MySQL -- 内部临时表
本文转载自MySQL -- 内部临时表
UNION
UNION语义:取两个子查询结果的并集,重复的行只保留一行
表初始化
CREATE TABLE t1(id INT PRIMARY KEY, a INT, b INT, INDEX(a));
DELIMITER ;;
CREATE PROCEDURE idata()
BEGIN
DECLARE i INT;
SET i=1;
WHILE (i<= 1000) DO
INSERT INTO t1 VALUES (i,i,i);
SET i=i+1;
END WHILE;
END;;
DELIMITER ;
CALL idata();
执行语句
(SELECT 1000 AS f) UNION (SELECT id FROM t1 ORDER BY id DESC LIMIT 2);
mysql> EXPLAIN (SELECT 1000 AS f) UNION (SELECT id FROM t1 ORDER BY id DESC LIMIT 2);
+----+--------------+------------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------+------------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------+
| 1 | PRIMARY | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
| 2 | UNION | t1 | NULL | index | NULL | PRIMARY | 4 | NULL | 2 | 100.00 | Backward index scan; Using index |
| NULL | UNION RESULT | <union1,2> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------+------------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------+
- 第二行的
Key=PRIMARY,Using temporary- 表示在对子查询的结果做
UNION RESULT的时候,使用了临时表
