Python调用云服务器AWVS13API接口批量扫描(指哪打哪)
最近因为实习的原因,为了减少一部分的工作量,在阿里云服务器上搭建了AWVS扫描器 方便摸鱼
但是发现AWVS貌似没有批量添加的方法,作者只好把整理的URL.txt捏了又捏

手动输入是不可能手动输入的,去查了查网上关于AWVS扫描器API的使用,找到两篇文章:
https://blog.csdn.net/wy_97/article/details/106872773
https://blog.csdn.net/sinat_25449961/article/details/82985638
然后花一个小时的时间整理了一下,因为作者只需要添加任务,以及让扫描任务启动,所以我们也从这两个功能入手,查看API接口。
添加任务接口是:
Method:POST
URL: /api/v1/targets
| 发送参数 | 类型 | 说明 |
|---|---|---|
| address | string | 目标网址:需http或https开头 |
| criticality | Int | 危险程度;范围:[30,20,10,0];默认为10 |
| description | string | 备注 |
具体的使用如下:
'''
create_target函数
功能:
AWVS13
新增任务接口
Method : POST
URL : /api/v1/targets
发送参数:
发送参数 类型 说明
address string 目标网址:需要http或https开头
criticality int 危险程度;范围:[30,20,10,0];默认为10
description string 备注
'''
def create_target(address,description,int_criticality):
url = 'https://' + IP + ':13443/api/v1/targets' headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
values = {
'address': address,
'description': description,
'criticality': int_criticality,
}
data = bytes(json.dumps(values), 'utf-8')
request = urllib.request.Request(url, data, headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
return html
在create_target()函数中,如服务器IP是全局变量,即搭建AWVS的服务器的IP,后面接的端口需要根据实际情况修改。
可以看到现在还没有任务:
简单调用:
#这两处需要修改为你自己的
IP = ''
API_KEY = '' def main():
testurl='https://www.zsjjob.com/'
description="null"
int_criticality=10
print(create_target(testurl,description,int_criticality)) if __name__=='__main__':
main()
运行返回结果为:
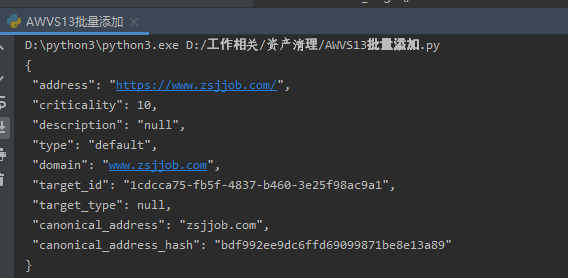
接着我们查看AWVS添加的任务里面
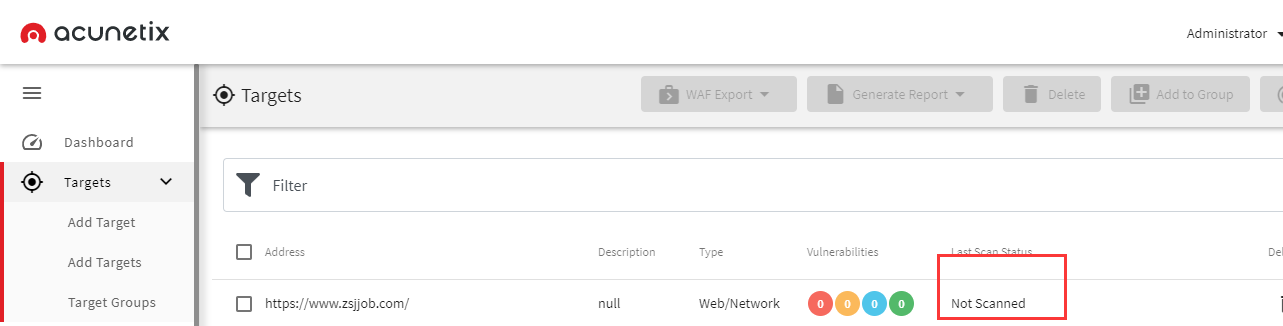
可以看到只是添加到了任务中,还未进行扫描,接着我们查看开始扫描的API:
Method:POST
URL: /api/v1/scans
| 发送参数 | 类型 | 说明 |
| profile_id | string | 扫描类型 |
