Flink on Yarn三部曲之三:提交Flink任务
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
本文是《Flink on Yarn三部曲》系列的终篇,先简单回顾前面的内容:
- 《Flink on Yarn三部曲之一:准备工作》:准备好机器、脚本、安装包;
- 《Flink on Yarn三部曲之二:部署和设置》:完成CDH和Flink部署,并在管理页面做好相关的设置;
现在Flink、Yarn、HDFS都就绪了,接下来实践提交Flink任务到Yarn执行;
全文链接
两种Flink on YARN模式
实践之前,对Flink on YARN先简单了解一下,如下图所示,Flink on Yarn在使用的时候分为两种模式,Job Mode和Session Mode:

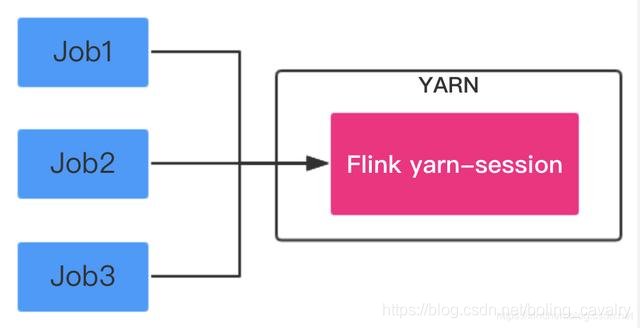
Session Mode:在YARN中提前初始化一个Flink集群,以后所有Flink任务都提交到这个集群,如下图:
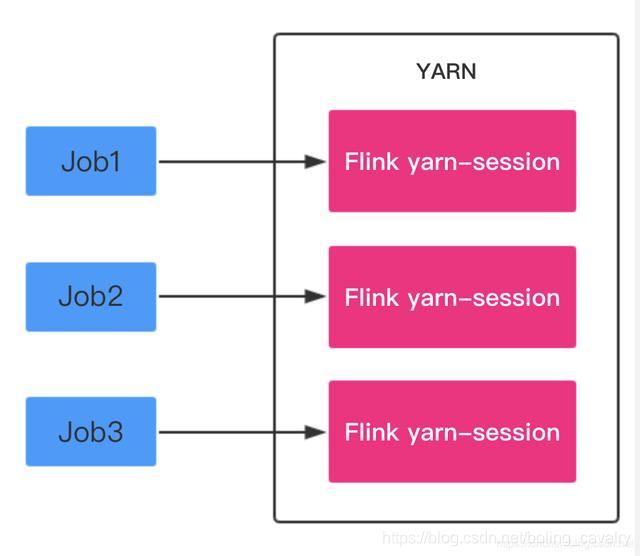
Job Mode:每次提交Flink任务都会创建一个专用的Flink集群,任务完成后资源释放,如下图:
接下来分别实战这两种模式;
准备实战用的数据(CDH服务器)
接下来提交的Flink任务是经典的WordCount,先在HDFS中准备一份文本文件,后面提交的Flink任务都会读取这个文件,统计里面每个单词的数字,准备文本的步骤如下:
- SSH登录CDH服务器;
- 切换到hdfs账号:su - hdfs
- 下载实战用的txt文件:
wget https://github.com/zq2599/blog_demos/blob/master/files/GoneWiththeWind.txt
- 创建hdfs文件夹:hdfs dfs -mkdir /input
- 将文本文件上传到/input目录:hdfs dfs -put ./GoneWiththeWind.txt /input
准备工作完成,可以提交任务试试了。
Session Mode实战
- SSH登录CDH服务器;
- 切换到hdfs账号:su - hdfs
- 进入目录:/opt/flink-1.7.2/
- 执行如下命令创建Flink集群,-n参数表示TaskManager的数量,-jm表示JobManager的内存大小,-tm表示每个TaskManager的内存大小:
./bin/yarn-session.sh -n 2 -jm 1024 -tm 1024
- 创建成功后,控制台输出如下图,注意红框中的提示,表明可以通过38301端口访问Flink:

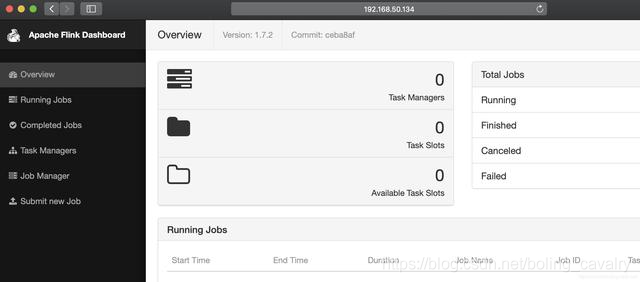
- 浏览器访问CDH服务器的38301端口,可见Flink服务已经启动:
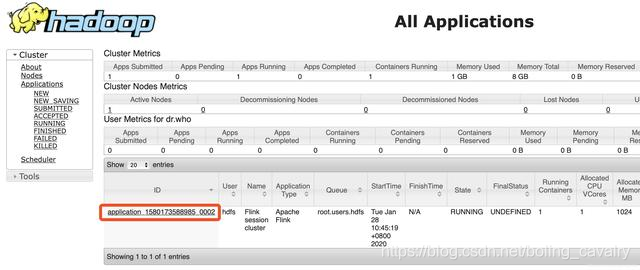
- 浏览器访问CDH服务器的8088端口,可见YARN的Application(即Flink集群)创建成功,如下图,红框中是任务ID,稍后结束Application的时候会用到此ID:
- 再开启一个终端,SSH登录CDH服务器,切换到hdfs账号,进入目录:/opt/flink-1.7.2
- 执行以下命令,就会提交一个Flink任务(安装包自带的WordCount例子),并指明将结果输出到HDFS的wordcount-result.txt文件中:
bin/flink run ./examples/batch/WordCount.jar \
-input hdfs://192.168.50.134:8020/input/GoneWiththeWind.txt \
-output hdfs://192.168.50.134:8020/wordcount-result.txt
- 执行完毕后,控制台输出如下:
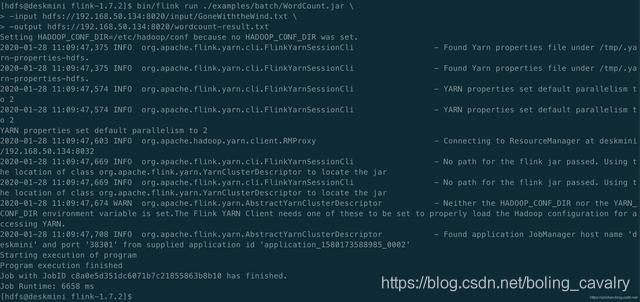
- flink的WordCount任务结果保存在hdfs,我们将结果取出来看看:hdfs dfs -get /wordcount-result.txt
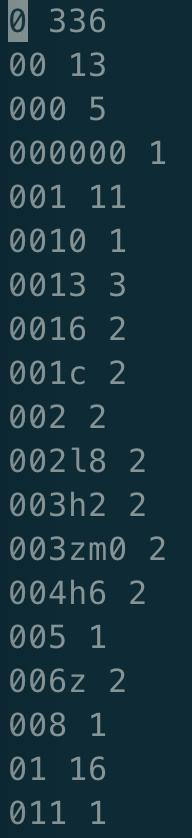
- vi打开wordcount-result.txt文件,如下图,可见任务执行成功,指定文本中的每个单词数量都统计出来了:
- 浏览器访问Flink页面(CDH服务器的38301端口),也能看到任务的详细情况:

- 销毁这个Flink集群的方法是在控制台执行命令:yarn application -kill application_1580173588985_0002

Session Mode的实战就完成了,接下来我们来尝试Job Mode;
Job Mode
- 执行以下命令,创建一个Flink集群,该集群只用于执行参数中指定的任务(wordCount.jar),结果输出到hdfs的wordcount-result-1.txt文件:
bin/flink run -m yarn-cluster \
-yn 2 \
-yjm 1024 \
-ytm 1024 \
./examples/batch/WordCount.jar \
-input hdfs://192.168.50.134:8020/input/GoneWiththeWind.txt \