- 表示在对子查询的结果做
UNION RESULT
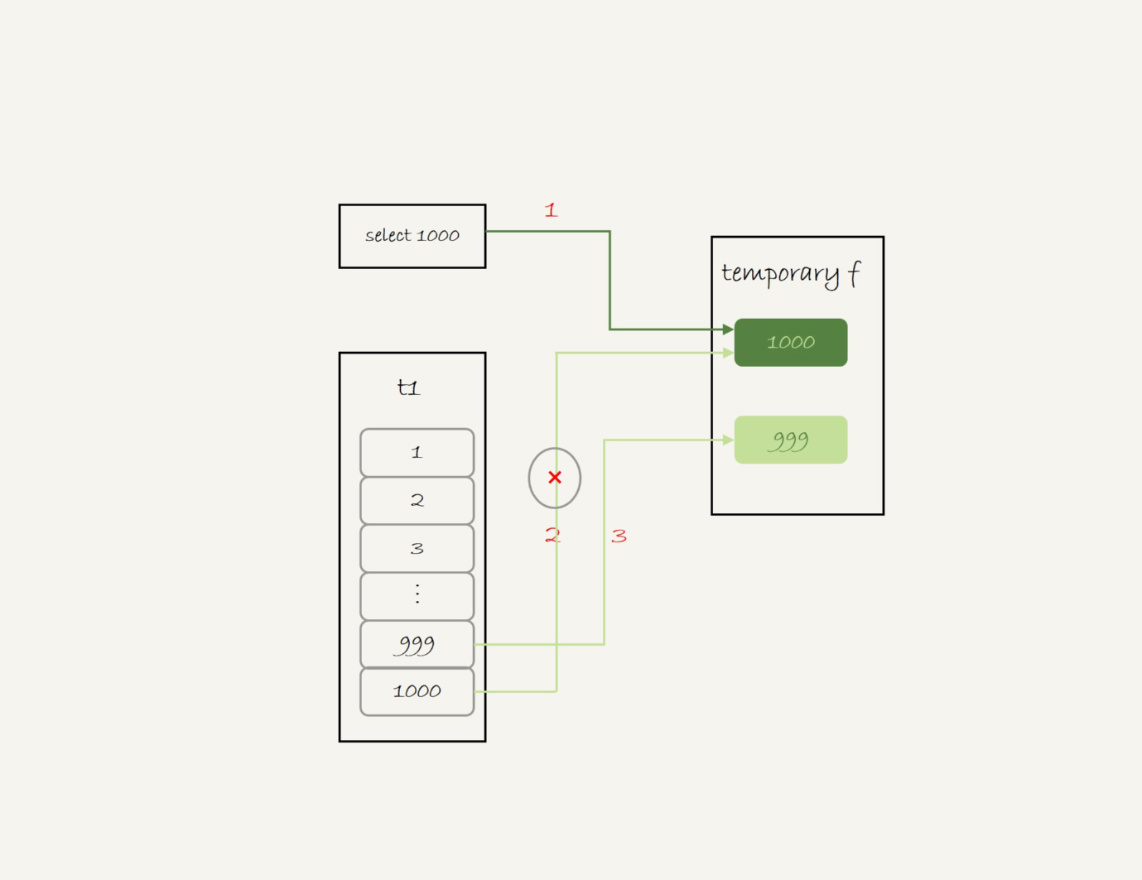
- 创建一个内存临时表,这个内存临时表只有一个整型字段f,并且f为主键
- 执行第一个子查询,得到1000,并存入内存临时表中
- 执行第二个子查询
- 拿到第一行id=1000,试图插入到内存临时表,但由于1000这个值已经存在于内存临时表
- 违反唯一性约束,插入失败,继续执行
- 拿到第二行id=999,插入内存临时表成功
- 拿到第一行id=1000,试图插入到内存临时表,但由于1000这个值已经存在于内存临时表
- 从内存临时表中按行取出数据,返回结果,并删除内存临时表,结果中包含id=1000和id=999两行
- 内存临时表起到了暂存数据的作用,还用到了内存临时表主键id的唯一性约束,实现UNION的语义
UNION ALL
UNION ALL没有去重的语义,一次执行子查询,得到的结果直接发给客户端,不需要内存临时表
mysql> EXPLAIN (SELECT 1000 AS f) UNION ALL (SELECT id FROM t1 ORDER BY id DESC LIMIT 2);
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------+
| 1 | PRIMARY | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
| 2 | UNION | t1 | NULL | index | NULL | PRIMARY | 4 | NULL | 2 | 100.00 | Backward index scan; Using index |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------+
GROUP BY
内存充足
-- 16777216 Bytes = 16 MB
mysql> SHOW VARIABLES like '%tmp_table_size%';
+----------------+----------+
| Variable_name | Value |
+----------------+----------+
| tmp_table_size | 16777216 |
+----------------+----------+
