大数据(2):基于sogou.500w.utf8数据hive的实践
一.环境的搭建
1.安装配置mysql
rpm –ivh MySQL-server-5.6.14.rpm
rpm –ivh MySQL-client-5.6.14.rpm
启动mysql
创建hive用户
grant all on *.* to hadoop@’%’ identified by ‘hadoop’;
grant all on *.* to hadoop@’localhost’ identified by ‘hadoop’;
grant all on *.* to hadoop@’master’ identified by ‘hadoop’;
创建hive数据库
create database hive_1;
2. hive的安装
tar –zxvf apache-hive-0.13-1-bin.tar.gz
3. hive的配置
vi /apache-hive-0.13-1-bin/conf/hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://master:3306/hive_1?characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name> <value>hadoop</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name> <value>hadoop</value>
</property>
</configuration>
4. tar -zxvf mysql-connector-java-5.1.27.tar.gz
5. 将java connector复制到依赖库中
cp mysql-connector-java-5.1.27-bin.jar ~/apache-hive-0.13-1-bin/lib/
6. 配置环境变量
vi .bash_profile
HIVE_HOME = /home/gdou/apache-hive-0.13-1-bin
PATH=$PATH:$HIVE_HOME/bin
二.搜狗日志数据分析
1. sogou.500w.utf8预处理
数据格式
访问时间\t 用户ID \t 关键词 \t 排名\t \页数 \t URL
2.查看数据
less sogou.500w.utf8
wc -l sogou.500w.utf8
head -100 sogou.500w.utf8 sogou.tmp
3. 数据扩展
将时间字段拆分并拼接,添加年 月 日 小时字段
bash sogou-log-extend.sh sogou.500w.utf8 sogou.500w.utf8.ext
4. 数据过滤
过滤第二字段UID和第三个字段关键字为空的行
bash sogou-log-filter.sh sogou.500w.utf8.ext sogou.500w.utf8 sogou.500w.utf8.flt
5.将文件sogou.500w.utf8和sogou.500w.utf8.flt上传至HDFS上。
6.HiveQL
基本操作
hive > show databases;
hive > create database sogou;
hive > use sogou;
hive > show tables;
hive > create external table sogou.sogou20111230(timestamp string, uid string, keyword string , rank int, order int, url string)
> comment 'this is a sogou table'
> row format delimited
> fields terminated by '\t'
> stored as textfile
> location 'hdfs://master:9000/sogou/20111230';
hive>show create table sogou.sogou20111230;
hive>describe sogou.sogou20111230;
hive> select * from sogou.sogou20111230 limit 3;
select count(*) from sogou.sogou20111230;
select count(distinct uid) from sogou.sogou20111230;
7.用hiveQL完成下列查询(写出HiveQL语句)
1)统计关键字非空查询的条数;
select count(*) from sogou.sogou20111230 where keyword is not null;
结果为:5000000
2)查询频度最高的前五十个关键字;
select keyword,count(keyword) as num from sogou.sogou20111230 group by keyword order by num desc limit 50;
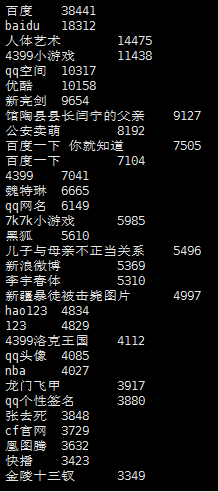
3)统计每个uid的平均查询次数
select avg(bb.num) from (select count(b.uid) as num from sogou.sogou20111230 b group by b.uid) as bb;

输出结果:3.69
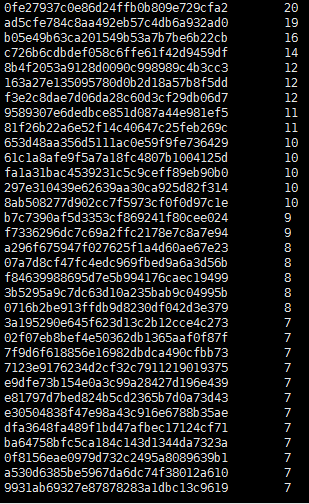
4)搜索关键字内容包含‘仙剑奇侠’超过三次的用户id
select tt.uid,tt.num from(select t.uid,count(t.uid) as num from (select * from sogou.sogou20111230 where keyword like concat('%','仙剑奇侠','%')) as t group by t.uid order by num desc) tt where tt.num > 3 limit 50;
输出结果:
5)查找直接输入URL作为关键字的条目;
select * from sogou.sogou20111230 where keyword rlike '[a-zA-z]+://[^\s]*' limit 50;

6)统计不重复的uid的行数;
select count(DISTINCT uid) from sogou.sogou20111230;
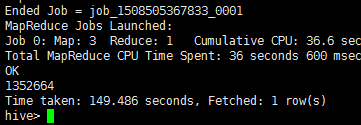
输出结果:1352664
相关资料:
