文献及代码阅读报告 - SS-LSTM:A Hierarchical LSTM Model for Pedestrian Trajectory Prediction

概览
简述
SS-LSTM全称Social-Scene-LSTM,是一种分层的LSTM模型,在已有的考虑相邻路人之间影响的Social-LSTM模型之上额外增加考虑了行人背景的因素。SS-LSTM架构类似Seq2Seq,由3个Encoder生成的向量拼接后形成1个Decoder的输入,并最终做出轨迹预测,有关Encoder和Decoder具体细节下文介绍。
主要结论与贡献
- 提出了SS-LSTM分层模型,相较于其他LSTM-based模型在benchmark数据集上有更好表现。
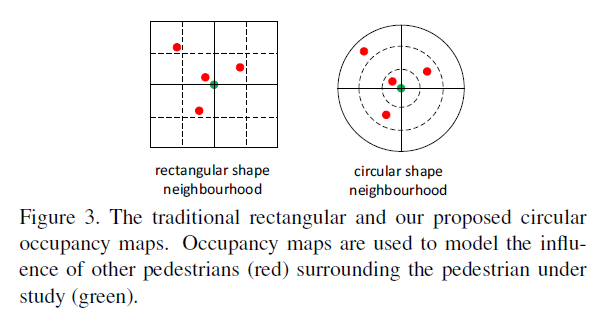
- 引入了圆形的neighborhood划分方式,经过实际对比得出log圆形区域划分相交线性圆形划分和矩形划分有更好表现。
测试
数据集:ETH、UCY(采用Alahi等人提出Social LSTM时使用的数据集,位置信息经过了归一化处理)。
测试指标:FDE、ADE
测试对象:
baseline:linear、Vanilla LSTM
LSTM-based:S-LSTM(g,c,l),SS-LSTM(g,c,l)
g: grid maps, c:circle maps, l: log maps(区别在于区域形状和划分标准不同)
进一步研究方向
- 增加行人的影响权重,例如依据行人间的距离。(此文采用的neighborhood矩阵是Occupancy Tensor而不是Social Tensor,在模型开始跑之间可以完全求出,即每个行人的LSTM数据在运行中不会交叉。详情请见https://www.cnblogs.com/sinoyou/p/11227348.html)
- 为模型加入空间-时间的注意力机制。
- 为模型加入新网络以学习其他因素,例如场景中行人之间的舒适距离。
模型
整体框架

[注意]:图示来自论文,查阅模型代码后发现部分连线有误导性,详情见下一节。
1. Person Scale LSTM Encoder
描述:对于行人\(i\),编码其自身的轨迹序列。
模型输入:\(X_{obs}^i = [(x_1^i,y_1^i), ..., (x_{obs}^i,y_{obs}^i)]\)
模型迭代:\(p_t^i = LSTM_l^{enc}(p_{t-1}^i, x_t^i, y_t^i, W_1)\)
2. Social Scale LSTM Encoder
描述:对于行人\(i\),编码其邻近行人的信息矩阵序列。
模型输入:Occupancy Map \(O_t^i\)
- Occupancy对于每个行人在每个时间片刻都是不同的。
- \(O_t^i(a,b) = \Sigma_{j \in N^i} \alpha_{ab}(x_t^j, y_t^j)\) (其中\(\alpha(.,.)\)是判断函数,根据行人\(j\)是否处在\(i\)编号为\([a,b]\)的区域内,映射至真值域)。
- 本文注重讨论了三种判断函数:
- 方形图
- 线性半径的圆形图
- log半径的圆形图
模型迭代:\(s_o^{i,t} = LSTM_2^{enc}(s_o^{i,t-1}, O_i^t, W_2)\)
3. Scene Scale Encoder
描述:对于行人\(i\),编码其所处图像背景信息。
模型输入:Scene Feature \(F_t\)
- 从图片到LSTM的输入\(F_t\),需要使用CNN网络提取特征。
- CNN网络同其他LSTMs共同训练,包含三层带池化的卷积层,两层全连接层和防止过拟合的Batch Normalization层。

模型迭代:\(s_c^{i,t} = LSTM_3^{enc}(s_c^{i,t-1}, F_t, W_3)\)
4. Decoder
描述:根据三个Encoder编码出的向量进行解码,做出轨迹预测。
模型输入:将来自Person Scale,Social Scale,Scene Scale编码器的输入拼接。
- \(h_i^t = \varphi(p_t^i, s_o^{i,t}, s_c^{i,t}) = p_t^i \oplus s_o^{i,t} \oplus s_c^{i,t}\)
- [注意]:原文描述与源代码实现存在出入,原文\(h_i^t\)的计算部分是\(1<=t<=obs\),但源代码并不是这样实现的,详情请见下文。
模型迭代:
\]
\]
[注意]:与Social LSTM,Spatio-Temporal Attention Network等不同的是,SS-LSTM模型的decoder输出不再是基于高斯二维分布,而是直接将Decoder的输出经线性变换后即得到预测轨迹的坐标值。
SS-LSTM模型细节内容探讨
在阅读SS-LSTM的原文时由于阅读能力不足/文章描述不充分导致对模型部分细节存在疑惑,好在原文中提供了模型的源代码,因而解答了这些疑惑,在此做一些记录。若笔者理解存在问题,恳请批评指正。
Question 1
模型训练时的损失函数?
