MySQL 并行复制从库发生自动重启分析
背景
半同步复制从库在晚上凌晨2点半发生异常crash,另一个异步复制从库在第二天凌晨3点也发生了异常crash。
版本
mysql 5.7.16
redhat 6.8
mysql> show variables like '%slave_para%';
+------------------------+---------------+
| Variable_name | Value |
+------------------------+---------------+
| slave_parallel_type | LOGICAL_CLOCK |
| slave_parallel_workers | 16 |
+------------------------+---------------+
分析
mysqld服务在以mysqld_safe守护进程启动的情况下,在发生mysqld异常情况(比如OOM)会自动拉起mysqld服务,但已确认两个从库实例messages中无与OOM相关的日志。
从监控中发现,两个从库与Seconds_Behind_Master没有很高的异常上升。
参数slave_pending_jobs_size_max 在多线程复制时,在队列中Pending的事件所占用的最大内存,默认为16M,如果内存富余,或者延迟较大时,可以适当调大;注意这个值要比主库的max_allowed_packet大。
参考官方文档:slave_pending_jobs_size_max两个发生异常crash的从库日志中都出现了ibuf record inserted to page x:x ,通过查看space_id发现都是对应的同一张表(a_xxx.join_acct_flow),疑是晚上的定时任务对这张表做了大事务的操作。从库的并行复制只有对并发提交的事务才会进行并行应用,对一个大事务,只有一个线程进行应用。

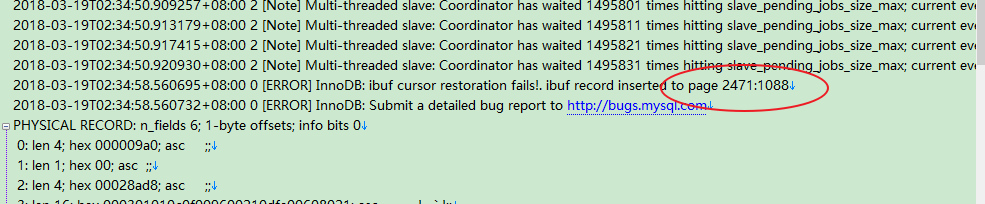
分析在从库发生异常crash的时间段里发现,产生了大事务
mysqlbinlog -v -v --base64-output=decode-rows
--start-datetime='2018-04-03 02:47:22' --stop-datetime='2018-04-03 02:48:26' /data/mysql/mysql-bin.003446 | awk
'/###/{if($0~/UPDATE|INSERT|DELETE/)count[$2""$NF]++}END{for(i in
count)print i,"\t",count[i]}' | column -t | sort -k3nr | more
DELETE`a_xxx`.`xxx_acct_flow` 565330
DELETE`a_xxx`.`xxx_bfj_flow` 23595
DELETE`a_xxx`.`xxx_loan_detail` 24156
DELETE`a_xxx`.`xxx_pay_log` 18475
INSERT`a_xxx`.`xxx_acct_flow_his` 576265
INSERT`a_xxx`.`xxx_bfj_flow_his` 23829
INSERT`a_xxx`.`xxx_loan_detail_his` 24539
INSERT`a_xxx`.`xxx_pay_log_his` 18709
- 向看源码的朋友请教了下,得到了MySQL异常crash的Stack Trace
获取内存地址放入/tmp/err.log 中
[0xf1dff5]
[0x79d3b4]
[0x358c00f7e0]
[0x358bc325e5]
[0x358bc33dc5]
[0x1159d65]
[0x115e8b3]
[0x102b4d1]
[0x102f531]
[0x1033b29]
[0x11a59a1]
[0x1200afb]
[0x110db48]
[0x358c007aa1]
[0x358bce8aad]
nm -D -n /usr/local/mysql/bin/mysqld>/tmp/mysqld.sym
resolve_stack_dump -s /tmp/mysqld.sym -n /tmp/err.log |c++filt | less
0xf1dff5 my_print_stacktrace + 53
0x79d3b4 handle_fatal_signal + 1188
0x358c00f7e0 _end + -1978652160
0x358bc325e5 _end + -1982703611
0x358bc33dc5 _end + -1982697499
0x1159d65 ut_dbg_assertion_failed(char const*, char const*, unsigned long) + 170
0x115e8b3 ib::fatal::~fatal() + 179
0x102b4d1 ibuf_print(_IO_FILE*) + 881
0x102f531 ibuf_update_free_bits_low(buf_block_t const*, unsigned long, mtr_t*) + 3905
0x1033b29 ibuf_merge_or_delete_for_page(buf_block_t*, page_id_t const&, page_size_t const*, unsigned long) + 2825
0x11a59a1 buf_page_io_complete(buf_page_t*, bool) + 1249
0x1200afb fil_aio_wait(unsigned long) + 347
0x110db48 io_handler_thread + 200
0x358c007aa1 _end + -1978684223
0x358bce8aad _end + -1981956915
- 可见,在mysqld发生异常crash时的内部函数是ibuf_update_free_bits_low,ibuf_merge_or_delete_for_page(在做change buffer的merge操作
- 貌似是由于主实例执行了delete大事务,从实例多线程进行apply(change buffer merge)出现的问题导致mysqld发生crash?
