Flink-v1.12官方网站翻译-P010-Fault Tolerance via State Snapshots
通过状态快照进行容错
状态后台
Flink管理的键控状态是一种碎片化的、键/值存储,每项键控状态的工作副本都被保存在负责该键的任务管理员的本地某处。操作员的状态也被保存在需要它的机器的本地。Flink会定期对所有状态进行持久化快照,并将这些快照复制到某个更持久的地方,比如分布式文件系统。
在发生故障的情况下,Flink可以恢复你的应用程序的完整状态,并恢复处理,就像什么都没有发生过一样。
Flink管理的这种状态被存储在状态后端中。状态后端有两种实现--一种是基于RocksDB的,它是一个嵌入式的键/值存储,将其工作状态保存在磁盘上;另一种是基于堆的状态后端,将其工作状态保存在内存中,在Java堆上。这种基于堆的状态后端有两种口味:将其状态快照持久化到分布式文件系统的FsStateBackend和使用JobManager的堆的MemoryStateBackend。
| 名称 | 工作状态 | 状态备份 | 快照 |
|---|---|---|---|
| RocksDB状态备份 | 本地磁盘(临时文件夹) | 分布式文件系统 | 全量/增量 |
|
|||
| Fs状态备份 | JVM 堆 | 分布式文件系统 | 全量 |
|
|||
| Memory状态备份 | JVM 堆 | JobManager JVM 堆 | 全量 |
|
|||
当处理保存在基于堆的状态后端的状态时,访问和更新涉及到在堆上读写对象。但是对于保存在RocksDBStateBackend中的对象,访问和更新涉及到序列化和反序列化,因此成本更高。但是使用RocksDB可以拥有的状态数量只受限于本地磁盘的大小。还要注意的是,只有RocksDBStateBackend能够进行增量快照,这对于有大量缓慢变化的状态的应用来说是一个很大的好处。
所有这些状态后端都能够进行异步快照,这意味着它们可以在不妨碍正在进行的流处理的情况下进行快照。
状态快照
定义
- 快照--一个通用术语,指的是一个Flink作业状态的全局、一致的图像。快照包括进入每个数据源的指针(例如,进入文件或Kafka分区的偏移),以及来自每个作业的有状态操作符的状态副本,这些操作符是在处理了所有事件后产生的,直到源中的这些位置。
- 检查点--Flink为了能够从故障中恢复而自动拍摄的快照。检查点可以是增量的,并为快速恢复进行了优化。
- 外部化检查点--通常检查点不打算被用户操纵。Flink只在作业运行时保留n个最近的检查点(n是可配置的),并在作业取消时删除它们。但你也可以配置它们被保留,在这种情况下,你可以手动从它们恢复。
- 保存点--由用户(或API调用)手动触发的快照,用于某些操作目的,如有状态的重新部署/升级/重新缩放操作。保存点始终是完整的,并为操作的灵活性进行了优化。
状态快照如何运作?
Flink使用了Chandy-Lamport算法的一个变体,称为异步障碍快照。
当检查点协调器(作业管理器的一部分)指示任务管理器开始检查点时,它让所有的源记录它们的偏移量,并在它们的流中插入编号的检查点障碍。这些障碍物在作业图中流动,表明每个检查点前后的流的部分。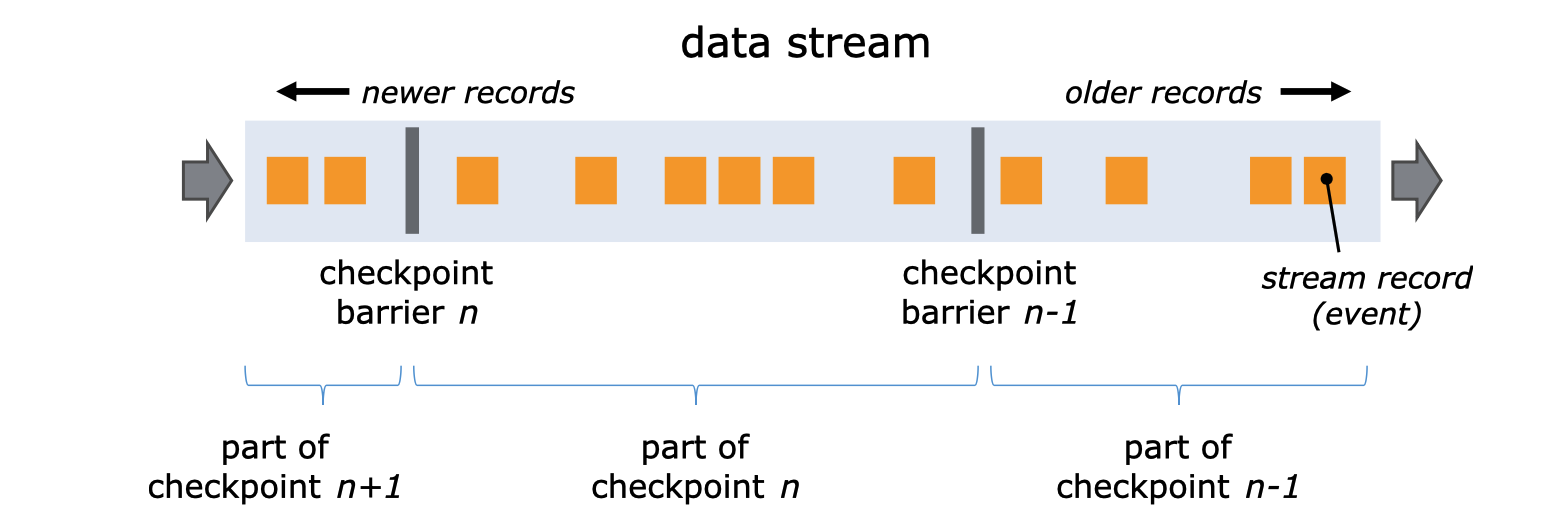
检查点n将包含每个操作者的状态,这些状态是由于消耗了检查点障碍n之前的每个事件,而没有消耗它之后的任何事件。