-output hdfs://192.168.50.134:8020/wordcount-result-1.txt
- 控制台输出如下,表明任务执行完成:

- 如果您的内存和CPU核数充裕,可以立即执行以下命令再创建一个Flink集群,该集群只用于执行参数中指定的任务(wordCount.jar),结果输出到hdfs的wordcount-result-2.txt文件:
bin/flink run -m yarn-cluster \
-yn 2 \
-yjm 1024 \
-ytm 1024 \
./examples/batch/WordCount.jar \
-input hdfs://192.168.50.134:8020/input/GoneWiththeWind.txt \
-output hdfs://192.168.50.134:8020/wordcount-result-2.txt
- 在YARN管理页面可见任务已经结束:
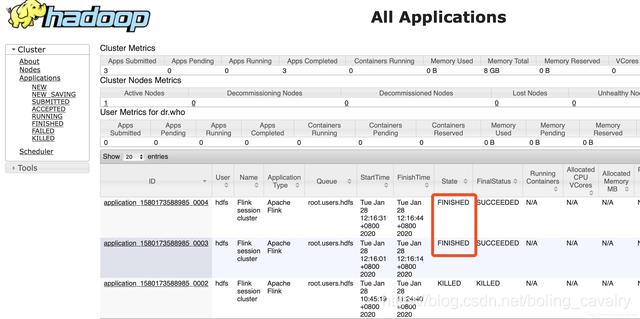
- 执行命令hdfs dfs -ls /查看结果文件,已经成功生成:
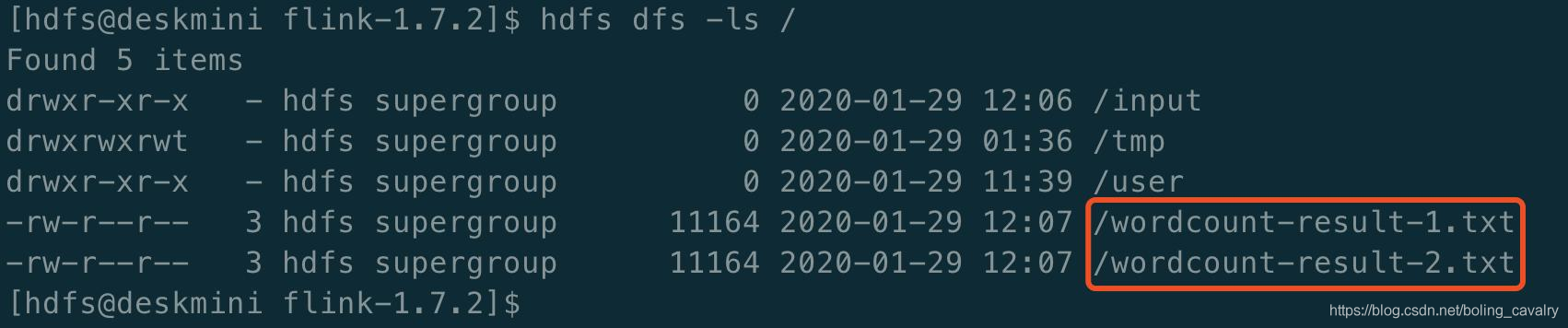
- 执行命令hdfs dfs -get /wordcount-result-1.txt下载结果文件到本地,检查数据正常;
- 至此,Flink on Yarn的部署、设置、提交都实践完成,《Flink on Yarn三部曲》系列也结束了,如果您也在学习Flink,希望本文能够给您一些参考,也建议您根据自身情况和需求,修改ansible脚本,搭建更适合自己的环境;
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
Flink on Yarn三部曲之三:提交Flink任务的更多相关文章
- Flink on Yarn三部曲之一:准备工作
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink on Yarn三部曲之二:部署和设置
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink的DataSource三部曲之三:自定义
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink源码阅读(一)——Flink on Yarn的Per-job模式源码简析
一.前言 个人感觉学习Flink其实最不应该错过的博文是Flink社区的博文系列,里面的文章是不会让人失望的.强烈安利:https://ververica.cn/developers-resource ...
