1、Hbase原理分析
一、Hbase介绍
1.1、对Hbase的认识
- HBase作为面向列的数据库运行在HDFS之上,HDFS缺乏随机读写操作,HBase正是为此而出现。
- HBase参考 Google 的 Bigtable 实现,以键值对的形式存储。项目的目标就是快速在主机内数十亿行数据中定位所需的数据并访问它。
- HBase是建立在HDFS之上的分布式面向列的数据库;属于KV结构数据(V可以随便存,结构化数据和非结构化数据都可以),原生不支持标准SQL。
- HBase可以提供快速随机访问海量结构化数据。
- 它利用了Hadoop的文件系统(HDFS)提供的容错能力。
- Hive 和 Hbase都是作用在hdfs之上的。
- Hive :适合统计分析。Hive 执行的是mapreduce任务,延迟高。
- Hbase:适合大数据量查询,不适合统计分析。Hbase是键值对存储,可以快速返回数据。
1.2、Hbase数据单元
- RowKey:是Byte array,是表中每条记录的“主键”,按照字典顺序排序,唯一,方便快速查找,Rowkey的设计非常重要;
- Column Family:列族,拥有一个名称(string),包含一个或者多个相关列;
- Column:属于某一个columnfamily,familyName:columnName,每条记录可动态添加;
- Version Number:版本号,类型为Long,默认值是系统时间戳Timestamp,可由用户自定义;用于标记同一份数据的不同版本。
- Value(Cell):具体的值,Byte array;
- 总之,在一个HBase:
- 表是行的集合。
