[框架应用系列:Quartz快速上手] Java定时任务解决方案之Quartz集群
Quartz 是一个开源的作业调度框架,它完全由 Java 写成,并设计用于 J2SE 和 J2EE 应用中。它提供了巨大的灵 活性而不牺牲简单性。你能够用它来为执行一个作业而创建简单的或复杂的调度。它有很多特征,如:数据库支持,集群,插件,EJB 作业预构 建,JavaMail 及其它,支持 cron-like 表达式等等。
本文将带领大家快速上手SpringBoot中Quartz集群的搭建。
1. 理论基础
1.1 数据结构-堆
堆是一个完全二叉树,堆中节点的值总是不大于(或不小于)其父节点的值
根节点大的堆叫大顶堆,根节点小的叫小顶堆。
堆的数组表示方式

小顶堆
获取父节点方法:数组索引/2
例:值为4节点的父节点4/2 = 2;6/2 = 3
插入数据
插入尾部
上浮
删除堆顶
尾部元素放入堆顶
下沉
大家可以进入该操作模拟网站-堆操作可视化,模拟堆的数据操作查看处理流程。
1.2 时间轮算法(cron实现原理)
round时间轮
可以看作是一个数组,每一个节点可以保存一个round变量值,用来保存便利次数,例如表示在13点执行,那么第一次循环中1节点round值-1,第二次循环时执行。

小时时间轮
优点:当任务执行时间粒度小于1小时的时候,相较于全部节点都使用堆实现,同一时间段内无任务时可以sleep掉线程,减少cpu压力。
缺点:节点还是需要全部便利一遍。
分层时间轮
将时间轮根据时间分册为:年轮、月轮、周轮、小时轮。当执行到大轮的节点,再去执行相对应的小时间轮。
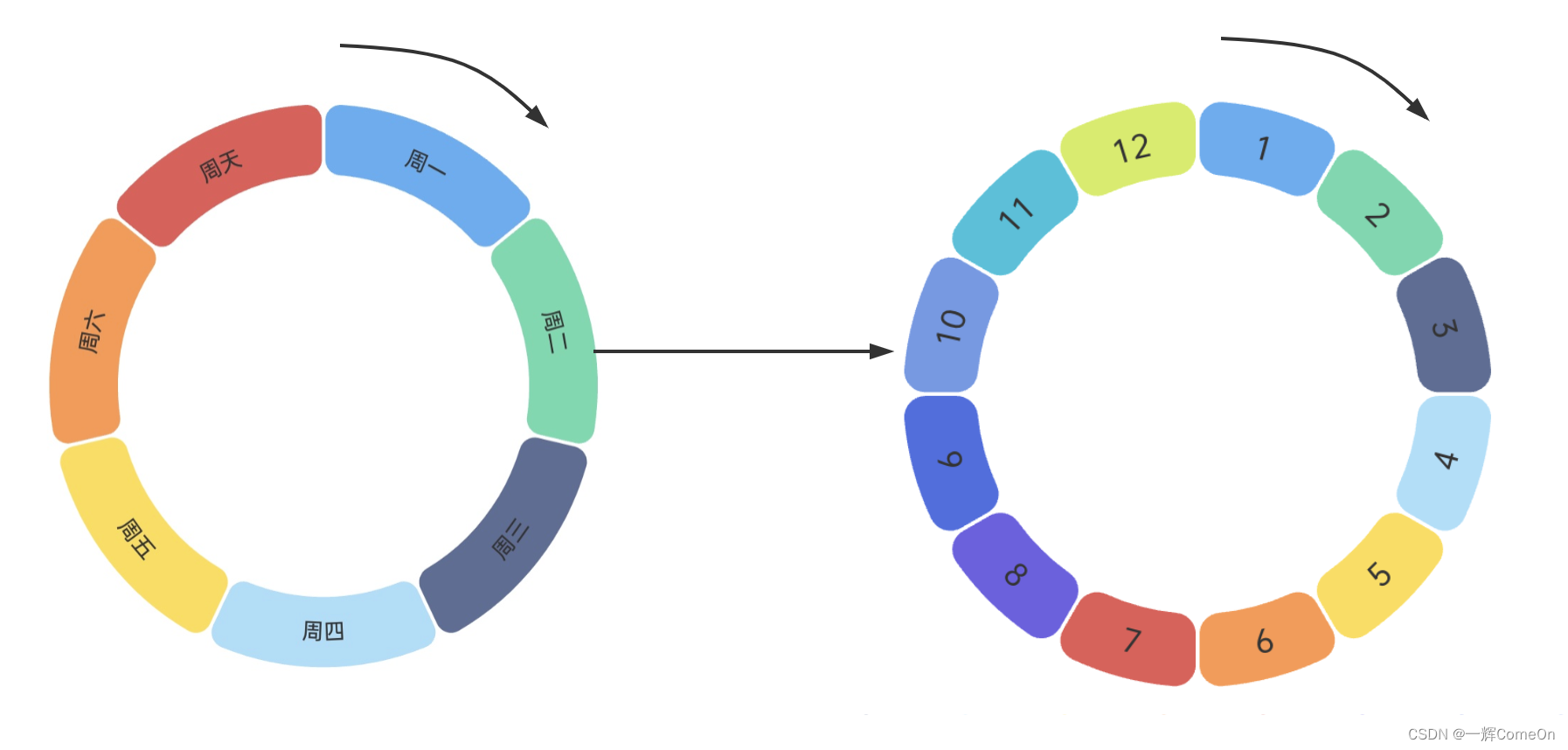
分层时间轮
优点:进一步扩大循环周期,减少循环次数以减少cpu消耗。
2. JDK-Timer介绍
2.1 测试案例
class MyTimerTask extends TimerTask {
private String name;
public MyTimerTask(String name) {
this.name = name;
}
@Override public void run() {
try {
System.out.println("[ name = "+name+" ,startTime="+new Date());
Thread.sleep(3000);
System.out.println(" name = "+name+" ,endTime="+new Date()+" ]");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
} @Test
public void TimerTest1(){
Timer timer = new Timer();
for(int i = 0; i < 3;i++) {
MyTimerTask timerTask = new MyTimerTask("task" + i);
//将任务入queue
timer.schedule(timerTask,new Date(),4000);
}
}
/**
测试结果:
[ name = task0 ,startTime=Sun Mar 12 12:52:11 CST 2023