执行语句
-- MySQL 5.6上执行
mysql> EXPLAIN SELECT id%10 AS m, COUNT(*) AS c FROM t1 GROUP BY m;
+----+-------------+-------+-------+---------------+------+---------+------+------+----------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+------+---------+------+------+----------------------------------------------+
| 1 | SIMPLE | t1 | index | PRIMARY,a | a | 5 | NULL | 1000 | Using index; Using temporary; Using filesort |
+----+-------------+-------+-------+---------------+------+---------+------+------+----------------------------------------------+
mysql> SELECT id%10 AS m, COUNT(*) AS c FROM t1 GROUP BY m;
+------+-----+
| m | c |
+------+-----+
| 0 | 100 |
| 1 | 100 |
| 2 | 100 |
| 3 | 100 |
| 4 | 100 |
| 5 | 100 |
| 6 | 100 |
| 7 | 100 |
| 8 | 100 |
| 9 | 100 |
+------+-----+
Using index:表示使用了覆盖索引,选择了索引a,不需要回表Using temporary:表示使用了临时表Using filesort:表示需要排序
执行过程
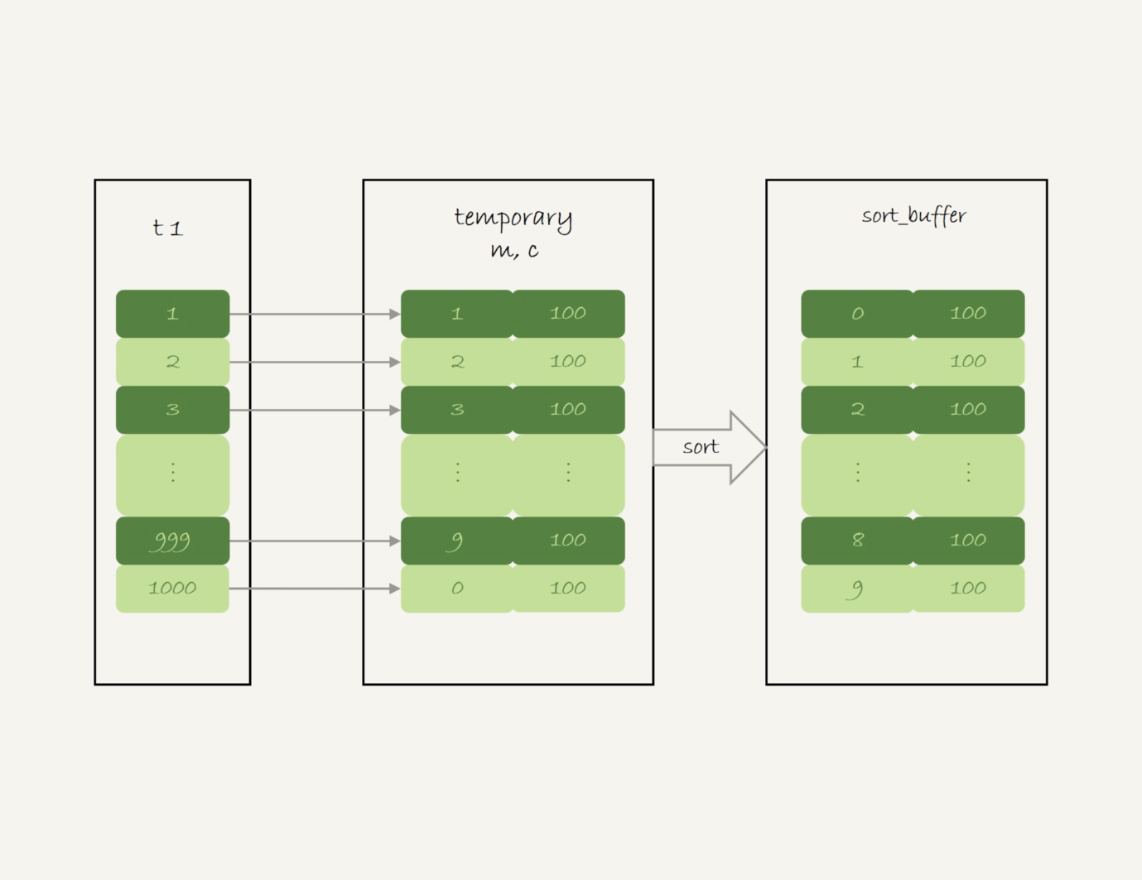
- 创建内存临时表,表里有两个字段m和c,m为主键
- 扫描t1的索引a,依次取出叶子节点上的id值,计算id%10,记为x
- 如果内存临时表中没有主键为x的行,插入一行记录
(x,1) - 如果内存临时表中有主键为x的行,将x这一行的c值加1
- 如果内存临时表中没有主键为x的行,插入一行记录