- 行是列族的集合。
- 列族是列的集合。
- 列是键值对的集合。
- 建表时:指定表的列族,列自己插入数据时动态创建
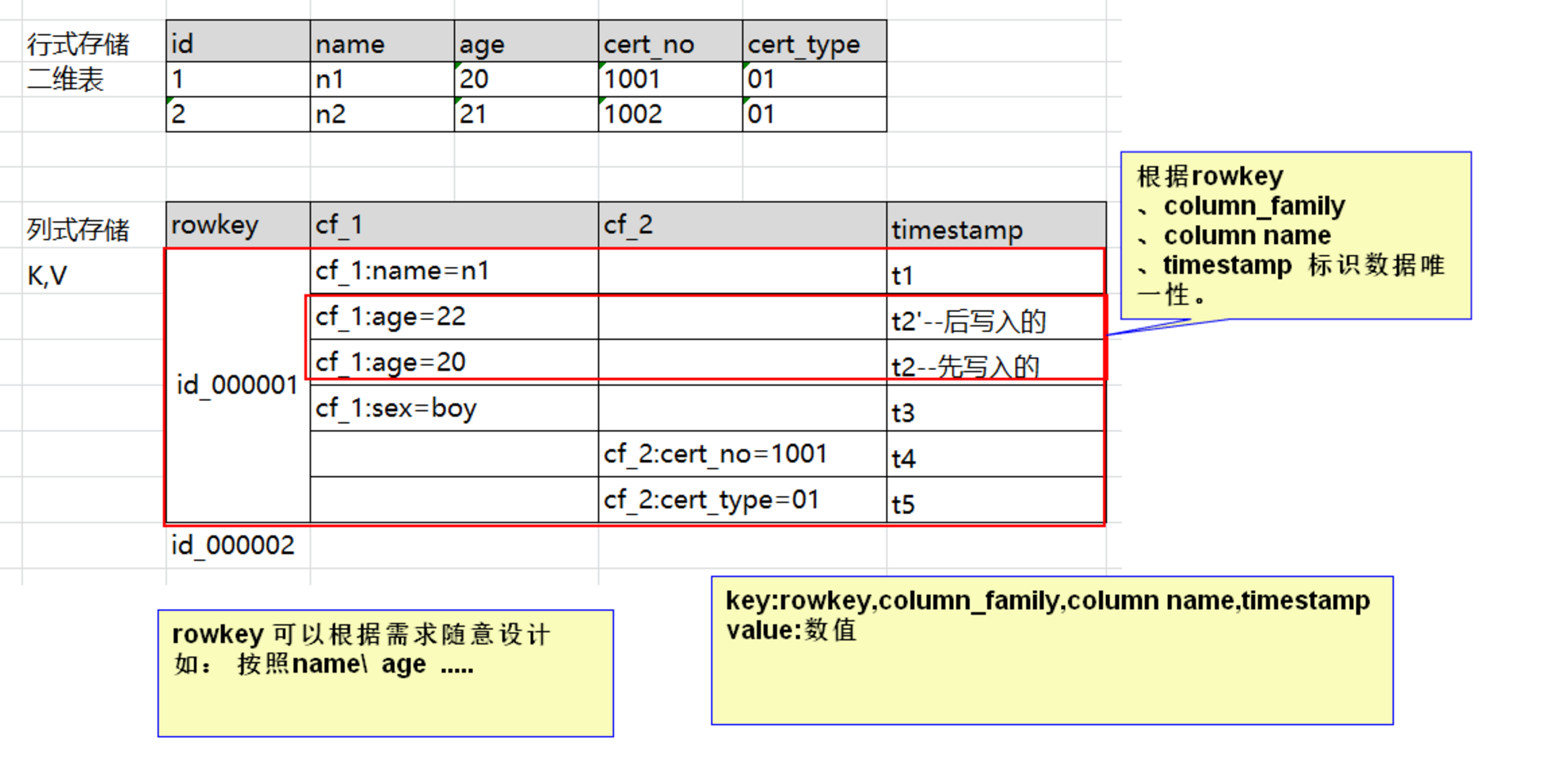
1.3、Hbase物理存储结构
- 每个column family存储在HDFS上的一个单独文件中,空值不会被保存;

Key 和 Version number在每个 column family中均有一份;
HBase 为每个值维护了多级索引,即:<key, column family, column name, timestamp>;
在物理层面上,表格的数据是通过StoreFile来存储的,每个StoreFile相当于一个可序列化的Map,Map的key和value都是可解释型字符数组;
Column Family是一组Column的组合,在HBase中,Schema的定义主要为Column Family的定义,同大多数nosql数据库一样,HBase也是支持自由定义Schema,但是前提要先定义出具体的Column Family,而在随后的column定义则没有任何约束;其次,HBase的访问权限控制,磁盘及内存统计等功能都是基于Column Family层面完成的;
HBase提供基于Cell的版本管理功能,版本号默认通过timestamp来标识,并且呈倒序排列;
二、Hbase原理分析
HBase采用Master/Slave(主仆结构)架构搭建集群,它隶属于Hadoop生态系统,由以下类型节点组成:
- HMaster节点
- HRegionServer节点
- ZooKeeper集群
