第1节 kafka消息队列:2、kafka的架构介绍以及基本组件模型介绍
3、kafka的架构模型
1、producer:消息的生产者,主要是用于生产消息的。主要是接入一些外部的数据源,从外部获取数据,比如说我们可以从flume获取数据,还可以通过ftp传入数据等,还可以通过kafka的API生产数据,通过push的方式,主动的将数据推送到kafka的topic当中去
2、topic:主题,里面是一类消息的抽象的集合,说白了这下面就是用来装各种数据的
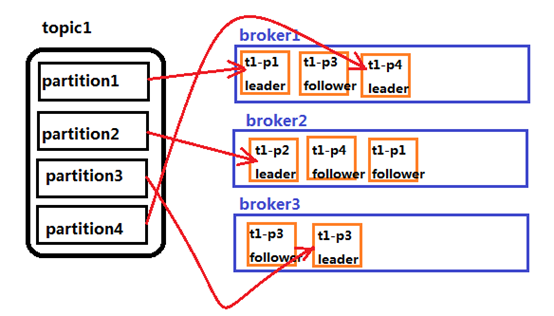
3、paritition:消息的分区。为了解决数据保存的横向扩展的问题,所以将一个topic分为多个partition,每个partition保存topic当中的部分部署。为了解决partition丢失的问题,引入了副本机制,可以将一个partition复制多分出来保存
4、broker:在kafka当中一台服务器,叫做一个broker
5、consumer:消息的消费者,主要去消费topic当中的数据的,主动会去pull拉取topic当中的消息
6、zookeeper:为了解决消费者消费的时候,确定一个topic当中有多少个分区,分区分别都在哪一台机器上,引入zk来保存这些数据
7、kakfa的消费模型,在kakfa当中消费有组的概念。同一时间,一个组当中,只能有一个线程去消费一个paritition当中的数据
8、kakfa消费必要的三个条件
第一个条件:确定哪一个topic
第二个条件:必须知道zk的地址
第三个条件:消息消费的offset偏移量
4、kafka的组件的介绍
produer:消息的生产者,往topic当中生产消息
consumer:消息的消费者,从topic当中消费消息
broker:kafka的服务器
zookeeper:kafka依赖于zk保存一些topic以及partition的信息
topic:一类消息的高度抽象集合,一个topic下面由多个paritition组成
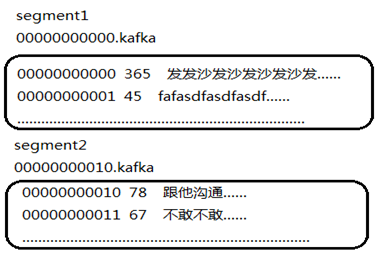
partition:消息的分区,每个paritition保存了一部分topic的数据,一个partition包含多个segement。一个segement又包含两部分,.log文件和.index文件
segement:包含两个文件.log 文件 .index文件
.log:记录了我们的数据,文件是顺序读写的
.index文件:记录了.log文件的索引
offset:消息的偏移量,我们消费数据的时候,都要记录消息的offset,下次继续消费的时候,根据上次的offset偏移量就可以确定我们下一条数据从哪里开始消费
===============================
1、 kafka的架构模型
基于producer consumer topic broker 等的一个基本架构

5、kafka的组件介绍
Topic :消息根据Topic进行归类
Producer:发送消息者
Consumer:消息接受者
broker:每个kafka实例(server)
Zookeeper:依赖集群保存meta信息。
Topics组件介绍
Topic:一类消息,每个topic将被分成多个partition(区),在集群的配置文件中配置。
partition:在存储层面是逻辑append log文件,包含多个segment文件。
Segment:消息存储的真实文件,会不断生成新的。
offset:每条消息在文件中的位置(偏移量)。offset为一个long型数字,它是唯一标记一条消息。
partition
1、 在存储层面是逻辑append log文件,每个partition有多个segment组成。
2、 任何发布到此partition的消息都会被直接追加到log文件的尾部。
3、 每个partition在内存中对应一个index列表,记录每个segment中的第一条消息偏移。这样查找消息的时候,先在index列表中定位消息位置,再读取文件,速度块。
4、 发布者发到某个topic的消息会被均匀的分布到多个part上,broker收到发布消息往对应part的最后一个segment上添加该消息。
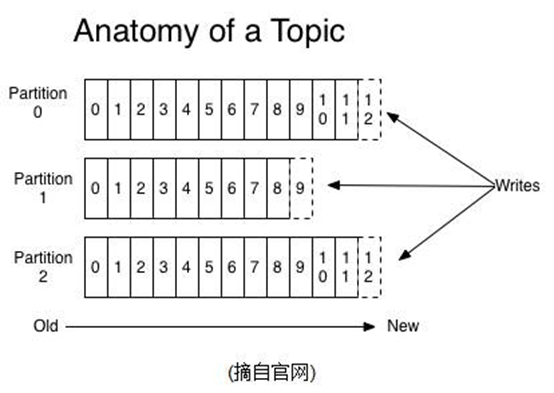
partition分布
1、 partitions分区到不同的server上,一个partition保存在一个server上,避免一个server上的文件过大,同时可以容纳更多的consumer消费,有效提升并发消费的能力。
2、 这个server(如果保存的是partition的leader)负责partition的读写。可以配置备份。
3、 每个partition都有一个server为"leader",负责读写,其余的相对备份机为follower,follower同步leader数据,负责leader死了之后的接管。n个leader均衡的分散在每个server上。
4、 partition的leader和follower之间监控通过zookeeper完成。
segment
1、 每个segment中存储多条消息,消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。
2、 当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被flush到磁盘,只有flush到磁盘上的消息订阅者才能订阅到
3、 segment达到一定的大小(可以通过配置文件设定,默认1G)后将不会再往该segment写数据,broker会创建新的segment。

offset
offset是每条消息的偏移量。
segment日志文件中保存了一系列"log entries"(日志条目),每个log entry格式为"4个字节的数字N表示消息的长度" + "N个字节的消息内容";
每个日志文件都有一个offset来唯一的标记一条消息,offset的值为8个字节的数字,表示此消息在此partition中所处的起始位置.