- 遍历完成后,再根据字段m做排序,得到结果集返回给客户端
排序过程
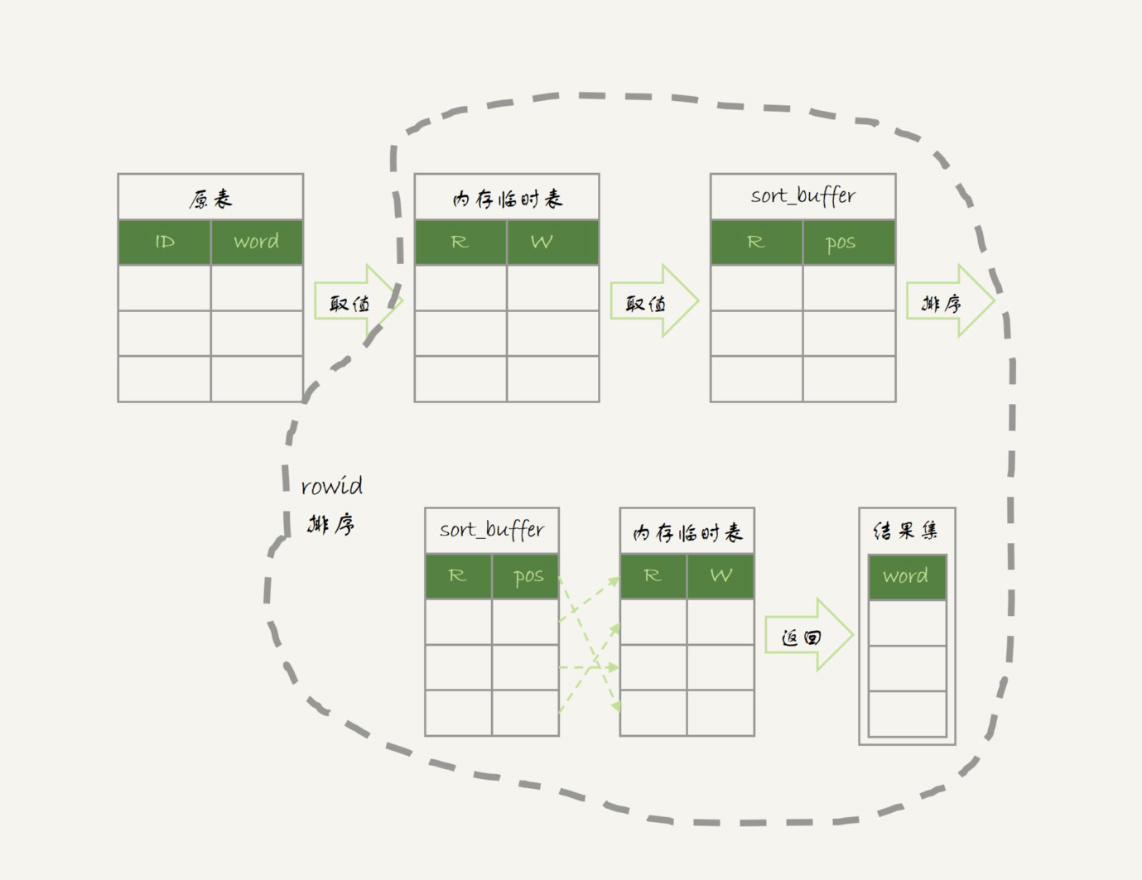
ORDER BY NULL
-- 跳过最后的排序阶段,直接从临时表中取回数据
mysql> EXPLAIN SELECT id%10 AS m, COUNT(*) AS c FROM t1 GROUP BY m ORDER BY NULL;
+----+-------------+-------+-------+---------------+------+---------+------+------+------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+------+---------+------+------+------------------------------+
| 1 | SIMPLE | t1 | index | PRIMARY,a | a | 5 | NULL | 1000 | Using index; Using temporary |
+----+-------------+-------+-------+---------------+------+---------+------+------+------------------------------+
-- t1中的数据是从1开始的
mysql> SELECT id%10 AS m, COUNT(*) AS c FROM t1 GROUP BY m ORDER BY NULL;
+------+-----+
| m | c |
+------+-----+
| 1 | 100 |
| 2 | 100 |
| 3 | 100 |
| 4 | 100 |
| 5 | 100 |
| 6 | 100 |
| 7 | 100 |
| 8 | 100 |
| 9 | 100 |
| 0 | 100 |
+------+-----+
内存不足
SET tmp_table_size=1024;
执行语句
-- 内存临时表的上限为1024 Bytes,但内存临时表不能完全放下100行数据,内存临时表会转成磁盘临时表,默认采用InnoDB引擎
-- 如果t1很大,这个查询需要的磁盘临时表就会占用大量的磁盘空间
