Flink 笔记(一)
简介
Flink是一个低延迟、高吞吐、统一的大数据计算引擎, Flink的计算平台可以实现毫秒级的延迟情况下,每秒钟处理上亿次的消息或者事件。
同时Flink提供了一个Exactly-once的一致性语义, 保证了数据的正确性。(对比其他: At most once, At least once)
这样就使得Flink大数据引擎可以提供金融级的数据处理能力(安全)。
Flink作为主攻流计算的大数据引擎,它区别于Storm,Spark Streaming以及其他流式计算引擎的是:
- 它不仅是一个高吞吐、低延迟的计算引擎,同时还提供很多高级的功能。
- 比如它提供了有状态的计算,支持状态管理,支持强一致性的数据语义以及支持Event Time,WaterMark对消息乱序的处理。
发展历程
- Flink诞生于欧洲的一个大数据研究项目StratoSphere。
- 该项目是柏林工业大学的一个研究性项目。
- 早期,Flink是做Batch计算的,但是在2014年,StratoSphere里面的核心成员孵化出Flink,同年将Flink捐赠Apache,并在后来成为Apache的顶级大数据项目。
- Flink计算的主流方向被定位为Streaming,即用流式计算来做所有大数据的计算,这就是Flink技术诞生的背景。
与其他计算引擎的对比
开源大数据计算引擎
- 流计算(Streaming)
- Storm
- Flink
- SparkStreaming等
- 批处理(batch)
- Spark
- MapReduce
- Pig(好像已凉)
- Flink等
- 同时支持流处理和批处理的:
- Apache Spark
- Apache Flink
- 从技术, 生态等各方面综合考虑
- Spark的技术理念是基于批来模拟流的计算
- Flink则完全相反,它采用的是基于流计算来模拟批计算
- 可将批数据看做是一个有边界的流
- Flink最区别于其他流计算引擎的点:
- stateful, 即有状态计算。
- Flink提供了内置的对状态的一致性的处理,即如果任务发生了Failover,其状态不会丢失、不会被多算少算,同时提供了非常高的性能。
- 什么是状态?
- 例如开发一套流计算的系统或者任务做数据处理,可能经常要对数据进行统计,如Sum,Count,Min,Max,这些值是需要存储的。
- 因为要不断更新,这些值或者变量就可以理解为一种状态。
- 如果数据源是在读取Kafka,RocketMQ,可能要记录读取到什么位置,并记录Offset,这些Offset变量都是要计算的状态。
- Flink提供了内置的状态管理,可以把这些状态存储在Flink内部,而不需要把它存储在外部系统。
- 这样做的好处:
- 降低了计算引擎对外部系统的依赖以及部署,使运维更加简单
- 对性能带来了极大的提升
- 如果通过外部去访问,如Redis,HBase它一定是通过网络及RPC。
- 如果通过Flink内部去访问,它只通过自身的进程去访问这些变量。
- 同时Flink会定期将这些状态做Checkpoint持久化,把Checkpoint存储到一个分布式的持久化系统中,比如HDFS。
- 这样的话,当Flink的任务出现任何故障时,它都会从最近的一次Checkpoint将整个流的状态进行恢复,然后继续运行它的流处理。
- 对用户没有任何数据上的影响。
- 这样做的好处:
- 流计算(Streaming)
性能对比
Flink是一行一行处理,而SparkStream是基于数据片集合(RDD)进行小批量处理,所以Spark在流式处理方面,不可避免增加一些延时。
Flink的流式计算跟Storm性能差不多,支持毫秒级计算,而Spark则只能支持秒级计算。
Spark vs Flink vs Storm:
- Spark:
- 以批处理为核心,用微批去模拟流式处理
- 支持SQL处理,流处理,批处理
- 对于流处理:因为是微批处理,所有实时性弱,吞吐量高,延迟度高
- Flink:
- 以流式处理为核心,用流处理去模拟批处理
- 支持流处理,SQL处理,批处理
- u 对于流处理:实时性强,吞吐量高,延迟度低。
- Storm:
- 一条一条处理数据,实时性强,吞吐量低,延迟度低。
- Spark:
Flink 与 Storm的吞吐量对比
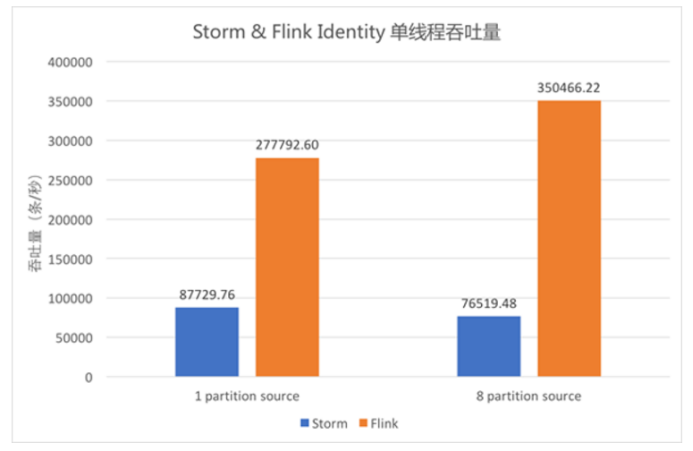
storm与flink延迟随着数据量增大而变化的对比
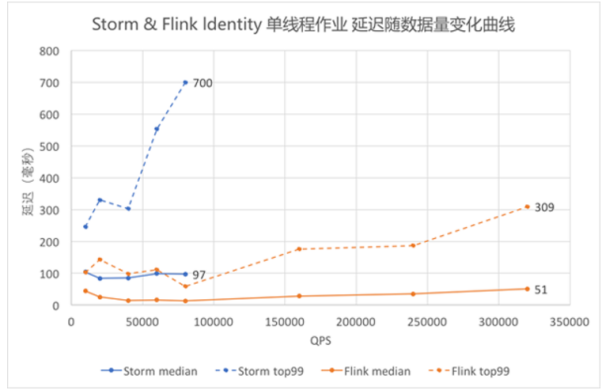