当作业图中的每个操作者接收到这些障碍之一时,它就会记录其状态。具有两个输入流(如CoProcessFunction)的操作者执行屏障对齐,这样快照将反映消耗两个输入流的事件所产生的状态,直到(但不超过)两个屏障。

Flink的状态后端使用复制-写机制,允许在异步快照状态的旧版本时,流处理不受阻碍地继续。只有当快照被持久化后,这些旧版本的状态才会被垃圾回收。
确切的一次保证
当流处理应用中出现问题时,有可能出现丢失,或者重复的结果。在Flink中,根据你对应用的选择和你运行它的集群,这些结果中的任何一种都是可能的。
- Flink不努力从故障中恢复(最多一次)。
- 没有任何损失,但您可能会遇到重复的结果(至少一次)。
- 没有任何东西丢失或重复(精确地一次)。
鉴于Flink通过倒带和重放源数据流从故障中恢复,当理想情况被描述为精确一次时,这并不意味着每个事件都将被精确处理一次。相反,它意味着每一个事件都会对Flink所管理的状态产生一次确切的影响。
Barrier alignment只需要用于提供精确的一次保证。如果你不需要这个,你可以通过配置Flink使用CheckpointingMode.AT_LEAST_ONCE来获得一些性能,这样做的效果是禁用屏障对齐。
端到端精准一次
为了实现端到端精确的一次,让源的每个事件精确地影响汇,以下几点必须是真的。
- 你的源必须是可重播的,并且
- 你的汇必须是事务性的(或幂等的)
实践
Flink Operations Playground包括观察故障和恢复的部分。
下一步阅读
- Stateful Stream Processing
- State Backends
- Fault Tolerance Guarantees of Data Sources and Sinks
- Enabling and Configuring Checkpointing
- Checkpoints
- Savepoints
- Tuning Checkpoints and Large State
- Monitoring Checkpointing
- Task Failure Recovery
Flink-v1.12官方网站翻译-P010-Fault Tolerance via State Snapshots的更多相关文章
- Flink-v1.12官方网站翻译-P021-State & Fault Tolerance-overview
状态和容错 在本节中,您将了解Flink为编写有状态程序提供的API.请看一下Stateful Stream Processing来了解有状态流处理背后的概念. 下一步去哪里? Working wit ...
- Flink-v1.12官方网站翻译-P028-Custom Serialization for Managed State
管理状态的自定义序列化 本页面的目标是为需要使用自定义状态序列化的用户提供指导,涵盖了如何提供自定义状态序列化器,以及实现允许状态模式演化的序列化器的指南和最佳实践. 如果你只是简单地使用Flink自 ...
- Flink-v1.12官方网站翻译-P016-Flink DataStream API Programming Guide
Flink DataStream API编程指南 Flink中的DataStream程序是对数据流实现转换的常规程序(如过滤.更新状态.定义窗口.聚合).数据流最初是由各种来源(如消息队列.套接字流. ...