mysql> SELECT id%100 AS m, count(*) AS c FROM t1 GROUP BY m ORDER BY NULL LIMIT 10;
+------+----+
| m | c |
+------+----+
| 1 | 10 |
| 2 | 10 |
| 3 | 10 |
| 4 | 10 |
| 5 | 10 |
| 6 | 10 |
| 7 | 10 |
| 8 | 10 |
| 9 | 10 |
| 10 | 10 |
+------+----+
优化方案
优化索引
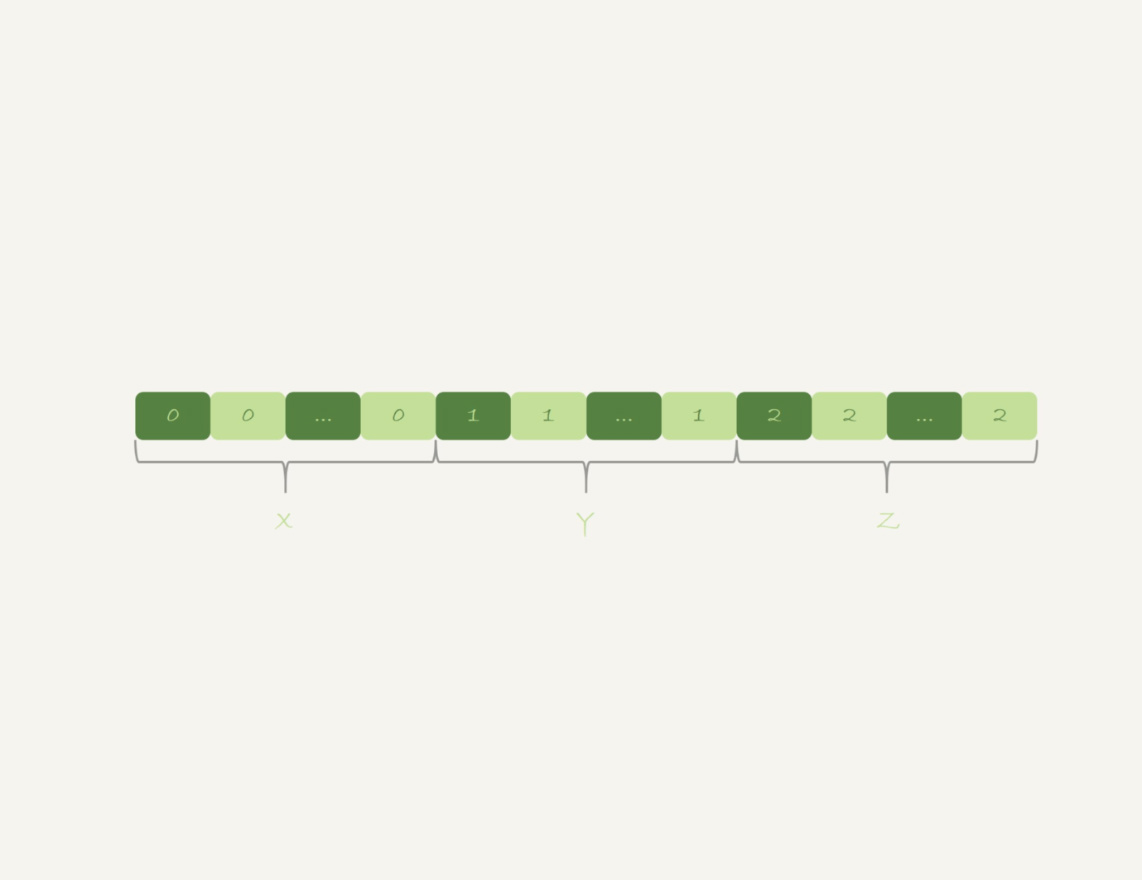
不论使用内存临时表还是磁盘临时表,
GROUP BY都需要构造一个带唯一索引的表,执行代价较高需要临时表的原因:每一行的
id%100是无序的,因此需要临时表,来记录并统计结果如果可以确保输入的数据是有序的,那么计算
GROUP BY时,只需要
从左到右顺序扫描,依次累加即可- 当碰到第一个1的时候,已经累积了X个0,结果集里的第一行为
(0,X) - 当碰到第一个2的时候,已经累积了Y个1,结果集里的第一行为
(1,Y) - 整个过程不需要临时表,也不需要排序
- 当碰到第一个1的时候,已经累积了X个0,结果集里的第一行为
-- MySQL 5.7上执行
ALTER TABLE t1 ADD COLUMN z INT GENERATED ALWAYS AS(id % 100), ADD INDEX(z);
-- 使用了覆盖索引,不需要临时表,也不需要排序
mysql> EXPLAIN SELECT z, COUNT(*) AS c FROM t1 GROUP BY z;
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | index | z | z | 5 | NULL | 1000 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+-------------+
直接排序
- 一个
GROUP BY语句需要放到临时表的数据量特别大,还是按照先放在内存临时表,再退化成磁盘临时表 - 可以直接用磁盘临时表的形式,在
GROUP BY语句中SQL_BIG_RESULT(告诉优化器涉及的数据量很大) - 磁盘临时表原本采用B+树存储,存储效率还不如数组,优化器看到
SQL_BIG_RESULT,会直接用数组存储- 即放弃使用临时表,直接进入排序阶段
执行过程
