大数据之路Week08_day06 (Zookeeper搭建)
Zookeeper集群搭建
在本文中Zookeeper节点个数(奇数)为3个。Zookeeper默认对外提供服务的端口号2181 。Zookeeper集群内部3个节点之间通信默认使用2888:3888
192.168.129.101 192.168.129.102 192.168.129.103
下载zookeeper对应的tar包

分别上传tar包到192.168.0.217 192.168.0.218 192.168.0.219

在101、102、103三个zookeeper节点上分别执行下行指令,然后将解压后的文件名zookeeper-3.4.10修改为zookeeper。
tar -zxvf zookeeper-3.4.10.tar.gz -C /usr/local/
在三个zookeeper节点配置环境变量
vim /etc/profile
添加export ZOOKEEPER_HOME=/usr/local/zookeeper
在path中添加$ZOOKEEPER_HOME/bin
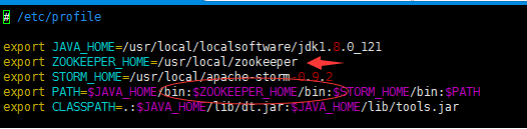
执行source /etc/profile 使环境变量立即生效
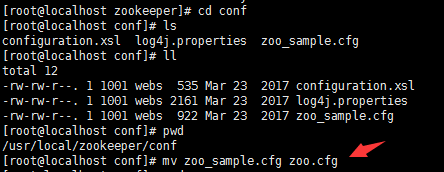
修改zookeeper中conf目录下的zoo_sample.cfg为zoo.cfg
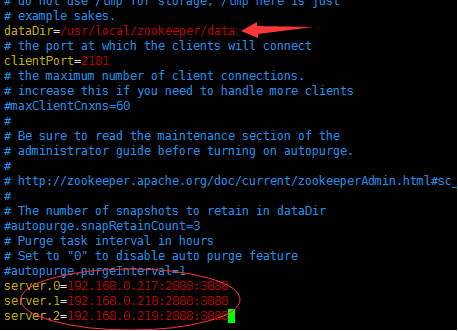
修改三个zookeeper节点中的zoo.cfg文件,修改dataDir,添加server.0、server.1、server.2
在zookeeper目录下,创建data目录。在3个zookeeper节点中data目录下分别创建myid文件,并分别添加内容0、1、2



启动zookeeper

每台节点都需要启动
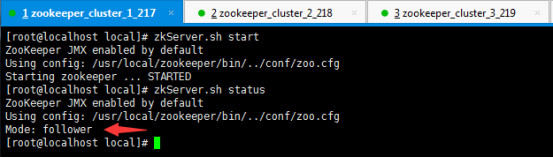
zkServer.sh start
zkServer.sh status
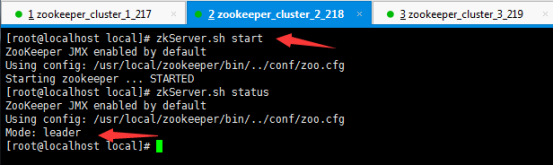