name = task0 ,endTime=Sun Mar 12 12:52:14 CST 2023 ]
[ name = task1 ,startTime=Sun Mar 12 12:52:14 CST 2023
name = task1 ,endTime=Sun Mar 12 12:52:17 CST 2023 ]
[ name = task2 ,startTime=Sun Mar 12 12:52:17 CST 2023
name = task2 ,endTime=Sun Mar 12 12:52:20 CST 2023 ]
[ name = task2 ,startTime=Sun Mar 12 12:52:20 CST 2023
name = task2 ,endTime=Sun Mar 12 12:52:23 CST 2023 ]
[ name = task0 ,startTime=Sun Mar 12 12:52:23 CST 2023
name = task0 ,endTime=Sun Mar 12 12:52:26 CST 2023 ]
...
**/2.2 源码分析:
Timer内两个核心属性:
public class Timer {
private final TaskQueue queue = new TaskQueue();
private final TimerThread thread = new TimerThread(queue);
//构造器
public Timer(String name) {
thread.setName(name);
thread.start();
}
...
}一个小顶堆TaskQueue存放Timertask.
一个工作线程TimerThread循环执行不断检查queue里的任务并执行,new Timer()时就开始跑,如果检查queue空则先令队列wait,schedule往queue添加元素时会唤醒队列。
schedule方法

schedule方法
schedule(TimerTask task, Date firstTime, long period) 执行时间firstTime只是预设时间,具体执行时间取决于上一个任务结束时间
public void schedule(TimerTask task, Date firstTime, long period) {
if (period <= 0)
throw new IllegalArgumentException("Non-positive period.");
sched(task, firstTime.getTime(), -period);
} private void sched(TimerTask task, long time, long period) {
if (time < 0)
throw new IllegalArgumentException("Illegal execution time.");
// Constrain value of period sufficiently to prevent numeric
// overflow while still being effectively infinitely large.