模型对于Decoder的输出并未采用二维高斯分布的假设,因此无法使用negative log-likelihood作为损失函数。经过笔者阅读,尚未在原文中发现有关损失函数的描述,在源代码中损失函数采用Mean Square Error。
Question 2
对于Decoder的LSTM,其每步迭代过程中的输入是什么?
原文有指明Decoder每步运行的输入:\(h_i^t = \varphi(p_t^i, s_o^{i,t}, s_c^{i,t}) = p_t^i \oplus s_o^{i,t} \oplus s_c^{i,t}\)(即对应的三个encoder每一步输出的拼接值),但放在实际情况中存在几个矛盾:
- 若\(obs\_length < pred\_length\),则没有足够的\(h_i^t\)可以提供。
- 即使有足够的\(h_i^t\),decoder最多能够预测到\(obs\_length+1\)时刻的位置,因为若要预测\(obs\_length+2\)则需要三个encoder提供对应信息,而实际上又无法提供。
根据查阅源代码,模型中Decoder每运行一步时输入都是一样的,为person scale, social scale, scene scale三个Encoder最终一次输出拼接得到的向量。这是一种Seq2Seq模型中较为简单的模型,在解码时都没有使用Decoder上一步的输出作为输入。
model = Sequential()
model.add(Merge([scene_scale, group_model, person_model], mode='sum'))
model.add(RepeatVector(predicting_frame_num)) # 复制拼接向量,使decoder每步输入都一致。
model.add(GRU(128,
input_shape=(predicting_frame_num, 2),
batch_size=batch_size,
return_sequences=True,
stateful=False,
dropout=0.2))
因此回到上文中文中所给出的SS-LSTM模型的整体结构(见下图),连接线展现出三个Encoder每步运算后得到的输出都参与了Decoder输入的拼接,但这与源代码是存在矛盾的。
Question 3
通过CNN抽取的背景图像特征\(F_t\),是否需要有下标t?(是否需要虽时间发生变化)
严格来说是需要的,但是由于Scene Scale主要用于捕获图像的非行人特征,而不同时间段图像特征的差异主要在行人,因此\(LSTM_3^{enc}\)的每一步输入可以是一致的,源代码中采用这种思路,即对于每个行人的轨迹预测,抹去了图像特征的时间因素。
scene_scale = CNN(dimensions_1[1], dimensions_1[0])
scene_scale.add(RepeatVector(tsteps)) # 复制CNN输出tsteps=obs_length次,使lstm每步输入相同
scene_scale.add(GRU(hidden_size,
input_shape=(tsteps, 512),
batch_size=batch_size,
return_sequences=False,
stateful=False,
dropout=0.2))
Question 4
圆形的邻近区域的数据存储方式?
如下图,对于矩形区域,Occupancy Map的形状为[4,4]或[4x4];而对于圆形区域,Map可按照自行编码习惯映射为矩阵或向量,例如,以半径为第一维度,圆角为第二维度,则Map形状为[3,4]或[3x4]
Article:
H. Xue, D. Q. Huynh and M. Reynolds, "SS-LSTM: A Hierarchical LSTM Model for Pedestrian Trajectory Prediction," 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, 2018, pp. 1186-1194.
Code - implemented with keras:
- link: https://github.com/xuehaouwa/SS-LSTM
- The codes is not complete: datasets, self-defined function, program entry of train & sample and etc. So codes are not directly runnable.
文献及代码阅读报告 - SS-LSTM:A Hierarchical LSTM Model for Pedestrian Trajectory Prediction的更多相关文章
- 文献阅读报告 - 3DOF Pedestrian Trajectory Prediction
文献 Sun L , Yan Z , Mellado S M , et al. 3DOF Pedestrian Trajectory Prediction Learned from Long-Term ...
