spring boot:使用spring cache+caffeine做进程内缓存(本地缓存)(spring boot 2.3.1)
一,为什么要使用caffeine做本地缓存?
1,spring boot默认集成的进程内缓存在1.x时代是guava cache
在2.x时代更新成了caffeine,
功能上差别不大,但后者在性能上更胜一筹,
使用caffeine做本地缓存,取数据可以达到微秒的级别,
一次取数据用时经常不足1毫秒,
这样可以及时响应请求,在高并发的情况下把请求拦截在上游,
避免把压力带到数据库,
所以我们在应用中集成它对于系统的性能有极大的提升
2,与之相比,即使是本地的redis,
响应时间也比进程内缓存用时要更久,
而且在应用服务器很少有专门配备redis缓存的做法,
而是使用专门的redis集群做为分布式缓存
说明:刘宏缔的架构森林是一个专注架构的博客,地址:https://www.cnblogs.com/architectforest
对应的源码可以访问这里获取: https://github.com/liuhongdi/
说明:作者:刘宏缔 邮箱: 371125307@qq.com
二,演示项目的相关信息
1,项目地址:
https://github.com/liuhongdi/caffeine
2,项目原理:
我们建立了两个cache:goods,goodslist
分别用来缓存单个商品详情和商品列表
3,项目结构:
如图:
三,配置文件说明
1,pom.xml
<!--local cache begin-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.8.5</version>
</dependency>
<!--local cache end-->
2,application.properties
#profile
spring.profiles.active=cacheable
这个值用来配置cache是否生效
我们在测试或调试时有时会用关闭缓存的需求
如果想关闭cache,把这个值改变一下即可
3,mysql的数据表结构:
CREATE TABLE `goods` (
`goodsId` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`goodsName` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT 'name',
`subject` varchar(200) NOT NULL DEFAULT '' COMMENT '标题',
`price` decimal(15,2) NOT NULL DEFAULT '0.00' COMMENT '价格',
`stock` int(11) NOT NULL DEFAULT '0' COMMENT 'stock',
PRIMARY KEY (`goodsId`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='商品表'
四,java代码说明
1,CacheConfig.java
@Profile("cacheable") //这个当profile值为cacheable时缓存才生效
@Configuration
@EnableCaching //开启缓存
public class CacheConfig {
public static final int DEFAULT_MAXSIZE = 10000;
public static final int DEFAULT_TTL = 600;
private SimpleCacheManager cacheManager = new SimpleCacheManager();
//定义cache名称、超时时长(秒)、最大容量
public enum CacheEnum{
goods(600,3000), //有效期600秒 , 最大容量3000
goodslist(600,1000), //有效期600秒 , 最大容量1000
;
CacheEnum(int ttl, int maxSize) {
this.ttl = ttl;
this.maxSize = maxSize;
}
private int maxSize=DEFAULT_MAXSIZE; //最大數量
private int ttl=DEFAULT_TTL; //过期时间(秒)
public int getMaxSize() {
return maxSize;
}
public int getTtl() {
return ttl;
}
}
//创建基于Caffeine的Cache Manager
@Bean
@Primary
public CacheManager caffeineCacheManager() {
ArrayList<CaffeineCache> caches = new ArrayList<CaffeineCache>();
for(CacheEnum c : CacheEnum.values()){
caches.add(new CaffeineCache(c.name(),
Caffeine.newBuilder().recordStats()
.expireAfterWrite(c.getTtl(), TimeUnit.SECONDS)
.maximumSize(c.getMaxSize()).build())
);
}
cacheManager.setCaches(caches);
return cacheManager;