if (Math.abs(period) > (Long.MAX_VALUE >> 1))
period >>= 1;
//双重锁
synchronized(queue) {
if (!thread.newTasksMayBeScheduled)
throw new IllegalStateException("Timer already cancelled.");
synchronized(task.lock) {
if (task.state != TimerTask.VIRGIN)
throw new IllegalStateException(
"Task already scheduled or cancelled");
//Timer.TimerThread执行时会使用到nextExecutionTime
//!!!! 注意到此时的nextExecutionTime没有加period !!!!!!
task.nextExecutionTime = time;
task.period = period;
task.state = TimerTask.SCHEDULED;
}
//将任务添加入queue小顶堆,并且唤醒queue
queue.add(task);
if (queue.getMin() == task)
queue.notify();
}
}
Timer.TimerThread执行任务
private void mainLoop() {
while (true) {
try {
TimerTask task;
boolean taskFired;
synchronized(queue) {
// 等待队列非空
while (queue.isEmpty() && newTasksMayBeScheduled)
queue.wait();
if (queue.isEmpty())
break; // Queue is empty and will forever remain; die
// 队列非空,取出queue小顶堆根节点
long currentTime, executionTime;
task = queue.getMin();
synchronized(task.lock) {
if (task.state == TimerTask.CANCELLED) {
//取出后根节点后删除queue中根节点
queue.removeMin();
continue; // No action required, poll queue again
}
currentTime = System.currentTimeMillis();
executionTime = task.nextExecutionTime;//未加period的期望执行时间
if (taskFired = (executionTime<=currentTime)) {
if (task.period == 0) { // Non-repeating, remove
//period =0 代表不周期执行,删除任务
queue.removeMin();
task.state = TimerTask.EXECUTED;
} else { // Repeating task, reschedule
//修改时间后作为!下次执行的节点!加入queue
queue.rescheduleMin(
task.period<0 ? currentTime - task.period
: executionTime + task.period);
}
}
}
//期望的执行时间 > 当前时间时 -> 当前执行线程休息一会
if (!taskFired) // Task hasn't yet fired; wait
queue.wait(executionTime - currentTime);
}
//期望的执行时间 < 当前时间时 -> 运行当前任务
//意味着 当前任务执行时间<period时,节点运行时间会连续
//因此任务执行的时间间隔主要由firstTime和任务运行时间决定
if (taskFired) // Task fired; run it, holding no locks
task.run();
} catch(InterruptedException e) {
}
}
}
}Timer问题
schedule方法添加任务时必须传入固定的时间firstTime,依赖系统时间,没有相对写法。比如每周周一执行这种相对时间无法执行。
由于Timer内工作线程是单线程,所以启动时间相同的任务无法同时启动,必须等待上一个任务执行完成,所以任务不是严格按照预设的间隔时间period执行,具体执行时间取决于任务执行时长。
3. 定时任务线程池
3.1 测试案例
public static void main(String[] args) {
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(10);
for (int i = 0; i < 3;i++) {
scheduledThreadPool.scheduleAtFixedRate(new MyTimerTask("task"+i),0,4, TimeUnit.SECONDS);
}
}
/**
测试结果
[ name = task1 ,startTime=Sun Mar 12 13:03:25 CST 2023
[ name = task2 ,startTime=Sun Mar 12 13:03:25 CST 2023
[ name = task0 ,startTime=Sun Mar 12 13:03:25 CST 2023
name = task1 ,endTime=Sun Mar 12 13:03:28 CST 2023 ]
name = task0 ,endTime=Sun Mar 12 13:03:28 CST 2023 ]
name = task2 ,endTime=Sun Mar 12 13:03:28 CST 2023 ]
[ name = task0 ,startTime=Sun Mar 12 13:03:29 CST 2023
[ name = task2 ,startTime=Sun Mar 12 13:03:29 CST 2023
[ name = task1 ,startTime=Sun Mar 12 13:03:29 CST 2023
name = task2 ,endTime=Sun Mar 12 13:03:32 CST 2023 ]
name = task1 ,endTime=Sun Mar 12 13:03:32 CST 2023 ]
name = task0 ,endTime=Sun Mar 12 13:03:32 CST 2023 ]