阿里使用Jstorm时遇到的问题:

后来他们将 JStorm 的作业迁移到 Flink集群上
Flink 是什么?
Apache Flink是一个分布式计算引擎,用于对无界和有界数据流进行状态计算
Flink可以在所有常见的集群环境中运行,并且能够对任何规模的数据进行计算。
这里的规模指的是既能批量处理(批计算)也能一条一条的处理(流计算)。
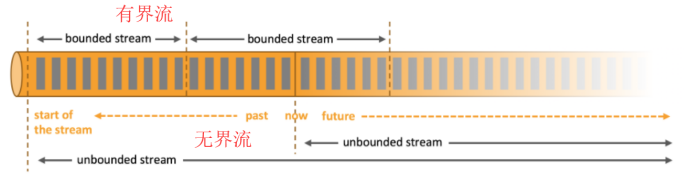
有界和无界数据:
Flink认为任何类型的数据都是作为事件流产生的。
比如:信用卡交易,传感器测量,机器日志或网站或移动应用程序,所有这
数据可以作为无界或有界流处理:
无界流:
- 它有开始时间但没有截止时间,它们在生成时提供数据,但不会被终止。
- 无界流必须连续处理数据,即必须在摄取事件后立即处理事件。
- 它无法等待所有输入数据到达,因为输入是无界的,如果是这样,在任何时间点都不会完成。
- 处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果完整性。
有界流:
- 具有起始时间和截止时间。
- 它可以在执行任何的计算之前,先通过摄取所有数据后再来处理有界流。
- 处理有界流不需要有序摄取,因为可以对有界数据集进行排序。
- 有界流的处理也称为批处理。
Flink 适用场景
事件驱动应用
欺诈识别
异常检测
基于规则的警报
业务流程监控
数据分析应用
电信网络的质量监控
分析移动应用程序中的产品更新和实验评估
对消费者技术中的实时数据进行特别分析
大规模图分析
数据管道 & ETL
- 电子商务中的实时搜索索引构建
- 电子商务中持续的 ETL
Flink 编程模型
Flink提供不同级别的抽象来开发流/批处理应用程序
抽象层次
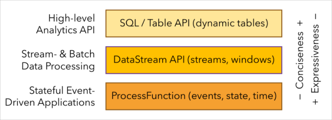
- 最低级抽象只是提供有状态流。它通过 Process Function 嵌入到 DataStream API 中
- 在实践中,大多数应用程序不需要上述低级抽象,而是针对DataStream API(有界/无界流)和DataSet API (有界数据集)
批处理: DataSet 案例
Scala 版:
package com.ronnie.batch object WordCount {
def main(args: Array[String]): Unit = {
// 引入隐式转换
import org.apache.flink.api.scala._
// 1. 初始化执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 2. 读取数据源, -> dataset 集合, 类似spark的RDD
val data = env.readTextFile("/data/textfile")
// 3. 对数据进行转化 val result = data.flatMap(x=>x.split(" "))
.map((_,1))
.groupBy(0)
.sum(1)
// 4. 打印数据结果
result.print()
}
}
Java 版:
package com.shsxt.flink.batch; import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector; public class WordCount { public static void main(String[] args) throws Exception { //1:初始执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); //2:读取数据源
DataSet<String> text = env.readTextFile("data/textfile");
//3:对数据进行转化操作
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
})
.groupBy(0)
.sum(1); //4:对数据进行输出
wordCounts.print();
} public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
流处理: DataStream 案例
Scala 版:
package com.ronnie.streaming import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.windowing.time.Time object WordCount {
def main(args: Array[String]): Unit = {
//引入scala隐式转换..
import org.apache.flink.api.scala._
//1.初始化执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.获取数据源, 生成一个datastream
val text: DataStream[String] = env.socketTextStream("ronnie01", 9999)
//3.通过转换算子, 进行转换
val counts = text.flatMap{_.split(" ")}
.map{(_,1)}
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1) counts.print() env.execute()
}
}
Java 版:
package com.ronnie.flink.stream; import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector; public class WordCount {
public static void main(String[] args) throws Exception {
//1.初始化环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取数据源,并进行转换操作
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("ronnie01", 9999)
.flatMap(new Splitter())
.keyBy(0)
//每5秒触发一批计算
.timeWindow(Time.seconds(5))
.sum(1);
//3.将结果进行输出
dataStream.print();
//4.流式计算需要手动触发执行操作,
env.execute("Window WordCount");
} public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> { public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
程序和数据流
Flink程序的基本构建是在流和转换操作上的, 执行时, Flink程序映射到流数据上,由流和转换运算符组成。
每个数据流都以一个或多个源开头,并以一个或多个接收器结束。
数据流类似于任意有向无环图 (DAG)

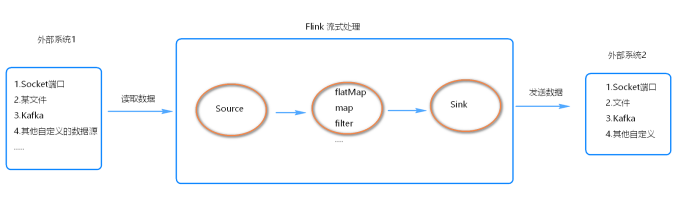
代码流程
- 创建ExecutionEnvironment/StreamExecutionEnvironment 执行环境对象
- 通过执行环境对象创建出source(源头)对象
- 基于source对象做各种转换,注意:在flink中转换算子也是懒执行的
- 定义结果输出到哪里(控制台,kafka,数据库等)
- 最后调用StreamExecutionEnvironment/ExecutionEnvironment 的excute方法,触发执行。
- 每个flink程序由source operator + transformation operator + sink operator组成
Flink中的Key
- 注意点:
- Flink处理数据不是K,V格式编程模型,没有xxByKey 算子,它是虚拟的key。
- Flink中Java Api编程中的Tuple需要使用Flink中的Tuple,最多支持25个
- 批处理用groupBY 算子,流式处理用keyBy算子
- Apache Flink 指定虚拟key
- 使用Tuples来指定key
- 使用Field Expression来指定key
- 使用Key Selector Functions来指定key
- 注意点:
Flink 笔记(一)的更多相关文章
- 01.Flink笔记-编译、部署
Flink开发环境部署配置 Flink是一个以Java及Scala作为开发语言的开源大数据项目,代码开源在github上,并使用maven来编译和构建项目.所需工具:Java.maven.Git. 本 ...