}
@Bean
public CacheManager getCacheManager() {
return cacheManager;
}
}
说明:根据CacheEnum这个enum的内容来生成Caffeine Cache,并保存到cachemanager中
如果需要新增缓存,保存到CacheEnum中
@Profile("cacheable"): 当spring.profiles.active的值中包括cacheable时cache才起作用,不包含此值时则cache被关闭不生效
@EnableCaching : 用来开启缓存
recordStats:记录统计数据
expireAfterWrite:在写入到达一定时间后过期
maximumSize:指定最大容量
2,GoodsServiceImpl.java
@Service
public class GoodsServiceImpl implements GoodsService { @Resource
private GoodsMapper goodsMapper; //得到一件商品的信息
@Cacheable(value = "goods", key="#goodsId",sync = true)
@Override
public Goods getOneGoodsById(Long goodsId) {
System.out.println("query database");
Goods goodsOne = goodsMapper.selectOneGoods(goodsId);
return goodsOne;
} //获取商品列表,只更新缓存
@CachePut(value = "goodslist", key="#currentPage")
@Override
public Map<String,Object> putAllGoodsByPage(int currentPage) {
Map<String,Object> res = getAllGoodsByPageDdata(currentPage);
return res;
} //获取商品列表,加缓存
//@Cacheable(key = "#page+'-'+#pageSize") 多个参数可以用字符串连接起来
@Cacheable(value = "goodslist", key="#currentPage",sync = true)
@Override
public Map<String,Object> getAllGoodsByPage(int currentPage) {
Map<String,Object> res = getAllGoodsByPageDdata(currentPage);
return res;
} //从数据库获取商品列表
public Map<String,Object> getAllGoodsByPageDdata(int currentPage) {
System.out.println("-----从数据库得到数据");
Map<String,Object> res = new HashMap<String,Object>();
PageHelper.startPage(currentPage, 5);
List<Goods> goodsList = goodsMapper.selectAllGoods();
res.put("goodslist",goodsList);
PageInfo<Goods> pageInfo = new PageInfo<>(goodsList);
res.put("pageInfo",pageInfo);
return res;
}
}
说明:
@Cacheable(value = "goodslist", key="#currentPage",sync = true):
当缓存中存在数据时,则直接从缓存中返回,
如果缓存中不存在数据,则要执行方法返回数据后并把数据保存到缓存.
@CachePut(value = "goodslist", key="#currentPage"):
不判断缓存中是否存在数据,只更新缓存
3,HomeController.java
//商品列表 参数:第几页
@GetMapping("/goodslist")
public String goodsList(Model model,
@RequestParam(value="p",required = false,defaultValue = "1") int currentPage) {
Map<String,Object> res = goodsService.getAllGoodsByPage(currentPage);
model.addAttribute("pageInfo", res.get("pageInfo"));
model.addAttribute("goodslist", res.get("goodslist"));
return "goods/goodslist";
} //更新
@ResponseBody
@GetMapping("/goodslistput")
public String goodsListPut(@RequestParam(value="p",required = false,defaultValue = "1") int currentPage) {
Map<String,Object> res = goodsService.putAllGoodsByPage(currentPage);