测试
主库模拟一个大事务,看从库是否有异常出现
环境
centos 7.4
mysql5.7.19
从库并行复制线程 8
从库slave_pending_jobs_size_max 设置比主库 max_allowed_packet大
主库
mysql> desc sbtest1;
+-----+-----------+-----+-----+------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| k | int(11) | NO | MUL | 0 | |
| c | char(120) | NO | | | |
| pad | char(60) | NO | | | |
| id3 | int(11) | YES | | NULL | |
| id5 | int(11) | YES | | NULL | |
+-----+-----------+-----+-----+------+----------------+
select count(*) from sbtest1;
mysql> show variables like 'max_allowed_packet%';
+--------------------+----------+
| max_allowed_packet | 16777216 | 16M
+--------------------+----------+
从库
mysql> show variables like '%slave_para%';
+------------------------+---------------+
| Variable_name | Value |
+------------------------+---------------+
| slave_parallel_type | LOGICAL_CLOCK |
| slave_parallel_workers | 8 |
+------------------------+---------------+
mysql> show variables like '%slave_pending_jobs%';
+-----------------------------+----------+
| Variable_name | Value |
+-----------------------------+----------+
| slave_pending_jobs_size_max | 67108864 | 64M
+-----------------------------+----------+
主库执行
UPDATE sbtest1 SET c=REPEAT(UUID(),2) where id<100000;
从库出现大量类似生产环境中的日志,但没有模拟出从库异常crash的情况
Note] Multi-threaded slave: Coordinator has waited 208341 times hitting slave_pending_jobs_size_max; current event size = 8044
Note] Multi-threaded slave: Coordinator has waited 208351 times hitting slave_pending_jobs_size_max; current event size = 8044
Note] Multi-threaded slave: Coordinator has waited 208361 times hitting slave_pending_jobs_size_max; current event size = 8044
Note] Multi-threaded slave: Coordinator has waited 208371 times hitting slave_pending_jobs_size_max; current event size = 8044
Note] Multi-threaded slave: Coordinator has waited 208381 times hitting slave_pending_jobs_size_max; current event
结论
从库开启并行复制,主库执行大事务,从库日志会出现大量中 Coordinator has waited。但没有复现出从库发生异常crash的情况。
建议:
- 尽量减少大事务的执行,拆分为小事务
- 从库slave_pending_jobs_size_max 变量设置比主库max_allowed_packet大些
- 可设置binlog_rows_query_log_events = 1(可以动态开启),DDL,DML会以语句形式在binlog中记录,方便分析binlog
- crash问题后续可以多保留一些日志,再次复现时好分析些
- 已给官方提了bug了,链接地址为 http://bugs.mysql.com/90342
参考:
http://blog.itpub.net/7728585/viewspace-2151173/
MySQL 并行复制从库发生自动重启分析的更多相关文章
- MySQL 并行复制演进及 MySQL 8.0 中基于 WriteSet 的优化
MySQL 8.0 可以说是MySQL发展历史上里程碑式的一个版本,包括了多个重大更新,目前 Generally Available 版本已经已经发布,正式版本即将发布,在此将介绍8.0版本中引入的一 ...
- mysql并行复制降低主从同步延时的思路与启示
一.缘起 mysql主从复制,读写分离是互联网用的非常多的mysql架构,主从复制最令人诟病的地方就是,在数据量较大并发量较大的场景下,主从延时会比较严重. 为什么mysql主从延时这么大? 回答:从 ...
- [转载自阿里丁奇]各版本MySQL并行复制的实现及优缺点
MySQL并行复制已经是老生常谈,笔者从2010年开始就着手处理线上这个问题,刚开始两三年也乐此不疲分享,现在再提这个话题本来是难免"炒冷饭"嫌疑. 最近触发再谈这个话题,是 ...