- flink笔记(三) flink架构及运行方式
架构图 Job Managers, Task Managers, Clients JobManager(Master) 用于协调分布式执行.它们用来调度task,协调检查点,协调失败时恢复等. Fli ...
- Flink笔记(二) DataStream Operator(数据流操作)
DataStream Source 基于文件 readTextFile(path) 读取 text 文件的数据 readFile(fileInputFormat, path) 通过自定义的读取方式, ...
- 02.Flink的单机wordcount、集群安装
一.单机安装 1.准备安装包 将源码编译出的安装包拷贝出来(编译请参照上一篇01.Flink笔记-编译.部署)或者在Flink官网下载bin包 2.配置 前置:jdk1.8+ 修改配置文件flink- ...
- Apache Flink学习笔记
Apache Flink学习笔记 简介 大数据的计算引擎分为4代 第一代:Hadoop承载的MapReduce.它将计算分为两个阶段,分别为Map和Reduce.对于上层应用来说,就要想办法去拆分算法 ...
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记:Flink Runtime
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Flink开发环境搭建
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Flink API 通用基本概念
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
随机推荐
- delphi IdSMTP发送邮件
TIdPOP3组件简介 TIdPOP3 是用来接收邮件服务器的邮件信息到用户端的一个组件.它实现了RFC 1939协议. 在使用TIdPOP3组件时需设置它的几个成员属性. Host :指定邮件服务器 ...
- 02-01 Android学习进度报告一
前两天,刚刚安装好有关Android开发有关的软件并配好了环境,有一些体会想要发表. 首先我了解到有一款专门用于Android开发的软件,叫做Android Studio ,是一个IDE集成软件 于是 ...
- [排错] VO对象和POJO对象的关系
这或许是一个很蠢的笔记吧...... 这次项目中, 作为一个新人, 没少被这两个概念虐得死去活来的, 现在特别做一次记录, 关于它们二者之间在项目中的应用. 在这里呢, 就不再赘述 VO(view o ...
- JDBC--Statement使用
1.通过Statement实现类执行更新操作(INSERT.UPDATE .DELETE): --1)获取数据库连接Connection的对象: --2)通过Connection类的createSta ...
- Thymeleaf--起步
Spring官方支持的服务的渲染模板中,并不包含jsp.而是Thymeleaf和Freemarker等,而Thymeleaf与SpringMVC的视图技术,及SpringBoot的自动化配置集成非常完 ...
- (转)spring mvc 中文乱码问题解决
在eclipse环境里,页面传输数据的时候通常用ISO-8859-1这个字符集可以用 str = new String(str.getBytes("ISO-8859-1"), &q ...
- c# Thread、ThreadPool、Task的区别
Thread与ThreadPoll 前台线程:主程序必须等待线程执行完毕后才可退出程序.Thread默认为前台线程,也可以设置为后台线程 后台线程:主程序执行完毕后就退出,不管线程是否执行完毕.Thr ...
- Shortest and Longest LIS
Codeforces Round #620 (Div. 2) D. Shortest and Longest LIS 题解: 贪心即可,对于最短序列,我们尽可能用可用的最大数字放入序列中,对于最长序列 ...
- DevOps - 自动化工具
章节 DevOps – 为什么 DevOps – 与传统方式区别 DevOps – 优势 DevOps – 不适用 DevOps – 生命周期 DevOps – 与敏捷方法区别 DevOps – 实施 ...
- Python学习笔记之基础篇(二)python入门
一.pycharm 的下载与安装: 使用教程:https://www.cnblogs.com/jin-xin/articles/9811379.html 破解的方法:http://xianchang. ...