- 文献阅读报告 - Situation-Aware Pedestrian Trajectory Prediction with Spatio-Temporal Attention Model
目录 概览 描述:模型基于LSTM神经网络提出新型的Spatio-Temporal Graph(时空图),旨在实现在拥挤的环境下,通过将行人-行人,行人-静态物品两类交互纳入考虑,对行人的轨迹做出预测 ...
- 文献阅读报告 - Pedestrian Trajectory Prediction With Learning-based Approaches A Comparative Study
概述 本文献是一篇文献综述,以自动驾驶载具对外围物体行动轨迹的预测为切入点,介绍了基于运动学(kinematics-based)和基于机器学习(learning-based)的两大类预测方法. 并选择 ...
- 文献阅读报告 - Social LSTM:Human Trajectory Prediction in Crowded Spaces
概览 简述 文献所提出的模型旨在解决交通中行人的轨迹预测(pedestrian trajectory prediction)问题,特别是在拥挤环境中--人与人交互(interaction)行为常有发生 ...
- 文献阅读报告 - Social BiGAT + Cycle GAN
原文文献 Social BiGAT : Kosaraju V, Sadeghian A, Martín-Martín R, et al. Social-BiGAT: Multimodal Trajec ...
- 脚本病毒分析扫描专题1-VBA代码阅读扫盲、宏病毒分析
1.Office Macor MS office宏的编程语言是Visual Basic For Applications(VBA). 微软在1994年发行的Excel5.0版本中,即具备了VBA的宏功 ...
- 代码阅读分析工具Understand 2.0试用
Understand 2.0是一款源代码阅读分析软件,功能强大.试用过一段时间后,感觉相当不错,确实可以大大提高代码阅读效率.由于Understand功能十分强大,本文不可能详尽地介绍它的所有功能,所 ...
- Android 上的代码阅读器 CoderBrowserHD 修改支持 go 语言代码
我在Android上的代码阅读器用的是 https://github.com/zerob13/CoderBrowserHD 改造的版本,改造后的版本我放在 https://github.com/ghj ...
- Linux协议栈代码阅读笔记(二)网络接口的配置
Linux协议栈代码阅读笔记(二)网络接口的配置 (基于linux-2.6.11) (一)用户态通过C库函数ioctl进行网络接口的配置 例如,知名的ifconfig程序,就是通过C库函数sys_io ...
随机推荐
- 命令打开java控制面板
运行一些java程序时,会提示java安全阻止,需要手动运行,java7一起更改安全级别为“中”就可以了,java8需要配置信任网站 . 这些操作都需要在java控制面板进行,经常会出现无法在控制面板 ...
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 图片:将图片变为圆形 (IE8 不支持)
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- 手动搭建Vue之前奏:搭建webpack项目
手动搭建vue项目 搭建vue前首先搭建webpack项目 首先你应当安装一下npm以及nodejs 安装完成后,进行如下操作: // 创建项目根目录 mkdir some_project_name ...
- 18 SQL优化
1.SQL语句优化的一般步骤 1).了解各种SQL的执行频率 客户端连接成功后,可以通过SHOW [SESSION | GLOBAL] STATUS 命令来查看服务器状态信 ...
- HDU 5523:Game
Game Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others) 问题描述 XY在玩一 ...
- burpsite 和jdk的配置
最近小白再安装工具,首先是java的jdk,小白的电脑重装系统之后以前装的就没有了,然后记性不好的小白就开始百度了,百度上说是需要配置java_home和classpath路径然后再去编辑path路径 ...
- vue 中使用 echarts 自适应问题
echarts 自带的自适应方法 resize() 具体用法: let xxEcharts = this.$echarts.init(document.getElementById('xxx')) ...
- Linux安装C++环境
centos 安装gcc-c++ yum install gcc-c++ 安装CMake yum install cmake 切换gcc版本 安装devtoolset-x 安装devtoolset-3 ...
- 040、Java中逻辑运算之短路与运算“&&”
01.代码如下: package TIANPAN; /** * 此处为文档注释 * * @author 田攀 微信382477247 */ public class TestDemo { public ...
- LeetCode160 相交链表(双指针)
题目: click here!!题目传送门 思路: 1.笨方法 因为如果两个链表相交的话,从相交的地方往后是同一条链表,所以: 分别遍历两个链表,得出两个链表的长度,两个长度做差得到n,然后将长的链表 ...