**/可以看出,由于多线程的原因,相同启动时间的任务的执行不需要等待上一次任务执行完成,三个任务可以严格按照启动时间同时执行,所以当核心线程数大于任务数时,启动时间之间间隔 = 预设的period。
3.2 Leader-Follower模式
在Leader-follower线程模型中每个线程有三种模式,leader,follower, processing。
在Leader-follower线程模型一开始会创建一个线程池,并且会选取一个线程作为leader线程,leader线程负责监听网络请求,其它线程为follower处于waiting状态,当leader线程接受到一个请求后,会释放自己作为leader的权利,然后从follower线程中选择一个线程进行激活,然后激活的线程被选择为新的leader线程作为服务监听,然后老的leader则负责处理自己接受到的请求(现在老的leader线程状态变为了processing),处理完成后,状态从processing转换为follower
可知这种模式下接受请求和进行处理使用的是同一个线程,这避免了线程上下文切换和线程通讯数据拷贝。
优点:避免没必要的唤醒和阻塞操作,更高效和节省资源。
4. Quartz使用
4.1 quick-start
三个核心类
JobDetail 任务类
Trigger 触发器
Scheduler 调度器
mavne坐标
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.1.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-autoconfigure</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
</dependencies>Java代码
public class MyJob implements Job {
@Override public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
try {
System.out.println("[ MyJob execute : startTime="+new Date());
Thread.sleep(3000);
System.out.println(" MyJob end : endTime="+new Date()+" ]");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}public class QuartzTest {
public static void main(String[] args) throws SchedulerException {
//1. create jobs
JobDetail jobDetail = JobBuilder.newJob(MyJob.class)
.withIdentity("job1","jobGroup1")
.build();
//2. create triggers
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("trigger","triggerGroup")
.startNow()
.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(4).repeatForever()
)
.build();
//3. create scheduler,add Job、trigger,execute
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
scheduler.scheduleJob(jobDetail,trigger);
scheduler.start();
}
}测试结果
[ MyJob execute : startTime=Sun Mar 12 17:07:43 CST 2023
MyJob end : endTime=Sun Mar 12 17:07:46 CST 2023 ]
17:07:47.341 [DefaultQuartzScheduler_QuartzSchedulerThread] DEBUG org.quartz.simpl.PropertySettingJobFactory - Producing instance of Job 'jobGroup1.job1', class=cn.yihui.MyJob
17:07:47.342 [DefaultQuartzScheduler_QuartzSchedulerThread] DEBUG org.quartz.core.QuartzSchedulerThread - batch acquisition of 1 triggers
17:07:47.342 [DefaultQuartzScheduler_Worker-2] DEBUG org.quartz.core.JobRunShell - Calling execute on job jobGroup1.job1
[ MyJob execute : startTime=Sun Mar 12 17:07:47 CST 2023
MyJob end : endTime=Sun Mar 12 17:07:50 CST 2023 ]
17:07:51.341 [DefaultQuartzScheduler_QuartzSchedulerThread] DEBUG org.quartz.simpl.PropertySettingJobFactory - Producing instance of Job 'jobGroup1.job1', class=cn.yihui.MyJob
17:07:51.341 [DefaultQuartzScheduler_QuartzSchedulerThread] DEBUG org.quartz.core.QuartzSchedulerThread - batch acquisition of 1 triggers
17:07:51.341 [DefaultQuartzScheduler_Worker-3] DEBUG org.quartz.core.JobRunShell - Calling execute on job jobGroup1.job1
[ MyJob execute : startTime=Sun Mar 12 17:07:51 CST 2023
MyJob end : endTime=Sun Mar 12 17:07:54 CST 2023 ]
17:07:55.342 [DefaultQuartzScheduler_QuartzSchedulerThread] DEBUG org.quartz.simpl.PropertySettingJobFactory - Producing instance of Job 'jobGroup1.job1', class=cn.yihui.MyJob