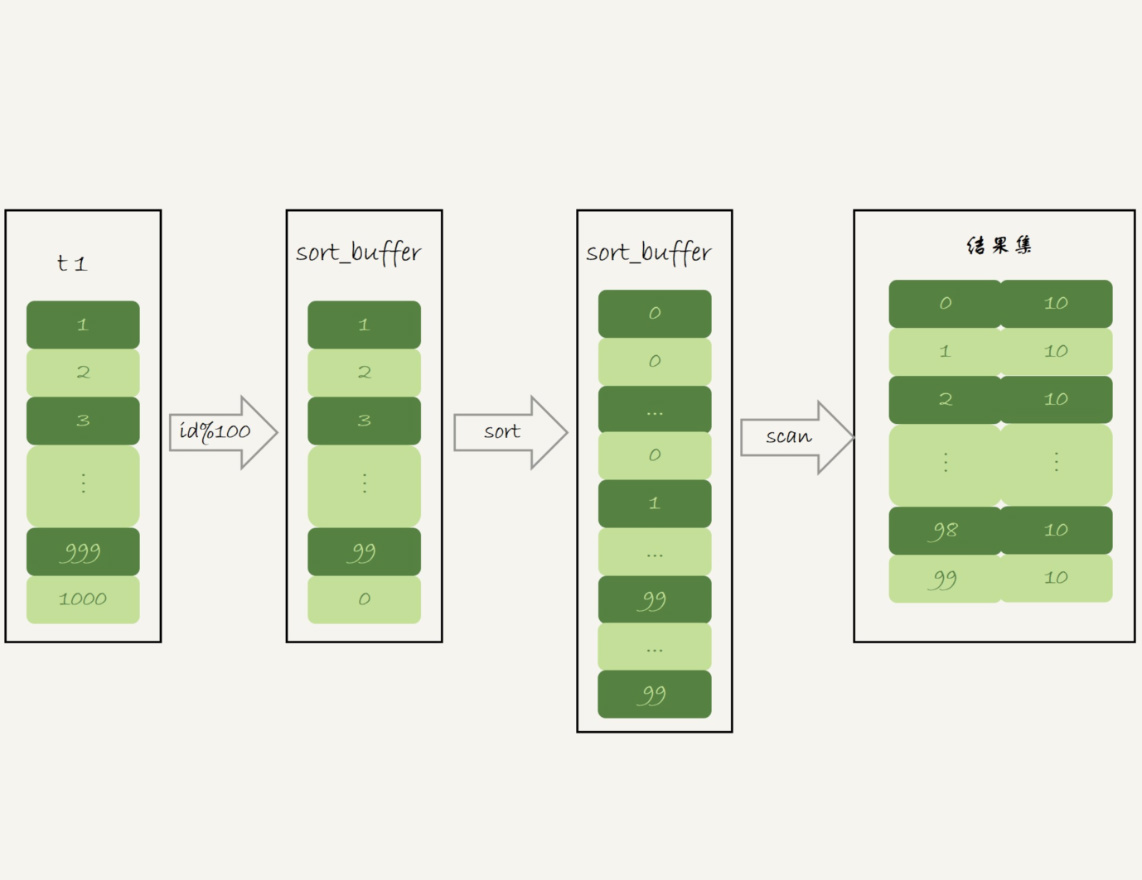
-- 没有再使用临时表,而是直接使用了排序算法
mysql> EXPLAIN SELECT SQL_BIG_RESULT id%100 AS m, COUNT(*) AS c FROM t1 GROUP BY m;
+----+-------------+-------+-------+---------------+------+---------+------+------+-----------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+------+---------+------+------+-----------------------------+
| 1 | SIMPLE | t1 | index | PRIMARY,a | a | 5 | NULL | 1000 | Using index; Using filesort |
+----+-------------+-------+-------+---------------+------+---------+------+------+-----------------------------+
- 初始化
sort_buffer,确定放入一个整型字段,记为m - 扫描t1的索引a,依次取出里面的id值,将id%100的值放入
sort_buffer - 扫描完成后,对
sort_buffer的字段m做排序(sort_buffer内存不够时,会利用磁盘临时文件辅助排序) - 排序完成后,得到一个有序数组,遍历有序数组,得到每个值出现的次数(类似上面优化索引的方式)
对比DISTINCT
-- 标准SQL,SELECT部分添加一个聚合函数COUNT(*)
SELECT a,COUNT(*) FROM t GROUP BY a ORDER BY NULL;
-- 非标准SQL
SELECT a FROM t GROUP BY a ORDER BY NULL;
SELECT DISTINCT a FROM t;
标准SQL:按照字段a分组,计算每组a出现的次数
非标准SQL:没有了
COUNT(*),不再需要执行计算总数的逻辑- 按照字段a分组,相同的a的值只返回一行,与
DISTINCT语义一致
- 按照字段a分组,相同的a的值只返回一行,与
如果不需要执行聚合函数 ,