return "cache put succ";
} //清除
@CacheEvict(value="goodslist", allEntries=true)
@ResponseBody
@GetMapping("/goodslistevict")
public String goodsListEvict() {
return "cache evict succ";
}
说明:
@CacheEvict(value="goodslist", allEntries=true):用来清除goodslist中的缓存
4,StatsController.java
@Profile("cacheable")
@Controller
@RequestMapping("/stats")
public class StatsController {
//统计,如果是生产环境,需要加密才允许访问
@Resource
private CacheManager cacheManager;
@GetMapping("/stats")
@ResponseBody
public String stats() {
CaffeineCache caffeine = (CaffeineCache)cacheManager.getCache("goodslist");
Cache goods = caffeine.getNativeCache();
String statsInfo="cache名字:goodslist<br/>";
Long size = goods.estimatedSize();
statsInfo += "size:"+size+"<br/>";
ConcurrentMap map= goods.asMap();
statsInfo += "map keys:<br/>";
for(Object key : map.keySet()) {
statsInfo += "key:"+key.toString()+";value:"+map.get(key)+"<br/>";
}
statsInfo += "统计信息:"+goods.stats().toString();
return statsInfo;
}
}
五,效果测试
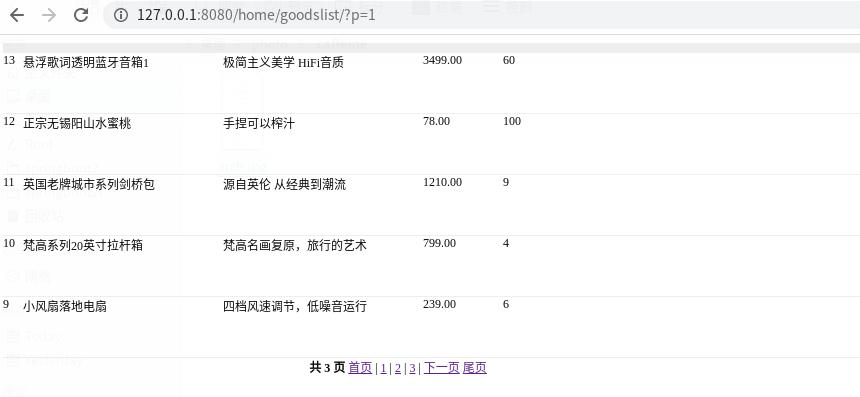
1,访问地址:
http://127.0.0.1:8080/home/goodslist/?p=1
如图:
刷新几次后,可以看到,在使用cache时:
costtime aop 方法doafterreturning:毫秒数:0
使用的时间不足1毫秒
2,查看统计信息,访问:
http://127.0.0.1:8080/stats/stats
如图:

3,清除cache信息:
http://127.0.0.1:8080/home/goodslistevict
查看缓存的统计:
cache名字:goodslist
size:0
map keys:
统计信息:CacheStats{hitCount=1, missCount=3, loadSuccessCount=3, loadFailureCount=0, totalLoadTime=596345574, evictionCount=0, evictionWeight=0}
可以看到数据已被清空
六,查看spring boot的版本
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.3.1.RELEASE)
spring boot:使用spring cache+caffeine做进程内缓存(本地缓存)(spring boot 2.3.1)的更多相关文章
- Spring Boot 2.x基础教程:进程内缓存的使用与Cache注解详解
随着时间的积累,应用的使用用户不断增加,数据规模也越来越大,往往数据库查询操作会成为影响用户使用体验的瓶颈,此时使用缓存往往是解决这一问题非常好的手段之一.Spring 3开始提供了强大的基于注解的缓 ...
- 本地缓存解决方案-Caffeine Cache
1.1 关于Caffeine Cache Google Guava Cache是一种非常优秀本地缓存解决方案,提供了基于容量,时间和引用的缓存回收方式.基于容量的方式内部实现采用LRU算法,基于引 ...
- Caffeine缓存 最快缓存 内存缓存
一.序言 Caffeine是一个进程内部缓存框架. 对比Guava Cache Caffeine是在Guava Cache的基础上做一层封装,性能有明显提高,二者同属于内存级本地缓存.使用Caffei ...
- Java高性能本地缓存框架Caffeine
一.序言 Caffeine是一个进程内部缓存框架,使用了Java 8最新的[StampedLock]乐观锁技术,极大提高缓存并发吞吐量,一个高性能的 Java 缓存库,被称为最快缓存. 二.缓存简介 ...
- 使用Guava cache构建本地缓存
前言 最近在一个项目中需要用到本地缓存,在网上调研后,发现谷歌的Guva提供的cache模块非常的不错.简单易上手的api:灵活强大的功能,再加上谷歌这块金字招牌,让我毫不犹豫的选择了它.仅以此博客记 ...
- spring boot: 用redis的消息订阅功能更新应用内的caffeine本地缓存(spring boot 2.3.2)
一,为什么要更新caffeine缓存? 1,caffeine缓存的优点和缺点 生产环境中,caffeine缓存是我们在应用中使用的本地缓存, 它的优势在于存在于应用内,访问速度最快,通常都不到1ms就 ...