17:07:55.342 [DefaultQuartzScheduler_QuartzSchedulerThread] DEBUG org.quartz.core.QuartzSchedulerThread - batch acquisition of 1 triggers
17:07:55.342 [DefaultQuartzScheduler_Worker-4] DEBUG org.quartz.core.JobRunShell - Calling execute on job jobGroup1.job1
[ MyJob execute : startTime=Sun Mar 12 17:07:55 CST 2023
MyJob end : endTime=Sun Mar 12 17:07:58 CST 2023 ]
...严格按照间隔时间执行
4.2 JobDataMap
Java代码
public class QuartzTest {
public static void main(String[] args) throws SchedulerException {
//1. create jobs
JobDetail jobDetail = JobBuilder.newJob(MyJob.class)
.withIdentity("job1","jobGroup1")
.usingJobData("testJobKey","testJobValue")
.usingJobData("test","valueJob")
.build();
//2. create triggers
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("trigger","triggerGroup")
.usingJobData("testTriggerKey","testTriggerValue")
.usingJobData("test","valueTrigger")
.startNow()
.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(4).repeatForever()
)
.build();
//3. create scheduler,add Job、trigger,execute
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
scheduler.scheduleJob(jobDetail,trigger);
scheduler.start();
}
}public class MyJob implements Job {
@Override public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
try {
System.out.println("[ MyJob execute : startTime="+new Date());
Thread.sleep(3000);
JobDataMap jobMap = jobExecutionContext.getJobDetail().getJobDataMap();
JobDataMap triggerMap = jobExecutionContext.getTrigger().getJobDataMap();
System.out.println(jobMap.get("testJobKey"));
System.out.println(triggerMap.get("testTriggerKey"));
//合并map后重复key时,trigger的会将job的覆盖。
System.out.println(jobExecutionContext.getMergedJobDataMap().getString("test"));
System.out.println(" MyJob end : endTime="+new Date()+" ]");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}测试结果
[ MyJob execute : startTime=Sun Mar 12 17:29:33 CST 2023
testJobValue
testTriggerValue
valueTrigger
MyJob end : endTime=Sun Mar 12 17:29:36 CST 2023 ]4.3 Job并发及持久化
Quartz为了并发,每次执行的jobDetail和Job实例都是不同的实例对象,相对应的JobDataMap也是不同的实例对象。
@DisallowConcurrentExecution : 禁止并发执行
@PersistJobDataAfterExecution : 持久化JobDataMap 对TriggerDataMap无效
4.4 触发器
...未完待续
4.5 SpringBoot整合Quartz
...未完待续
[框架应用系列:Quartz快速上手] Java定时任务解决方案之Quartz集群的更多相关文章
- 【Kubernetes 系列四】Kubernetes 实战:管理 Hello World 集群
目录 1. 创建集群 1.1. 安装 kubectl 1.1.1. 安装 kubectl 到 Linux 1.1.2. 安装 kubectl 到 macOS 1.1.3. 安装 kubectl 到 W ...
- Rancher系列文章-Rancher v2.6使用脚本实现导入集群
概述 最近在玩 Rancher, 先从最基本的功能玩起, 目前有几个已经搭建好的 K8S 集群, 需要批量导入, 发现官网已经有批量导入的文档了. 根据 Rancher v2.6 进行验证微调后总结经 ...
- Quartz快速上手
快速上手你需要干啥: 下载Quartz 安装Quartz 根据你的需要来配置Quartz 开始一个示例应用 下载和安装 The Quartz JAR Files The main Quartz lib ...
- 【ELK解决方案】ELK集群+RabbitMQ部署方案以及快速开发RabbitMQ生产者与消费者基础服务
前言: 大概一年多前写过一个部署ELK系列的博客文章,前不久刚好在部署一个ELK的解决方案,我顺便就把一些基础的部分拎出来,再整合成一期文章.大概内容包括:搭建ELK集群,以及写一个简单的MQ服务. ...
- 基于.NetCore的Redis5.0.3(最新版)快速入门、源码解析、集群搭建与SDK使用【原创】
1.[基础]redis能带给我们什么福利 Redis(Remote Dictionary Server)官网:https://redis.io/ Redis命令:https://redis.io/co ...