| ui_session_i | string | 可不传 |
| schedule | json | 扫描时间设置(默认即时) |
| report_template_id | string | 扫描报告类型(可不传) |
| target_id | string | 目标id |
可以看到必选的就是 扫描类型,扫描时间设置,目标id
而扫描类型 profile_id 可以选择的有:
| 扫描类型 | 值 | 翻译 |
| Full Scan | 11111111-1111-1111-1111-111111111111 | 完全扫描 |
| High Risk Vulnerabilities | 11111111-1111-1111-1111-111111111112 | 高风险漏洞 |
| Cross-site Scripting Vulnerabilities | 11111111-1111-1111-1111-111111111116 | XSS漏洞 |
| SQL Injection Vulnerabilities | 11111111-1111-1111-1111-111111111113 | SQL注入漏洞 |
| Weak Passwords | 11111111-1111-1111-1111-111111111115 | 弱口令检测 |
| Crawl Only | 11111111-1111-1111-1111-111111111117 | Crawl Only |
| Malware Scan | 11111111-1111-1111-1111-111111111120 | 恶意软件扫描 |
我们在代码中使用的是扫描类型对应的值,一般都是直接使用完全扫描
扫描时间设置我们按照默认值设置,目标 id 我们之前已经看到过了,即:
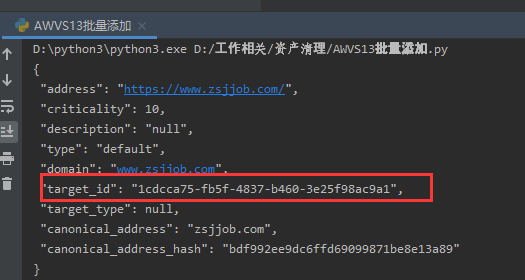
所以我们只要将获取到的target_id和其他两个参数丢进去就行了。
具体使用如下:
'''
start_target
功能:
AWVS13
启动扫描任务接口
Method : POST
URL : /api/v1/scans
发送参数:
发送参数 类型 说明
profile_id string 扫描类型
ui_session_i string 可不传
schedule json 扫描时间设置(默认即时)
report_template string 扫描报告类型(可不传)
target_id string 目标id
'''
def start_target(target_id,profile_id):
url = 'https://' + IP + ':13443/api/v1/scans' # schedule={"disable": False, "start_date": None, "time_sensitive": False}
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
values = {
'target_id': target_id,
'profile_id': profile_id,
'schedule': {"disable":False,"start_date":None,"time_sensitive":False}
}
data = bytes(json.dumps(values), 'utf-8')
request = urllib.request.Request(url, data, headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
# return html
return "now scan {}".format(target_id)
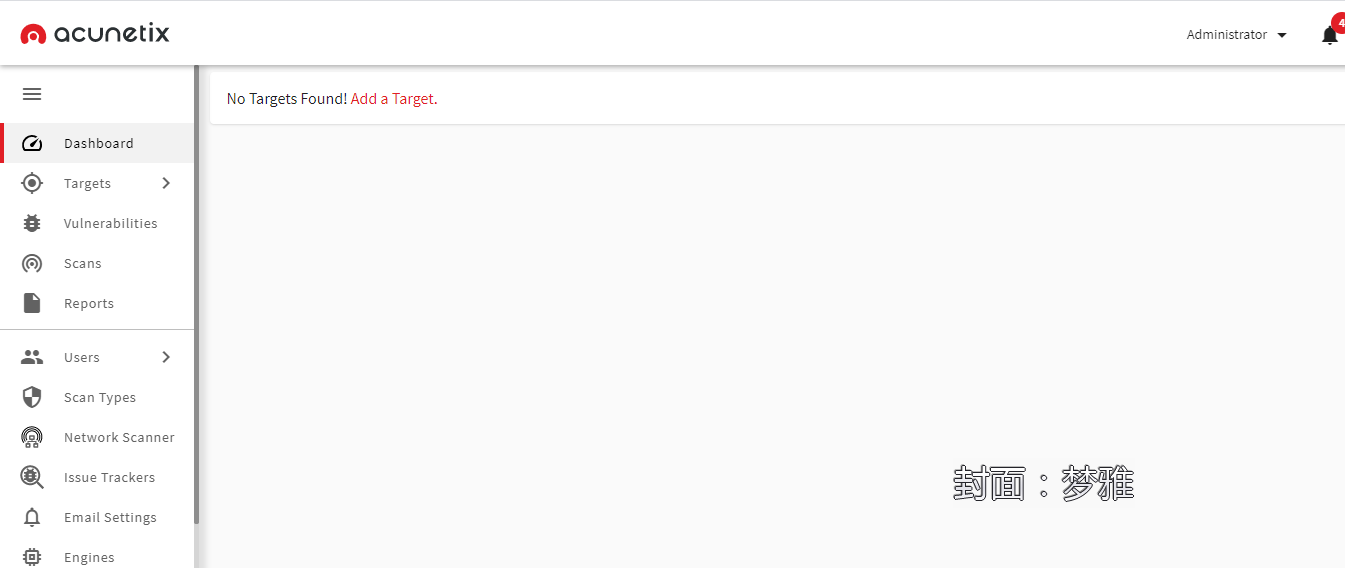