在zookeeper中任意一个节点,执行指令zkCli.sh

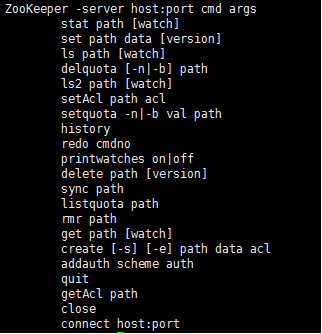
执行指令zkCli.sh help ,查看帮助信息(到这,就说明搭建成功)
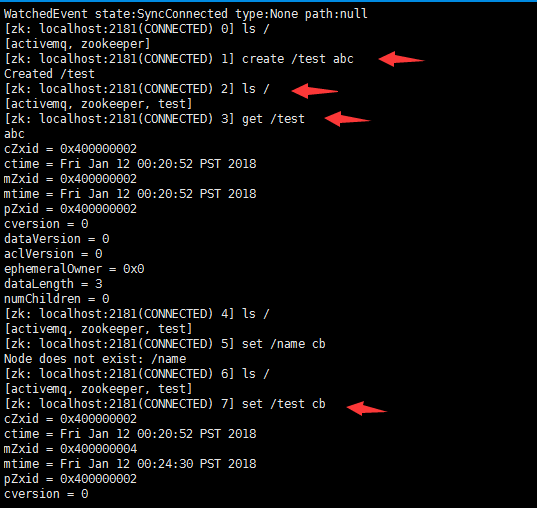
ls / 查找根目录
create /test abc 创建节点并赋值
get /test 获取指定节点的值
set /test cb 设置已存在节点的值
rmr /test 递归删除节点
delete /test/test01 删除不存在子节点的节点
大数据之路Week08_day06 (Zookeeper搭建)的更多相关文章
- 大数据之路- Hadoop环境搭建(Linux)
前期部署 1.JDK 2.上传HADOOP安装包 2.1官网:http://hadoop.apache.org/ 2.2下载hadoop-2.6.1的这个tar.gz文件,官网: https://ar ...
- 分享知识-快乐自己:大数据(hadoop)环境搭建
大数据 hadoop 环境搭建: 一):大数据(hadoop)初始化环境搭建 二):大数据(hadoop)环境搭建 三):运行wordcount案例 四):揭秘HDFS 五):揭秘MapReduce ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- 《OD大数据实战》Hive环境搭建
一.搭建hadoop环境 <OD大数据实战>hadoop伪分布式环境搭建 二.Hive环境搭建 1. 准备安装文件 下载地址: http://archive.cloudera.com/cd ...
- 大数据平台常见异常-zookeeper
本文主要阐述大数据平台环境zookeeper常见异常和解决方案 1.Connection reset by peer异常 异常说明 我们现在项目有个任务OneMinuteDataSync是用spark ...
- 大数据学习路线:Zookeeper集群管理与选举
大数据技术的学习,逐渐成为很多程序员的必修课,因为趋势也是因为自己的职业生涯.在各个技术社区分享交流成为很多人学习的方式,今天很荣幸给我们分享一些大数据基础知识,大家可以一起学习! 1.集群机器监控 ...
- 胖子哥的大数据之路(6)- NoSQL生态圈全景介绍
引言: NoSQL高级培训课程的基础理论篇的部分课件,是从一本英文原著中做的摘选,中文部分参考自互联网.给大家分享. 正文: The NoSQL Ecosystem 目录 The NoSQL Eco ...
- 大数据之路day01_1--Java下载、安装等配置
从今天开始,我就正式的走上大数据的道路了,如果说我为啥要去学习大数据,可能我的初衷是以后可以接触到人工智能方面的技术,后来在自学的过程中发现,学习人工智能,需要扎实的算法,以及对大量数据的处理,再者, ...
- 大数据之路week06--day07(Hadoop生态圈的介绍)
Hadoop 基本概念 一.Hadoop出现的前提环境 随着数据量的增大带来了以下的问题 (1)如何存储大量的数据? (2)怎么处理这些数据? (3)怎样的高效的分析这些数据? (4)在数据增长的情况 ...
- 大数据之路week04--day06(I/O流阶段一 之异常)
从这节开始,进入对I/O流的系统学习,I/O流在往后大数据的学习道路上尤为重要!!!极为重要,必须要提起重视,它与集合,多线程,网络编程,可以说在往后学习或者是工作上,起到一个基石的作用,没了地基,房 ...
随机推荐
- Qt/C++开发经验小技巧301-305
从Qt5.2版本开始,QLineEdit文本框控件提供了setClearButtonEnabled函数用于是否开启右侧的关闭按钮,这种控件非常常见,比如还可以增加个搜索按钮,怎么添加呢,在5.2版本以 ...
- Qt编写ffmpeg本地摄像头显示(16路本地摄像头占用3.2%CPU)
一.前言 内核ffmpeg除了支持本地文件.网络文件.各种视频流播放以外,还支持打开本地摄像头,和正常的解析流程一致,唯一的区别就是在avformat_open_input第三个参数传入个AVInpu ...
- [转]Bundle Adjustment简述
原文链接:https://optsolution.github.io/archives/58892.html或https://blog.csdn.net/optsolution/article/det ...
- [转]C# PowerPoint操作的基本用法
using System; using System.Collections.Generic; using System.Linq; using System.Text; using OFFICECO ...
- WPF 透明背景窗体
<Window x:Class="WpfApplication8.MainWindow" xmlns="http://schemas.microsoft.com/w ...
- 用于决策的世界模型 -- 论文 World Models (2018) & PlaNet (2019) 讲解
参考资料: [2411.14499] Understanding World or Predicting Future? A Comprehensive Survey of World Models ...
- Netty-快速入门
---------------------------------------------------- netty是什么? Netty is an asynchronous event-driven ...
- postman环境设置以及参数传递
通常一个公司项目有不同的环境(开发环境,测试环境,上线环境),在做测试时候,有可能会遇到接口改变之类的,postman保存了很多接口,想要再测试局需要多次修改域名或者端口,这个时候就需要配置环境 1. ...
- superset 1.3 hello world 开发实录
参考网址: https://superset.apache.org/docs/installation/building-custom-viz-plugins 实际操作: 因为内容是从hub上下载的: ...
- linux:lamp环境
关于LAMP LAMP搭建 安装php和Apache 先装php,因为安装php有apache的依赖包 yum install php 启动Apache service httpd start 启动成 ...