- 各版本 MySQL 并行复制的实现及优缺点
MySQL并行复制已经是老生常谈,笔者从2010年开始就着手处理线上这个问题,刚开始两三年也乐此不疲分享,现在再提这个话题本来是难免“炒冷饭”嫌疑. 最近触发再谈这个话题,是因为有些同学觉得“5.7的 ...
- 【58沈剑架构系列】mysql并行复制优化思路
一.缘起 mysql主从复制,读写分离是互联网用的非常多的mysql架构,主从复制最令人诟病的地方就是,在数据量较大并发量较大的场景下,主从延时会比较严重. 为什么mysql主从延时这么大? 回答:从 ...
- InnoSQL/MySQL并行复制的实现与配置
InnoSQL/MySQL并行复制的实现与配置 http://www.innomysql.net/article/6276.html 并行复制之前的解决方案 InnoSQL在5.5.30-v4版本中支 ...
- dell PowerEdge R720 自动重启分析
dell PowerEdge R720 自动重启分析 摘要: 一,问题描述: 在同一批服务器当中,碰到这样一台服务器,如果不跑任何服务时没有问题,但一跑任务就是自动重启.既然同样的系统别的服务器都没出 ...
- MySQL 并行复制(MTS) 从库更新的记录不存在实际却存在
目录 背景 版本 分析 测试 背景 开了并行复制的半同步从库SQL 线程报1032错误,异步复制从库没有报错,偶尔会出现这种 版本 mysql 5.7.16 redhat 6.8 mysql> ...
- MySQL并行复制的一个坑
早上巡检数据库,发现一个延迟从库的sql_thread中断了. Last_SQL_Errno: 1755 Last_SQL_Error: Cannot execute the current even ...
随机推荐
- wipefs进程
wipefs进程是啥,占用了百分之90多的cpu wipefs进程是啥,占用了百分之90多的cpu,把这个进程干掉了,过了一天又自动启动了,很多朋友应该遇到过类似的问题. wipefs是linux自带 ...
- Android Service基础
Service Service 是一个组件,用来执行长时间的后台操作,不提供用户界面. 另一个应用组件可以启动一个Service,它将持续地在后台运行,即便是用户转移到另一个应用它也不会停止. 另外, ...
- Django+xadmin打造在线教育平台(八)
十一.用户信息 11.1.个人信息展示 (1)新建‘usercenter-bae.html’当母板 {% load staticfiles %} <!DOCTYPE html> <h ...
- JaveScript对象(JS知识点归纳七)
1.JS中的对象表示的是一个具体的事物. a)静态的特征=>对象的属性 b)动态的行为=>对象的方法=>保存的值==>函数 2.对象的创建方式 a)构造函数的创建方式 ``` ...
- machine learning 之 多元线性回归
整理自Andrew Ng的machine learning课程 week2. 目录: 多元线性回归 Multivariates linear regression /MLR Gradient desc ...
- Beta冲刺第七天
一.昨天的困难 没有困难. 二.今天进度 1.林洋洋:MD图片上传,修复权限问题,修复本地存储判空问题,修复协作申请没有过滤问题. 2.黄腾达:添加文件链接和邀请链接复制功能,协作树界面优化. 3.张 ...
- 第一部分 linux系统命令
一.linux系统命令 pwd 当前目录位置 / 根目录 cd (change direcory) cd ..返回上一层目录 ls 显示当前目录下文件 ls -l 显示目录下详细文件信息 ls -lh ...
- Xen Server虚拟机数据恢复的方法和数据恢复过程
在服务器运行过程中如果出现意外情况突然断电很容易引起服务器故障,服务器中的硬件设备损坏可以修复或者购买,但是服务器中的数据一旦发生故障丢失,对于企业来说将是不可估量的损失.那么服务器数据一旦丢失就除了 ...
- List集合就这么简单【源码剖析】
前言 声明,本文用得是jdk1.8 前一篇已经讲了Collection的总览:Collection总览,介绍了一些基础知识. 现在这篇主要讲List集合的三个子类: ArrayList 底层数据结构是 ...
- Angular组件——组件生命周期(二)
一.view钩子 view钩子有2个,ngAfterViewInit和ngAfterViewChecked钩子. 1.实现ngAfterViewInit和ngAfterViewChecked钩子时注意 ...