- 三分钟快速搭建分布式高可用的Redis集群
这里的Redis集群指的是Redis Cluster,它是Redis在3.0版本正式推出的专用集群方案,有效地解决了Redis分布式方面的需求.当单机内存.并发.流量等遇到瓶颈的时候,可以采用这种Re ...
- Java+大数据开发——Hadoop集群环境搭建(二)
1. MAPREDUCE使用 mapreduce是hadoop中的分布式运算编程框架,只要按照其编程规范,只需要编写少量的业务逻辑代码即可实现一个强大的海量数据并发处理程序 2. Demo开发--wo ...
- 第十节: 利用SQLServer实现Quartz的持久化和双机热备的集群模式 :
背景: 默认情况下,Quartz.Net作业是持久化在内存中的,即 quartz.jobStore.type = "Quartz.Simpl.RAMJobStore, Quartz" ...
- Hadoop学习笔记1 - 使用Java API访问远程hdfs集群
转载请标注原链接 http://www.cnblogs.com/xczyd/p/8570437.html 2018年3月从新司重新起航了.之前在某司过了的蛋疼三个月,也算给自己放了个小假了. 第一个小 ...
- Java+大数据开发——Hadoop集群环境搭建(一)
1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主要有 NameNode / DataN ...
随机推荐
- 【吐血经验】在 windows 上安装 spark 遇到的一些坑 | 避坑指南
在 windows 上安装 spark 遇到的一些坑 | 避坑指南 最近有个活:给了我一个阿里云桌面(windows 10系统),让我在上面用 scala + spark 写一些东西. 总是报错不断, ...
- [LC1302] 层数最深叶子节点的和
题目概述 给你一棵二叉树的根节点 root ,请你返回 层数最深的叶子节点的和 . 基本思路 这是一个简单的树的遍历的问题,可以用bfs或者dfs来解题.这里采用dfs来解,在遍历的过程中,只需要用全 ...
- deeplearning4j~实现简单模型训练和测试
DeepLearning4j (DL4J) 是一个开源的深度学习库,专为 Java 和 Scala 设计.它可以用于构建.训练和部署深度学习模型.以下是关于如何使用 DL4J 的基本指南以及一个简单的 ...
- Phi小模型开发教程:用C#开发本地部署AI聊天工具,只需CPU,不需要GPU,3G内存就可以运行,不输GPT-3.5
大家好,我是编程乐趣. 行业诸多大佬一直在说:"2025年将是AI应用元年",虽然说大佬的说法不一定对,但AI趋势肯定没错的. 对于我们程序员来说,储备AI应用开发技能,不管对 ...
- Kotlin:【对象】object关键字、对象表达式、伴生对象、嵌套类、数据类、copy、解构声明、使用数据类的条件、运算符重载、枚举类、代数数据类型、密封类
- arthas进行java应用不停服务情况下的class文件热部署更新
我们在工作的过程中会遇到java应用已经部署或升级投入使用,发现某个单元文件有bug需要修正,但是客户的应用目前不能停止,而且不能因为一个非致命的bug来进行整个平台的一次升级.我们需要进行单文件的更 ...
- 使用 SOUI 开发高 DPI 桌面应用程序[转载]
原文:使用 SOUI 开发高 DPI 桌面应用程序_吹泡泡的小猫的博客-CSDN博客 补充说明:soui3以后版本对dpi的支持更完善了,用起来也更简单了. 1 应用程序感知 DPI 变化 在 Win ...
- linux mint安装eclipse
安装eclipse之前需要先安装配置jdk,参考上面, 一.Eclipse的下载与安装 1.首先,在Eclipse的官网中下载最新版的Luna SR2http://www.eclipse.org/do ...
- Flink内存解释
一.JobManager内存 JobManager 是 Flink 集群的控制单元. 它由三种不同的组件组成:ResourceManager.Dispatcher 和每个正在运行作业的 JobMast ...
- IPTools for .NET:快速查询全球IP信息
IPTools 是一个用于快速查询全球 IP 地址信息的库,支持国内和国际 IP 查询,提供详细的地理位置信息(如国家.省份.城市)以及经纬度等数据. 1. IPTools.China IPTools ...