链接:http://pan.baidu.com/s/1dFD7mdr 密码:xwu8
大数据(2):基于sogou.500w.utf8数据hive的实践的更多相关文章
- 大数据(3):基于sogou.500w.utf8数据Hbase和Spark实践
1. HBase安装部署操作 a) 解压HBase安装包tar –zxvf hbase-0.98.0-hadoop2-bin.tar.gzb) 修改环境变量 hbase-env.shexport JA ...
- 大数据(1):基于sogou.500w.utf8数据的MapReduce程序设计
环境:centos7+hadoop2.5.2 1.使用ECLIPS具打包运行WORDCOUNT实例,统计莎士比亚文集各单词计数(文件SHAKESPEARE.TXT). ①WorldCount.java ...
- 字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化
背景 字节跳动开发套件数据集成团队(DTS ,Data Transmission Service)在字节跳动内基于 Flink 实现了流批一体的数据集成服务.其中一个典型场景是 Kafka/ByteM ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- 大数据下基于Tensorflow框架的深度学习示例教程
近几年,信息时代的快速发展产生了海量数据,诞生了无数前沿的大数据技术与应用.在当今大数据时代的产业界,商业决策日益基于数据的分析作出.当数据膨胀到一定规模时,基于机器学习对海量复杂数据的分析更能产生较 ...
- 【T-BABY 夜谈大数据】基于内容的推荐算法
这个系列主要也是自己最近在研究大数据方向,所以边研究.开发也边整理相关的资料.网上的资料经常是碎片式的,如果要完整的看完可能需要同时看好几篇文章,所以我希望有兴趣的人能够更轻松和快速地学习相关的知识. ...
- SpringMVC + ehcache( ehcache-spring-annotations)基于注解的服务器端数据缓存
背景 声明,如果你不关心java缓存解决方案的全貌,只是急着解决问题,请略过背景部分. 在互联网应用中,由于并发量比传统的企业级应用会高出很多,所以处理大并发的问题就显得尤为重要.在硬件资源一定的情况 ...
- 基于IBM Bluemix的数据缓存应用实例
林炳文Evankaka原创作品.转载请注明出处http://blog.csdn.net/evankaka 摘要:IBM® Data Cache for Bluemix 是快速缓存服务.支持 Web 和 ...
- 使用C#处理基于比特流的数据
使用C#处理基于比特流的数据 0x00 起因 最近需要处理一些基于比特流的数据,计算机处理数据一般都是以byte(8bit)为单位的,使用BinaryReader读取的数据也是如此,即使读取bool型 ...
随机推荐
- 《HelloGitHub》第 23 期
公告 新的一年,不忘初心,从新开始.加油! <HelloGitHub>第 23 期 兴趣是最好的老师,HelloGitHub 就是帮你找到兴趣! 简介 分享 GitHub 上有趣.入门级的 ...
- Docker容器技术
Docker介绍 什么是容器 Linux容器是与系统其他部分隔离开的一系列进程,从另一个系统镜像运行,并由该镜像提供支持进程所需的全部文件. 容器镜像包含了应用的所有依赖项,因而在从开发到测试再到生产 ...
- 1.9 list 列表
列表是什么? list是Python中的基本数据结构之一,属于可变序列,所以前文中讲的可变序列的通用操作都适用于list. 这一节讲列表的特性吧. 特性一: 列表是包含任意对象的有序集合,同一个列表中 ...
- C#标识符
- spring cloud熔断监控Hystrix Dashboard和Turbine
参考: http://blog.csdn.net/ityouknow/article/details/72625646 完整pom <?xml version="1.0" e ...
- R语言数据框中,用0替代NA缺失值
1.用0替代数据框中的缺失值NA 生成数据框: > m <- matrix(sample(c(NA, :), , replace = TRUE), ) > d <- as.da ...
- openstack-ocata-计算服务4
一. 计算服务概览 使用OpenStack计算服务来托管和管理云计算系统.OpenStack计算服务是基础设施即服务(IaaS)系统的主要部分,模块主要由Python实现. OpenStack计算组件 ...
- openstack-ocata-环境准备1
Openstack环境准备1. 最少两台机器2. Controller:1核cpu 4G内存 5G硬盘3. Computer:1核cpu 2G内存 10G硬盘4. 至少两个网卡,本次采用四个网卡(1网 ...
- java编程思想第四版第六章习题
(略) (略) 创建两个包:debug和debugoff,他们都包含一个相同的类,该类有一个debug()方法,第一个版本显示发送给控制台的String参数,而第二版本什么也不做,使用静态import ...
- JavaScript split()函数
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...