的使用的更多相关文章
- Python爬虫-- BeautifulSoup库
BeautifulSoup库 beautifulsoup就是一个非常强大的工具,爬虫利器.一个灵活又方便的网页解析库,处理高效,支持多种解析器.利用它就不用编写正则表达式也能方便的实现网页信息的抓取 ...
- 2.03_01_Python网络爬虫urllib2库
一:urllib2库的基本使用 所谓网页抓取,就是把URL地址中指定的网络资源从网络流中抓取出来.在Python中有很多库可以用来抓取网页,我们先学习urllib2. urllib2 是 Python ...
- Python网络爬虫——BeautifulSoup4库的使用
使用requests库获取html页面并将其转换成字符串之后,需要进一步解析html页面格式,提取有用信息. BeautifulSoup4库,也被成为bs4库(后皆采用简写)用于解析和处理html和x ...
- [爬虫] BeautifulSoup库
Beautiful Soup库基础知识 Beautiful Soup库是解析xml和html的功能库.html.xml大都是一对一对的标签构成,所以Beautiful Soup库是解析.遍历.维护“标 ...
- python爬虫BeautifulSoup库class_
因为class是python的关键字,所以在写过滤的时候,应该是这样写: r = requests.get(web_url, headers=headers) # 向目标url地址发送get请求,返回 ...
- 网络爬虫--requests库中两个重要的对象
当我们使用resquests.get()时,返回的时response的对象,他包含服务器返回的所有信息,也包含请求的request的信息. 首先: response对象的属性有以下几个, r.stat ...
- 网络爬虫必备知识之urllib库
就库的范围,个人认为网络爬虫必备库知识包括urllib.requests.re.BeautifulSoup.concurrent.futures,接下来将结合爬虫示例分别对urllib库的使用方法进行 ...
- 网络爬虫必备知识之requests库
就库的范围,个人认为网络爬虫必备库知识包括urllib.requests.re.BeautifulSoup.concurrent.futures,接下来将结对requests库的使用方法进行总结 1. ...
- 网络爬虫必备知识之concurrent.futures库
就库的范围,个人认为网络爬虫必备库知识包括urllib.requests.re.BeautifulSoup.concurrent.futures,接下来将结对concurrent.futures库的使 ...
随机推荐
- SpringCloud-分布式链路跟踪配置详解
SpringCloud-分布式链路跟踪 作者 : Stanley 罗昊 [转载请注明出处和署名,谢谢!] 注:作者使用IDEA + Gradle 注:需要有一定的java SpringBoot and ...
- Asp.Net Core Web应用程序—探索
前言 作为一个Windows系统下的开发者,我对于Core的使用机会几乎为0,但是考虑到微软的战略规划,我觉得,Core还是有先了解起来的必要. 因为,目前微软已经搞出了两个框架了,一个是Net标准( ...
- PageHelper分页异常(java.base/java.util.ArrayList cannot be cast to com.github.pagehelper.Page)
在SqlMapConfig.xml里面配置分页插件 applicationContext-service.xml里面的配置,我出现问题谁因为,在salSessionFactory里没注入全局配置文件
- 从后台servlet中,获取jsp页面输入的值,来删除用户一行信息
后台servlet设置 protected void doPost(HttpServletRequest request, HttpServletResponse response) throws S ...
- python查询修改配置文件功能
阅读目录 一.python查询功能代码 1.查询修改配置文件 global log 127.0.0.1 local2 daemon maxconn 256 log 127.0.0.1 local2 i ...
- DNS服务详解
DNS服务 目录: 一.DNS原理 二.DNS服务的安装与配置 三.DNS信息收集 一.DNS原理 1.hosts文件与DNS服务器 1.1hosts文件 目录:C:\WINDOWS\system32 ...
- 免费申请使用IBM Cloud Lite(轻量套餐) 续
之前尝试申请了IBM的轻量套餐,过程很简单,操作起来也比较方便,就是能够用到的地方不多,虽说几乎是无限流量且永久免费,我能做的也只是做个小网站 免费用户默认的是轻量应用服务,如果需要功能更多更全的应用 ...
- Python写爬虫爬妹子
最近学完Python,写了几个爬虫练练手,网上的教程有很多,但是有的已经不能爬了,主要是网站经常改,可是爬虫还是有通用的思路的,即下载数据.解析数据.保存数据.下面一一来讲. 1.下载数据 首先打 ...
- 三种方式实现观察者模式 及 Spring中的事件编程模型
观察者模式可以说是众多设计模式中,最容易理解的设计模式之一了,观察者模式在Spring中也随处可见,面试的时候,面试官可能会问,嘿,你既然读过Spring源码,那你说说Spring中运用的设计模式吧, ...
- TabLayoutBottomDemo【TabLayout实现底部选项卡】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 使用TabLayout实现底部选项卡切换功能. 效果图 代码分析 1.演示固定模式的展现 2.演示自定义布局的实现 使用步骤 一.项 ...