- 而在底层,它将数据存储于HDFS中,因而涉及到HDFS的NameNode、DataNode等
总体结构如下:
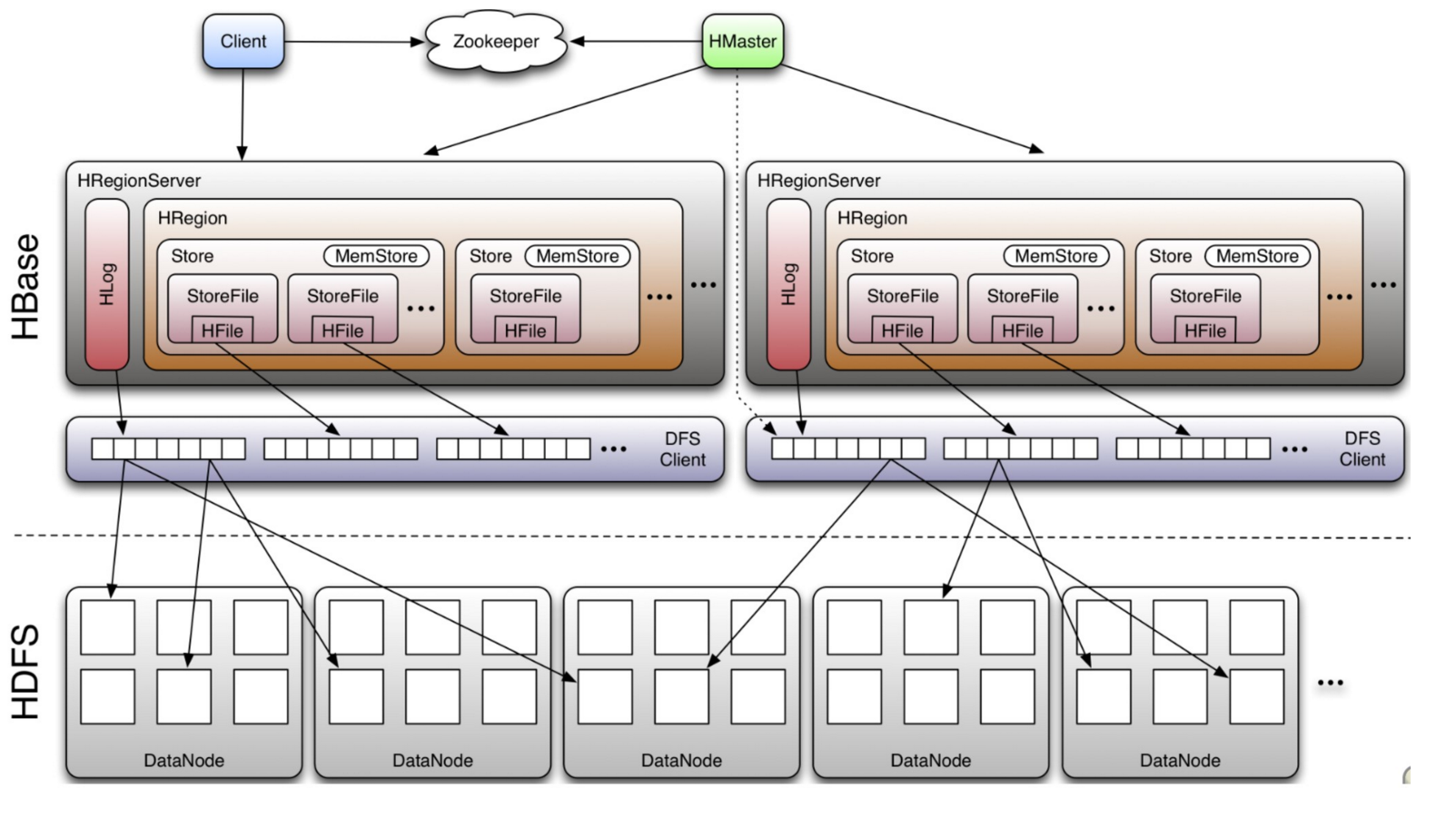
2.1、Client
- 使用HBase RPC机制与HMaster和HRegionServer进行通信;
- Client与HMaster进行通信进行管理类操作;
- Client与HRegionServer进行数据读写类操作;
2.2、HMaster
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper保证总有一个Master在运行。
HMaster主要负责Table和Region的管理工作:
- 管理用户对表的增删改查操作DDL;
- 管理HRegionServer的负载均衡,调整Region分布;
- Region Split后,负责新Region的分布;
- 在HRegionServer停机后,负责失效HRegionServer上Region 的迁移;
2.3、HRegionServer
HBase中最核心的模块;
- 维护region,处理对这些region的IO请求;
- Regionserver负责切分在运行过程中变得过大的region;
- 一个HRegionServer包括多个HRegion和一个Hlog
HRegion介绍
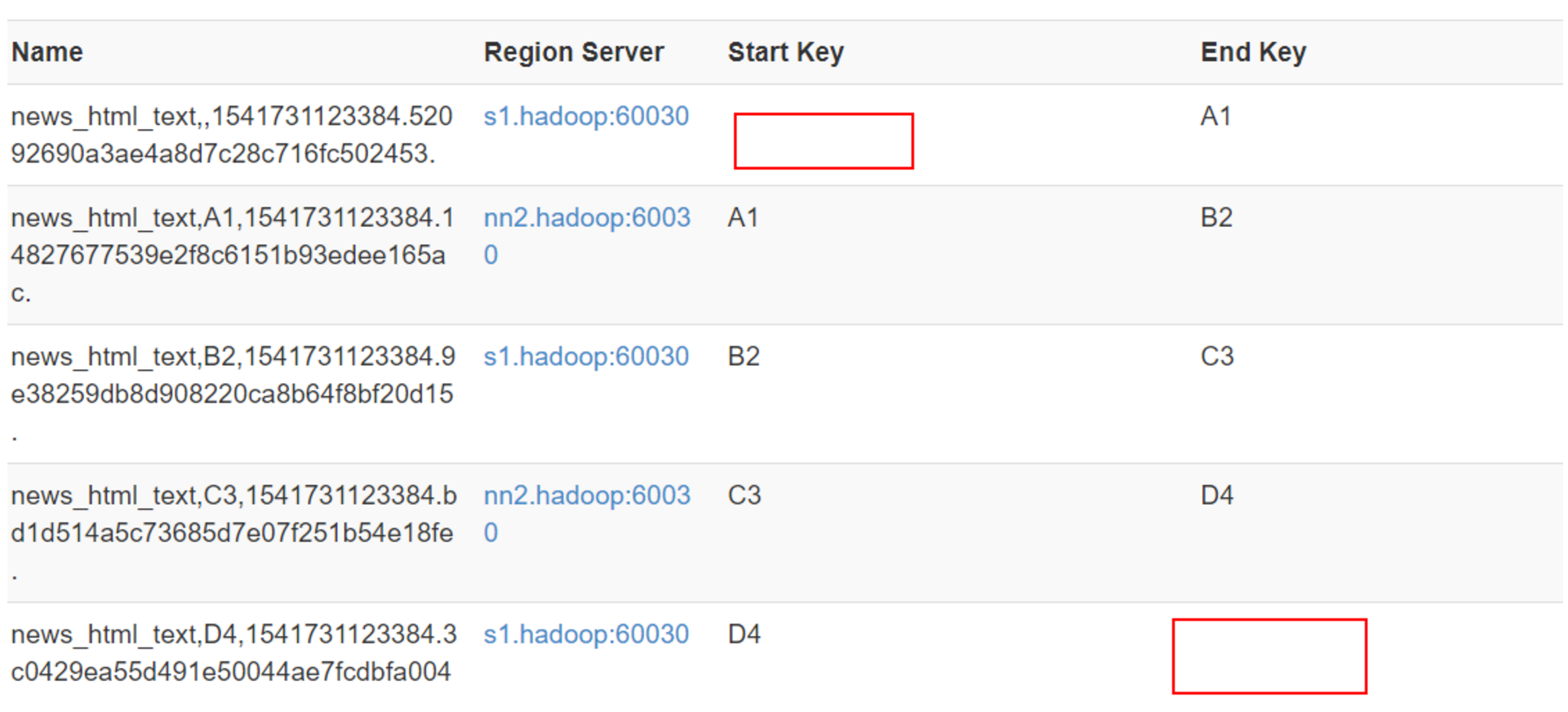