DISTINCT和GROUP BY的语义、执行流程和执行性能是相同的- 创建一个临时表,临时表有一个字段a,并且在这个字段a上创建一个唯一索引
- 遍历表t,依次取出数据插入临时表中
- 如果发现唯一键冲突,就跳过
- 否则插入成功
- 遍历完成后,将临时表作为结果集返回给客户端
小结
- 用到内部临时表的场景
- 如果语句执行过程中可以一边读数据,一边得到结果,是不需要额外内存的
- 否则需要额外内存来保存中间结果
join_buffer是无序数组,sort_buffer是有序数组,临时表是二维表结构- 如果执行逻辑需要用到二维表特性,就会优先考虑使用临时表
- 如果对
GROUP BY语句的结果没有明确的排序要求,加上ORDER BY NULL(MySQL 5.6) - 尽量让
GROUP BY过程用上索引,确认EXPLAIN结果没有Using temporary和Using filesort - 如果
GROUP BY需要统计的数据量不大,尽量使用内存临时表(可以适当调大tmp_table_size) - 如果数据量实在太大,使用
SQL_BIG_RESULT来告诉优化器直接使用排序算法(跳过临时表)
参考资料
《MySQL实战45讲》
MySQL -- 内部临时表的更多相关文章
- MySQL · 特性分析 · 内部临时表
http://mysql.taobao.org/monthly/2016/06/07/#rd MySQL中的两种临时表 外部临时表 通过CREATE TEMPORARY TABLE 创建的临时表,这种 ...
- [转载]mysql创建临时表,将查询结果插入已有表中
今天遇到一个很棘手的问题,想临时存起来一部分数据,然后再读取.我记得学数据库理论课老师说可以创建临时表,不知道mysql有没有这样的功能呢?临时表在内存之中,读取速度应该比视图快一些.然后还需要将查询 ...
- mysql创建临时表,将查询结果插入已有的表
A.临时表再断开于mysql的连接后系统会自动删除临时表中的数据,但是这只限于用下面语句建立的表:1)定义字段 CREATE TEMPORARY TABLE tmp_table ( nam ...
- MYSQL 磁盘临时表和文件排序
因为Memory引擎不支持BOLB和TEXT类型,所以,如果查询使用了BLOB或TEXT列并且需要使用隐式临时表,将不得不使用MyISAM磁盘临时表,即使只有几行数据也是如此. 这会导致严重的性能开销 ...