每个partition在物理存储层面,有多个log file组成(称为segment).
segment file的命名为"最小offset".log.例如"00000000000.log";其中"最小offset"表示此segment中起始消息的offset.
第1节 kafka消息队列:2、kafka的架构介绍以及基本组件模型介绍的更多相关文章
- 消息队列与Kafka
2019-04-09 关键词: 消息队列.为什么使用消息队列.消息队列的好处.消息队列的意义.Kafka是什么 本篇文章系本人就当前所掌握的知识关于 消息队列 与 kafka 知识点的一些简要介绍,不 ...
- Spring Cloud(7):事件驱动(Stream)分布式缓存(Redis)及消息队列(Kafka)
分布式缓存(Redis)及消息队列(Kafka) 设想一种情况,服务A频繁的调用服务B的数据,但是服务B的数据更新的并不频繁. 实际上,这种情况并不少见,大多数情况,用户的操作更多的是查询.如果我们缓 ...
- .NET中 kafka消息队列、环境搭建与使用
前面几篇文章中讲了一些关于消息队列的知识,就每中消息队列中间件,我们并没有做详细的讲解,那么,今天我们就来详细的讲解一下消息队列之一kafka的一些基本的使用与操作. 一.kafka介绍 kafka: ...
- redis 的消息队列 VS kafka
redis push/pop VS pub/sub (1)push/pop每条消息只会有一个消费者消费,而pub/sub可以有多个 对于任务队列来说,push/pop足够,但真的在做分布式消息分发的时 ...
- kafka消息队列的简单理解
kafka在大数据.分布式架构中都很流行.kafka可以进行流式计算,也可以做为日志系统,还可以用于消息队列. 本篇主要是消息队列相关的知识. 零.kafka作为消息队列的优点: 分布式的系统 高吞吐 ...
- 使用kafka消息队列解决分布式事务(可靠消息最终一致性方案-本地消息服务)
微服务框架Spring Cloud介绍 Part1: 使用事件和消息队列实现分布式事务 本文转自:http://skaka.me/blog/2016/04/21/springcloud1/ 不同于单一 ...
- 消息队列之 Kafka
转 https://www.jianshu.com/p/2c4caed49343 消息队列之 Kafka 预流 2018.01.15 16:27* 字数 3533 阅读 1114评论 0喜欢 12 K ...
- 初试kafka消息队列中间件一 (只适合初学者哈)
初试kafka消息队列中间件一 今天闲来有点无聊,然后就看了一下关于消息中间件的资料, 简单一点的理解哈,网上都说的太高大上档次了,字面意思都想半天: 也就是用作消息通知,比如你想告诉某某你喜欢他,或 ...
- 初试kafka消息队列中间件二(采用java代码收发消息)
初试kafka消息队列中间件二(采用java代码收发消息) 上一篇 初试kafka消息队列中间件一 今天的案例主要是将采用命令行收发信息改成使用java代码实现,根据上一篇的接着写: 先启动Zooke ...
随机推荐
- CSS-复选框默认样式修改
在css文件中添加如下代码 input[type='checkbox'] { -webkit-appearance: none; background: #fff url('../../static/ ...
- CCF认证 2019-12-3
分析 后面的数据,坐标分布太离散,不能用一个二位数组来模拟垃圾分布.因此,考虑用一个数组记录每个垃圾点的位置. 先根据x坐标.再根据y坐标进行排序. 再遍历数组中的每一处垃圾点,判断其是否能建回收站( ...
- Fizz Buzz in tensorflow
code from keras.layers.normalization import BatchNormalization from keras.models import Sequential f ...
- 在centos 7中安装phpmyadmin
安装phpmyadmin数据库管理系统 //1.下载phpmyadmin包wget https://files.phpmyadmin.net/phpMyAdmin/4.7.0/phpMyAdmin-4 ...
- scrapy爬取阳光电影网全站资源
说一下我的爬取过程吧 第一步: 当然是 scrapy startproject + 名字 新建爬虫项目 第二步: scrapy genspider -t crawl +爬虫名字+ 所爬取网站的 ...
- 吴裕雄--天生自然TensorFlow2教程:损失函数及其梯度
import tensorflow as tf x = tf.random.normal([2, 4]) w = tf.random.normal([4, 3]) b = tf.zeros([3]) ...
- 计划任务cron,date,时间同步ntp,chrony
取出磁盘利用率最大值 ,写个脚本,做判断,只要快满了,就报警 计划周期性执行的任务提交给crond,到指定时间会自动运行 系统cron任务:系统维护作业 /etc/crontab 用户cron任务: ...
- jQuery结合CSS实现手风琴组件(2)----利用seajs实现静态资源模块化引入
1. 目录结构(webStrom) 2. 代码 1.html <!DOCTYPE html> <html lang="en"> <head> & ...
- ➡️➡️➡️IELTS reading by Simon on Bili
高分必备 雅思考官Simon手把手教你做阅读 p1 https://www.bilibili.com/video/av40131278?p=2 p2 https://www.bilibili.com/ ...
- kafka 分区
1. 默认存储 /tmp/kafka-logs test-0 0:分区数