HBase使用RowKey将表水平切割成多个HRegion,从HMaster的角度,每个HRegion都纪录了它的StartKey和EndKey(第一个HRegion的StartKey为空,最后一个HRegion的EndKey为空),由于RowKey是排序的,因而Client可以通过HMaster快速的定位每个RowKey在哪个HRegion中。(通俗理解:就是通过StartKey和Endkey将rowkey按照顺序存储)

查看web UI
HregionServer详解
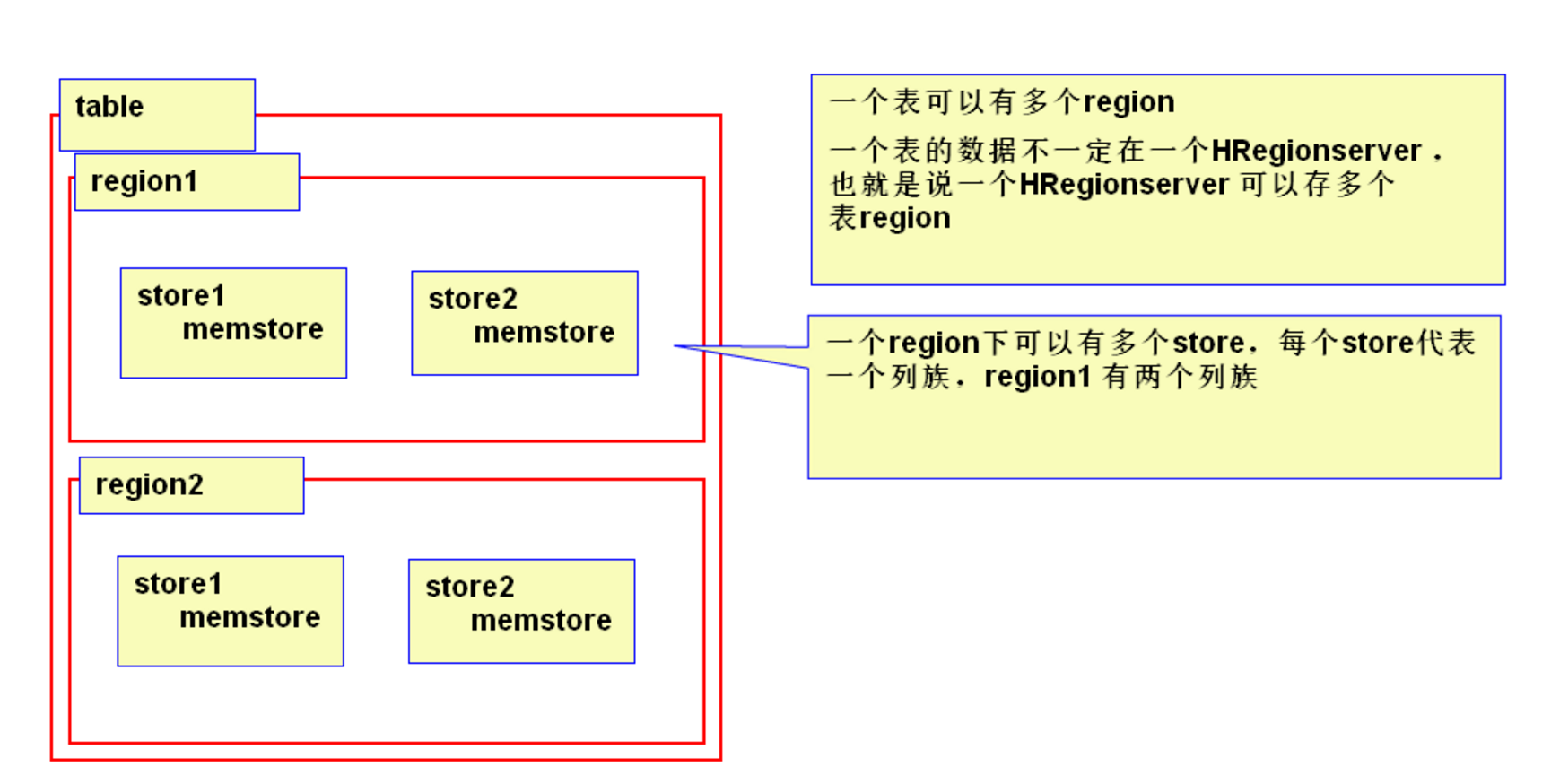
- HRegionServer一般和DataNode在同一台机器上运行,实现数据的本地性。
- HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了Table中的一个Region。
- 一个Table可以有一个或多个Region,他们可以在一个相同的HRegionServer上,也可以分布在不同的HRegionServer上,一个HRegionServer可以有多个HRegion,他们分别属于不同的Table。
- HRegion由多个Store(HStore)构成,每个HStore对应了一个Table在这个HRegion中的一个Column Family,即每个Column Family就是一个集中的存储单元,因而最好将具有相近IO特性的Column存储在一个Column Family,以实现高效读取。
- 每个HRegionServer中都会有一个HLog对象。HLog是一个实现Write Ahead Log的类,每次用户操作写入Memstore的同时,也会写一份数据到HLog文件,HLog文件定期会滚动出新,并删除旧的文件(已持久化到StoreFile中的数据)。
- 引入HLog原因:
- 灾难恢复。在分布式系统环境中,无法避免系统出错或者宕机,一旦HRegionServer意外退出,MemStore中的内存数据就会丢失,引入HLog就是防止这种情况。
- 一个HStore由一个MemStore 和0个或多个StoreFile组成。
- MemStore:
- 是一个写缓存(In Memory Sorted Buffer),所有数据的写在完成WAL日志写后,会写入MemStore中,由MemStore根据一定的算法将数据Flush到底层HDFS文件中(HFile),通常每个HRegion中的每个 Column Family有一个自己的MemStore。
- StoreFile:
- 用于存储HBase的数据(Cell/KeyValue)。在HFile中的数据是按RowKey、Column Family、Column排序,对相同的Cell(即这三个值都一样),则按timestamp倒序排列。
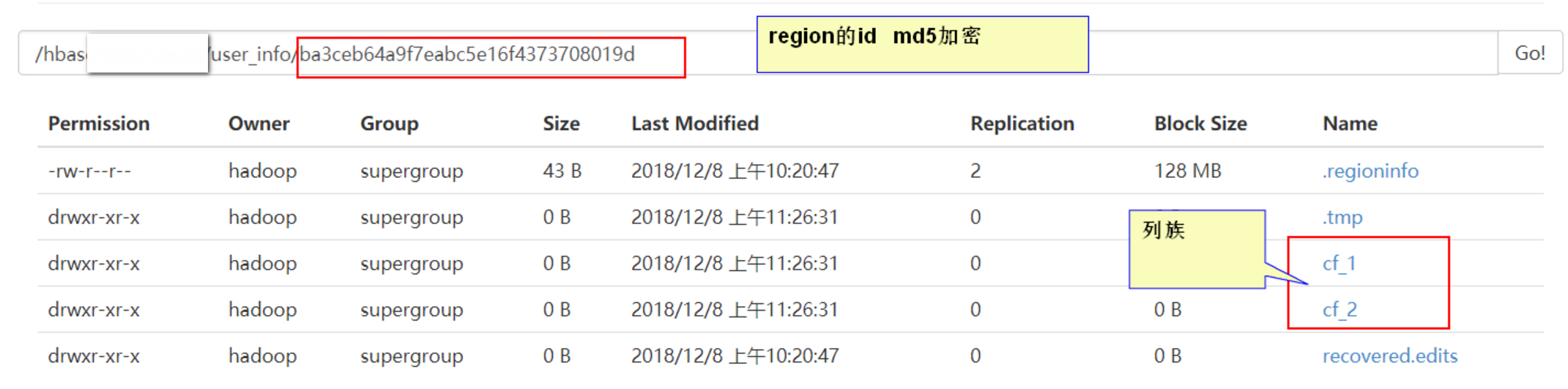
2.4、Zookeeper
- ZooKeeper为HBase集群提供协调服务,它管理着HMaster和HRegionServer的状态(available/alive等),并且保证集群中只有一个HMaster,会在它们宕机时通知给其他HMaster,从而可以实现HMaster之间的故障转移;
- 实时监控HRegionServer的上线和下线信息,并实时通知给HMaster;
- 存储HBase的Meta Table(hbase:meta)的位置,Meta Table表存储了集群中所有用户HRegion的位置信息,且不能split;
- Zookeeper的引入使得Master不再是单点故障;
在zookeeper的节点中:
/hbasae/master:来表示Active的HMaster;
如果当前Active的HMaster宕机,则该节点消失,因而其他HMaster得到通知,而将自身转换成Active的HMaster,在变为Active的HMaster之前,它会创建在/hbase/back-masters/下创建自己的Ephemeral节点;
1、Hbase原理分析的更多相关文章
- HBase原理分析
宏观架构 HBase从宏观上看只有HMaster.RegionServer和zookeeper三个组件. Master: 负责启动的时候分配Region到具体的RegionServer,执行各种管理操 ...
- flink-----实时项目---day07-----1.Flink的checkpoint原理分析 2. 自定义两阶段提交sink(MySQL) 3 将数据写入Hbase(使用幂等性结合at least Once实现精确一次性语义) 4 ProtoBuf
1.Flink中exactly once实现原理分析 生产者从kafka拉取数据以及消费者往kafka写数据都需要保证exactly once.目前flink中支持exactly once的sourc ...
- Hadoop生态圈-Zookeeper的工作原理分析
Hadoop生态圈-Zookeeper的工作原理分析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 无论是是Kafka集群,还是producer和consumer都依赖于Zoo ...