- 关于mysql的临时表并行的问题
mysql的临时表并行是没问题的 以为临时表是基于会话的 1.因为在mysql里面每个会话的sessionid 不一样 2.其实就是会话级别的临时表 DB2里面有会话级别 全局级别的临时表,Orac ...
- 当执行一条查询语句时,MySQL内部经历了什么?
假如说我们有一张表 T ,表里只有一个字段 ID,当我们执行下边这条SQL语句时: mysql> select * fron T where ID=10; 在我们眼中能看到的只是输入一条 SQL ...
- 当程序执行一条查询语句时,MySQL内部到底发生了什么? (说一下 MySQL 执行一条查询语句的内部执行过程?
先来个最基本的总结阐述,希望各位小伙伴认真的读一下,哈哈: 1)客户端(运行程序)先通过连接器连接到MySql服务器. 2)连接器通过数据库权限身份验证后,会先查询数据库缓存是否存在(之前执行过相同条 ...
- 今天来学习一下MySQl的 临时表,变量,行转列,预处理的一些相关技术的使用!
先来简单了解一下MySQL数据库有意思的简介 MySQL这个名字,起源不是很明确.一个比较有影响的说法是,基本指南和大量的库和工具带有前缀“my”已经有10年以上, 而且不管怎样,MySQL AB创始 ...
- MySQL什么时候会使用内部临时表?
1.union执行过程 首先我们创建一个表t1 create table t1(id int primary key, a int, b int, index(a)); delimiter ;; cr ...
随机推荐
- Tomcat 核心组件 Container容器相关
前言 Engine容器 Host容器 前言 Connector把封装了Request对象以及Response对象的Socket传递给了Container容器,那么在Contianer容器中又是怎么样的 ...
- SpringBoot - 实现文件上传2(多文件上传、常用上传参数配置)
在前文中我介绍了 Spring Boot 项目如何实现单文件上传,而多文件上传逻辑和单文件上传基本一致,下面通过样例进行演示. 多文件上传 1,代码编写 1)首先在 static 目录中创建一个 up ...
- ES6(四)用Promise封装一下IndexedDB
indexedDB IndexedDB 是一种底层 API,用于在客户端存储大量的结构化数据,它可以被网页脚本创建和操作. IndexedDB 允许储存大量数据,提供查找接口,还能建立索引,这些都是 ...
- Jenkins(7)参数化构建(构建git仓库分支)
前言 当我们的自动化项目越来越多的时候,在代码仓库会提交不同的分支来管理,在用jenkins来构建的时候,我们希望能通过参数化构建git仓库的分支. 下载安装Git Parameter插件 系统管理- ...
- AtCoder Beginner Contest 183
第二次ak,纪念一下. 比赛链接:https://atcoder.jp/contests/abc183/tasks A - ReLU 题解 模拟. 代码 #include <bits/stdc+ ...
- Chip Factory HDU - 5536 字典树(删除节点|增加节点)
题意: t组样例,对于每一组样例第一行输入一个n,下面在输入n个数 你需要从这n个数里面找出来三个数(设为x,y,z),找出来(x+y)^z(同样也可以(y+z)^1)的最大值 ("^&qu ...
- CF1474-C. Array Destruction
CF1474-C. Array Destruction 题意: 题目给出一个长度为\(2n\)的正整数序列,现在问你是否存在一个\(x\)使得可以不断的进行如下操作,直到这个序列变为空: 从序列中找到 ...
- linux内核编程入门--系统调用监控文件访问
参考的资料: hello world https://www.cnblogs.com/bitor/p/9608725.html linux内核监控模块--系统调用的截获 https://www. ...
- Linux 网络协议栈开发基础篇—— 网桥br0
一.桥接的概念 简单来说,桥接就是把一台机器上的若干个网络接口"连接"起来.其结果是,其中一个网口收到的报文会被复制给其他网口并发送出去.以使得网口之间的报文能够互相转发. 交换机 ...
- unity编辑器扩展学习
扩展编辑器实际上就是在unity菜单栏中添加一些按钮,可以一键执行一些重复性的工作. 一.添加按钮 1.简单使用MenuItem特性 using UnityEngine; using UnityEdi ...