然后先将AWVS上面的任务清空一下,然后整合和调用之前的所有代码。
清空后的AWVS如图:
整合调用的全部代码为(作者去掉了IP和API_KEY,需要读者按照自己的搭建自行添加,另外还需要注意端口的问题)
import json
import ssl
import urllib.request
import os ssl._create_default_https_context = ssl._create_unverified_context #os.environ['http_proxy'] = 'http://127.0.0.1:8080'
#os.environ['https_proxy'] = 'https://127.0.0.1:8080' IP = ''
API_KEY = '' '''
create_target函数
功能:
AWVS13
新增任务接口
Method : POST
URL : /api/v1/targets
发送参数:
发送参数 类型 说明
address string 目标网址:需要http或https开头
criticality int 危险程度;范围:[30,20,10,0];默认为10
description string 备注
'''
def create_target(address,description,int_criticality):
url = 'https://' + IP + ':13443/api/v1/targets' headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
values = {
'address': address,
'description': description,
'criticality': int_criticality,
}
data = bytes(json.dumps(values), 'utf-8')
request = urllib.request.Request(url, data, headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
return html def get_target_list():
url = 'https://' + IP + ':3443/api/v1/targets'
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
return html def profiles_list():
url = 'https://' + IP + ':3443/api/v1/scanning_profiles'
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
return html '''
start_target
功能:
AWVS13
启动扫描任务接口
Method : POST
URL : /api/v1/scans
发送参数:
发送参数 类型 说明
profile_id string 扫描类型
ui_session_i string 可不传
schedule json 扫描时间设置(默认即时)
report_template string 扫描报告类型(可不传)
target_id string 目标id
'''
def start_target(target_id,profile_id):
url = 'https://' + IP + ':13443/api/v1/scans' # schedule={"disable": False, "start_date": None, "time_sensitive": False}
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
values = {