- 如何做自己的服务监控?spring boot 2.x服务监控揭秘
Actuator是spring boot项目中非常强大一个功能,有助于对应用程序进行监视和管理,通过 restful api请求来监管.审计.收集应用的运行情况,针对微服务而言它是必不可少的一个环节. ...
- Spring Boot 入门之 Cache 篇(四)
博客地址:http://www.moonxy.com 一.前言 Spring Cache 对 Cahce 进行了抽象,提供了 @Cacheable.@CachePut.@CacheEvict 等注解. ...
- 如何做自己的服务监控?spring boot 1.x服务监控揭秘
1.准备 下载可运行程序:http://www.mkyong.com/spring-boot/spring-boot-hello-world-example-jsp/ 2.添加服务监控依赖 <d ...
随机推荐
- [算法]体积不小于V的情况下的最小价值(0-1背包)
题目 0-1背包问题,问要求体积不小于V的情况下的最小价值是多少. 相关 转移方程很容易想,初始化的处理还不够熟练,可能还可以更简明. 使用一维dp数组. 代码 import java.util.Sc ...
- [LeetCode]33. 搜索旋转排序数组(二分)
题目 假设按照升序排序的数组在预先未知的某个点上进行了旋转. ( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] ). 搜索一个给定的目标值,如果数组中存在这个目 ...
- Netty之ChannelOption的各种参数
ChannelOption.SO_BACKLOG, 1024 BACKLOG用于构造服务端套接字ServerSocket对象,标识当服务器请求处理线程全满时,用于临时存放已完成三次握手的请求的队列的最 ...
- Object类:又回到最初的起点
Object类大概是每个JAVA程序员认识的第一个类,因为它是所有其他类的祖先类.在JAVA单根继承的体系下,这个类中的每个方法都显得尤为重要,因为每个类都能够调用或者重写这些方法.当你JAVA学到一 ...
- 企业项目实战 .Net Core + Vue/Angular 分库分表日志系统一 | 前言
教程预览 01 | 前言 02 | 简单的分库分表设计 03 | 控制反转搭配简单业务 04 | 强化设计方案 05 | 完善业务自动创建数据库 06 | 最终篇-通过AOP自动连接数据库-完成日志业 ...
- 滴滴开源AgileTC:敏捷测试用例管理平台
桔妹导读:AgileTC是一套敏捷的测试用例管理平台,支持测试用例管理.执行计划管理.进度计算.多人实时协同等能力,方便测试人员对用例进行管理和沉淀.产品以脑图方式编辑可快速上手,用例关联需求形成流 ...
- 刷题[GWCTF 2019]你的名字
解题思路 打开发现需要输入名字,猜测会有sql注入漏洞,测试一下发现单引号被过滤了,再fuzs下看看过滤了哪些 长度为1518和1519的都有过滤,测试一下,感觉不是sql注入了.那还有什么呢,考虑了 ...
- 对Elasticsearch生命周期的思考
什么是es索引的生命周期?有啥用?可以怎么用?用了有什么好处呢? 在现实的生产环境中有没有觉得自己刚开始设计的索引的分片数刚刚好,但是随着时间的增长,数据量增大,增长速度增大的情况下,你的es索引的设 ...
- Java学习day01
1.Java的种类: JavaSE(Java标准版) JavaEE(Java企业版) JavaME(Java微型版) 其中,JavaSE是基础,以后的方向是JavaEE(Java企业版) 2.什么是J ...
- 056 01 Android 零基础入门 01 Java基础语法 06 Java一维数组 03 一维数组的应用
056 01 Android 零基础入门 01 Java基础语法 06 Java一维数组 03 一维数组的应用 本文知识点:数组的实际应用 程序开发中如何应用数组? 程序代码及其运行结果: 不同数据类 ...