- HBase源代码分析之MemStore的flush发起时机、推断条件等详情(二)
在<HBase源代码分析之MemStore的flush发起时机.推断条件等详情>一文中,我们具体介绍了MemStore flush的发起时机.推断条件等详情.主要是两类操作.一是会引起Me ...
- Hadoop数据管理介绍及原理分析
Hadoop数据管理介绍及原理分析 最近2014大数据会议正如火如荼的进行着,Hadoop之父Doug Cutting也被邀参加,我有幸听了他的演讲并获得亲笔签名书一本,发现他竟然是左手写字,当然这个 ...
- HBase原理 – 分布式系统中snapshot是怎么玩的?(转载)
snapshot(快照)基础原理 snapshot是很多存储系统和数据库系统都支持的功能.一个snapshot是一个全部文件系统.或者某个目录在某一时刻的镜像.实现数据文件镜像最简单粗暴的方式是加锁拷 ...
- HBase笔记:对HBase原理的简单理解
早些时候学习hadoop的技术,我一直对里面两项技术倍感困惑,一个是zookeeper,一个就是Hbase了.现在有机会专职做大数据相关的项目,终于看到了HBase实战的项目,也因此有机会搞懂Hbas ...
- Handler系列之原理分析
上一节我们讲解了Handler的基本使用方法,也是平时大家用到的最多的使用方式.那么本节让我们来学习一下Handler的工作原理吧!!! 我们知道Android中我们只能在ui线程(主线程)更新ui信 ...
- Java NIO使用及原理分析(1-4)(转)
转载的原文章也找不到!从以下博客中找到http://blog.csdn.net/wuxianglong/article/details/6604817 转载自:李会军•宁静致远 最近由于工作关系要做一 ...
随机推荐
- Continue 和 Break
1.什么是continue和break continue:继续的.持续的 break:冲断的.折断的 作用:用于终止循环体,主要用于switch条件语句和循环体条件语句(for.while.do-wh ...
- 弹幕有点逗比,用 Python 爬下来看看《民国奇探》的弹幕
电视剧<民国奇探>是一部充斥着逗比风的探案剧,剧中主要角色:三土.四爷.白小姐,三土这个角色类似于<名侦探柯南>中的柯南但带有搞笑属性,四爷则类似于毛利小五郎但有大哥范且武功高 ...
- 2020不平凡的90天,Python分析三个月微博热搜数据带你回顾
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:刘早起早起 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- Roles on a Machine Learning Project (机器学习项目中的角色)
原文 :https://medium.com/machine-learning-in-practice/roles-on-a-machine-learning-project-216903a6dc12 ...
- 掷骰子 dp
B. 掷骰子 单点时限: 2.0 sec 内存限制: 512 MB 骰子,中国传统民间娱乐用来投掷的博具,早在战国时期就已经被发明. 现在给你 n 个骰子,求 n 个骰子掷出点数之和为 a 的概率是多 ...
- SpringCloud(三)学习笔记之Ribbon
spring Cloud Ribbon 是一个客户端的负载均衡器,它提供对大量的HTTP和TCP客户端的访问控制. 客户端负载均衡即是当浏览器向后台发出请求的时候,客户端会向 Eureka Serve ...
- tf.keras的模块
- 关于DNS解析:侧面剖析
作为一个合格的重度windows使用用户,我清楚的知道一个文件——hosts文件:C:\Windows\System32\drivers\etc\hosts文件 该文件需要一定的管理员权限. 这个文件 ...
- Java 添加、隐藏/显示、删除PDF图层
本文介绍操作PDF图层的方法.可分为添加图层(包括添加线条.形状.字符串.图片等图层).隐藏或显示图层.删除图层等.具体可参考如下Java代码示例. 工具:Free Spire.PDF for Jav ...
- 2019-2020-1 20199326《Linux内核原理与分析》第五周作业
第五周学习内容 庖丁解牛Linux内核分析第四章:系统调用的三层机制(上) Linux内核分析实验四 学到的一些知识 4.1用户态.内核态.中断 宏观上Linux操作系统的体系架构分为用户态和内核态 ...