'target_id': target_id,
'profile_id': profile_id,
'schedule': {"disable":False,"start_date":None,"time_sensitive":False}
}
data = bytes(json.dumps(values), 'utf-8')
request = urllib.request.Request(url, data, headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
# return html
return "now scan {}".format(target_id) def stop_target(target_id):
url = 'https://' + IP + ':3443/api/v1/scans/' + target_id + '/abort'
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
print(html) def target_status(target_id):
url = 'https://' + IP + ':3443/api/v1/scans/' + target_id
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
print(html) def get_target_result(target_id, scan_session_id):
url = 'https://' + IP + ':3443/api/v1/scans/' + target_id + '/results/' + scan_session_id + '/vulnerabilities '
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
print(html) '''
主要使用批量添加与启动扫描任务的功能
即create_target()函数与start_target()函数 '''
def main():
testurl='https://www.zsjjob.com/'
description="null"
int_criticality=10
target_id=create_target(testurl,description,int_criticality).split('"')[21]
print(start_target(target_id,'11111111-1111-1111-1111-111111111111')) if __name__=='__main__':
main()
运行之
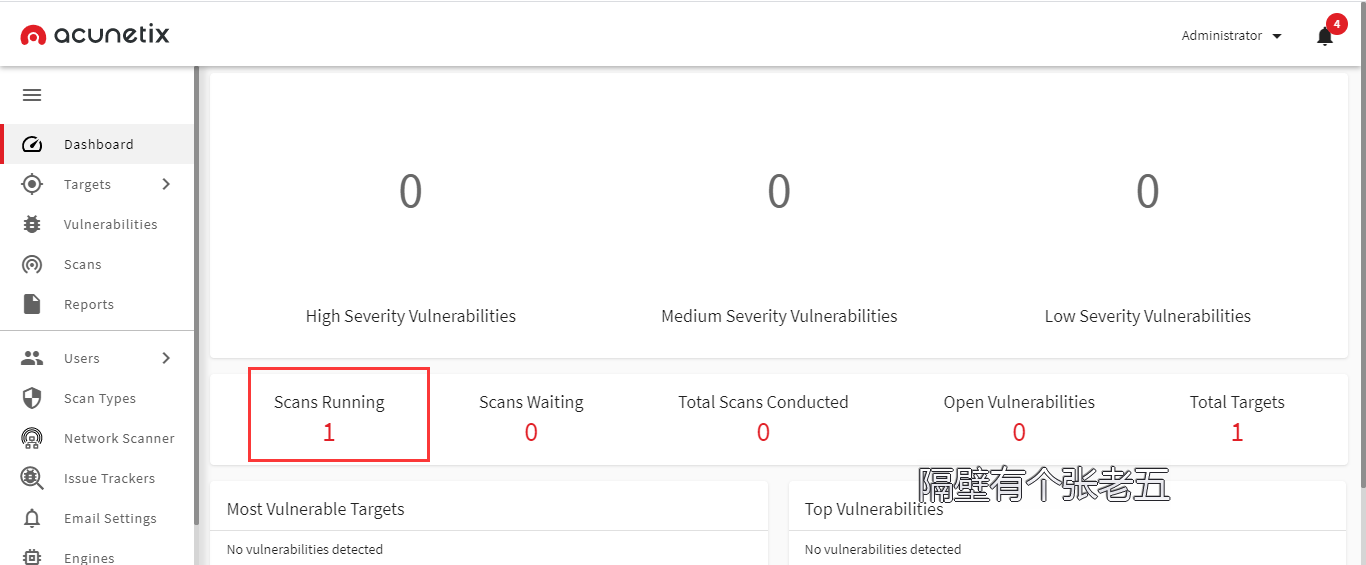
可以看到任务已经自动运行起来了,读者可以根据自己的URL.txt,修改上述代码,使其更符合业务需求。
另外需要注意的是,AWVS的批量添加URL中,都是需要http或者https开头的!!
以上(开始快乐批量扫描趴)
参考链接:
https://blog.csdn.net/sinat_25449961/article/details/82985638
https://blog.csdn.net/wy_97/article/details/106872773
Python调用云服务器AWVS13API接口批量扫描(指哪打哪)的更多相关文章
- Python调用7zip命令实现文件批量解压
Python调用7zip命令实现文件批量解压 1.输入压缩文件所在的路径 2.可以在代码中修改解压到的文件路径和所需要解压的类型,列入,解压文件夹下面所有的mp4格式的文件 3.cmd 指的就是Pyt ...
- express:webpack dev-server开发中如何调用后端服务器的接口?