- Flink的DataSource三部曲之一:直接API
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink的DataSource三部曲之二:内置connector
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Apache Flink 进阶(六):Flink 作业执行深度解析
本文根据 Apache Flink 系列直播课程整理而成,由 Apache Flink Contributor.网易云音乐实时计算平台研发工程师岳猛分享.主要分享内容为 Flink Job 执行作业的 ...
- flink on yarn模式下两种提交job方式
yarn集群搭建,参见hadoop 完全分布式集群搭建 通过yarn进行资源管理,flink的任务直接提交到hadoop集群 1.hadoop集群启动,yarn需要运行起来.确保配置HADOOP_HO ...
- Flink on yarn的配置及执行
1. 写在前面 Flink被誉为第四代大数据计算引擎组件,即可以用作基于离线分布式计算,也可以应用于实时计算.Flink可以自己搭建集群模式已提供为庞大数据的计算.但在实际应用中.都是计算hdfs上的 ...
随机推荐
- Hadoop框架:单服务下伪分布式集群搭建
本文源码:GitHub·点这里 || GitEE·点这里 一.基础环境 1.环境版本 环境:centos7 hadoop版本:2.7.2 jdk版本:1.8 2.Hadoop目录结构 bin目录:存放 ...
- Docker实战(1):通过配置文件启动MongoDB
系统环境:Centos7 MongoDB 4.0.0 创建文件 注意:创建文件全是为了Docker run做准备,文件所对应的路径需与下一步的映射路径所对应,路径可自我更改. mkdir mongo ...
- flutter实现可缩放可拖拽双击放大的图片功能
flutter实现可缩放可拖拽双击放大的图片功能 可缩放可拖拽的功能,可实现图片或者其他widget的缩放已经拖拽并支持双击放大的功能 我们知道官方提供了双击缩放,但是不支持拖拽的功能,我们要实现向百 ...
- 重磅来袭 Vue 3.0 One Piece 正式发布
代号为One Piece 的Vue3.0 在9月19日凌晨正式发布!! 此次vue3.0 为用户提供了全新的 composition-api 以及更小的包大小,和更好的 TypeScript 支持. ...
- docker zookeeper 集群搭建
#创建集群目录 mkdir /opt/cluster/zk cd /opt/cluster/zk #清理脏数据[可跳过] docker stop zk-2181 docker stop zk-2182 ...
- spring cloud gateway(三、实现限流)
限流一般有两个实现方式,令牌桶和漏桶 金牌桶是初始化令牌(容器)的个数,通过拿走里边的令牌就能通过, 没有令牌不能报错,可以设置向容器中增加令牌的速度和最大个数 漏桶是向里边放入请求,当请求数量达到最 ...
- 接口鉴权,提供给第三方调用的接口,进行sign签名
//场景:公司要跟第三方公司合作,提供接口给对方对接,这样需要对接口进行授权,不然任何人都可以调我们公司的接口,会导致安全隐患: 思路: 在每个接口请求参数都带上ApiKey 和sign签名: 我们在 ...
- Spring Cloud系列(二):Eureka应用详解
一.注册中心 1.注册中心演变过程 2.注册中心必备功能 ① 服务的上线 ② 服务的下线 ③ 服务的剔除 ④ 服务的查询 ⑤ 注册中心HA ⑥ 注册中心节点数据同步 ⑦ 服务信息的存储,比如mysql ...
- C语言中的左移与右移 <<, >> 位运算
这里参考了一篇很好的位运算,涉及到位运算可能会遇到的正负号问题,左右溢出怎么处理问题. 参考: 1. https://www.cnblogs.com/myblesh/articles/2431806. ...
- 【题解】「MCOI-02」Convex Hull 凸包
题目戳我 \(\text{Solution:}\) \[\sum_{i=1}^n \sum_{j=1}^n \rho(i)\rho(j)\rho(\gcd(i,j)) \] \[=\sum_{d=1} ...