- Flink-v1.12官方网站翻译-P005-Learn Flink: Hands-on Training
学习Flink:实践培训 本次培训的目标和范围 本培训介绍了Apache Flink,包括足够的内容让你开始编写可扩展的流式ETL,分析和事件驱动的应用程序,同时省略了很多(最终重要的)细节.本书的重 ...
- Flink-v1.12官方网站翻译-P025-Queryable State Beta
可查询的状态 注意:可查询状态的客户端API目前处于不断发展的状态,对所提供接口的稳定性不做保证.在即将到来的Flink版本中,客户端的API很可能会有突破性的变化. 简而言之,该功能将Flink的托 ...
- Flink-v1.12官方网站翻译-P002-Fraud Detection with the DataStream API
使用DataStream API进行欺诈检测 Apache Flink提供了一个DataStream API,用于构建强大的.有状态的流式应用.它提供了对状态和时间的精细控制,这使得高级事件驱动系统的 ...
- Flink-v1.12官方网站翻译-P015-Glossary
术语表 Flink Application Cluster Flink应用集群是一个专用的Flink集群,它只执行一个Flink应用的Flink作业.Flink集群的寿命与Flink应用的寿命绑定. ...
- Flink-v1.12官方网站翻译-P008-Streaming Analytics
流式分析 事件时间和水印 介绍 Flink明确支持三种不同的时间概念. 事件时间:事件发生的时间,由产生(或存储)该事件的设备记录的时间 摄取时间:Flink在摄取事件时记录的时间戳. 处理时间:您的 ...
- Flink-v1.12官方网站翻译-P004-Flink Operations Playground
Flink操作训练场 在各种环境中部署和操作Apache Flink的方法有很多.无论这种多样性如何,Flink集群的基本构件保持不变,类似的操作原则也适用. 在这个操场上,你将学习如何管理和运行Fl ...
随机推荐
- spark的 structStreaming 一些介绍
转发 https://www.toutiao.com/a6696339998905467403/?tt_from=mobile_qq&utm_campaign=client_share& ...
- [从源码学设计]蚂蚁金服SOFARegistry之续约和驱逐
[从源码学设计]蚂蚁金服SOFARegistry之续约和驱逐 目录 [从源码学设计]蚂蚁金服SOFARegistry之续约和驱逐 0x00 摘要 0x01 业务范畴 1.1 失效剔除 1.2 服务续约 ...
- HAProxy + keepalived 高可用集群代理
HAProxy + keepalived # 1 安装keepalived: yum install keepalived -y # 2 修改KEEPalived配置文件: vim /etc/keep ...
- python中hmac模块的使用
hmac(hex-based message authentication code)算法在计算哈希的过程中混入了key(实际上就是加盐),和hashlib模块中的普通加密算法相比,它能够防止密码被撞 ...
- 同步alv的前端显示和输出内表中的数据
在使用CL_GUI_ALV_GRID显示报表的时候,当我们使用了checkbox的时候,或者是有可编辑的字段,当我们 在前段修改了单元格内容的时候,后台的内表并不会自动的更新,此时需要我们调用一个方法 ...
- 探索微软开源Python自动化神器Playwright
相信玩过爬虫的朋友都知道selenium,一个自动化测试的神器工具.写个Python自动化脚本解放双手基本上是常规的操作了,爬虫爬不了的,就用自动化测试凑一凑. 虽然selenium有完备的文档,但也 ...
- Windows下nginx设置开机自启动
第一步:下载 WinSW https://github.com/winsw/winsw/releases/download/v2.10.3/WinSW.NET4.exe 64位系统 https://g ...
- 同一份数据,Redis为什么要存两次
前言 在 Redis 中,有一种数据类型,当在存储的时候会同时采用两种数据结构来进行分别存储,那么 Redis 为什么要这么做呢?这么做会造成同一份数据占用两倍空间吗? 五种基本类型之集合对象 Red ...
- SpringBoot 2.0 中 HikariCP 数据库连接池原理解析
作为后台服务开发,在日常工作中我们天天都在跟数据库打交道,一直在进行各种CRUD操作,都会使用到数据库连接池.按照发展历程,业界知名的数据库连接池有以下几种:c3p0.DBCP.Tomcat JDBC ...
- (08)-Python3之--类和对象
1.定义 类:类是抽象的,一类事物的共性的体现. 有共性的属性和行为. 对象:具体化,实例化.有具体的属性值,有具体做的行为. 一个类 对应N多个对象. 类包含属性以及方法. class 类名: 属 ...