开发环境: 前端:webpack + vue + vue-resource,基于如下模板创建的开发环境: https://github.com/vuejs-templates/webpack ...
- Python实现云服务器防止暴力密码破解
云服务器防止暴力密码破解 云服务器暴露在公网上,每天都有大量的暴力密码破解,更换端口,无济于事,该脚本监控安全日志,获取暴力破解的对方ip,加入hosts黑名单 路径说明 描述 路径 登录安全日志 / ...
- 在windows下用python调用darknet的yolo接口
0,目标 本人计算机环境:windows7 64位,安装了vs2015专业版,python3.5.2,cygwin,opencv3.3,无gpu 希望实现用python调用yolo函数,实现物体检测. ...
- Python调用百度地图API实现批量经纬度转换为实际省市地点(api调用,json解析,excel读取与写入)
1.获取秘钥 调用百度地图API实现得申请百度账号或者登陆百度账号,然后申请自己的ak秘钥.链接如下:http://lbsyun.baidu.com/apiconsole/key?applicatio ...
- 简单实现Python调用有道API接口(最新的)
# ''' # Created on 2018-5-26 # # @author: yaoshuangqi # ''' import urllib.request import urllib.pars ...
- python调用nmap进行扫描
#coding=utf-8 import nmap import optparse import threading import sys import re ''' 需安装python_nmap包, ...
- 用Python调用华为云API接口发短信
[摘要] 用Python调用华为云API接口实现发短信,当然能给调用发短信接口前提条件是通过企业实名认证,而且有一个通过审核的短信签名,话不多说,showcode #!/usr/bin/python3 ...
- python调用腾讯云短信接口
目录 python调用腾讯云短信接口 账号注册 python中封装腾讯云短信接口 python调用腾讯云短信接口 账号注册 去腾讯云官网注册一个腾讯云账号,通过实名认证 然后开通短信服务,创建短信应用 ...
随机推荐
- 利用.NET 5和Github Action 自动执行米游社原神每日签到福利
背景 众所周知,原神的签到福利是需要下载app才可以领取的.但像我这种一般不怎么刷论坛的人,每天点开app签到很麻烦. 很多大佬利用Github的Action自动执行的模式,实现了很多好东西.加上.n ...
- sk_buff结构--转载
套接字缓存之sk_buff结构 https://www.cnblogs.com/wanpengcoder/p/7529486.html 来此此处 sk_buff结构用来描述已接收或者待发送的数据报文信 ...
- 从头学起Verilog(一):组合逻辑基础与回顾
引言 该部分主要回顾了本科时数字电路中组合逻辑电路部分,内容相对简单和基础. 内容主要包括:布尔代数相关知识,卡诺图,最大项与最小项,竞争和冒险以及一些常见模块 数字电路中的逻辑 组合逻辑:输出可以表 ...
- Python_爬虫笔记_2018.3.19
Python_爬虫_笔记 1.前言 1.1爬虫用途: 网站采集.接口采集(地图(jis 热力学 屋里端口/协议).微信.知乎.) 1.2基本流程:网页下载(requests)+网页解析+爬虫调度 网页 ...
- CSP-J 2020题解
CSP-J 2020题解 本次考试还是很有用的,至少把我浇了一盆冷水. 当使用民间数据自测的时候,我就自闭了. 估分是320,但有些比较低级的错误直接少掉80. 而且这套题应该上350才正常吧,也不是 ...
- 理解 ASP.NET Core: 处理管道
理解 ASP.NET Core 处理管道 在 ASP.NET Core 的管道处理部分,实现思想已经不是传统的面向对象模式,而是切换到了函数式编程模式.这导致代码的逻辑大大简化,但是,对于熟悉面向对象 ...
- Gulp自动化构建的基本使用
Study Notes 本博主会持续更新各种前端的技术,如果各位道友喜欢,可以关注.收藏.点赞下本博主的文章. Gulp 用自动化构建工具增强你的工作流程! gulp 将开发流程中让人痛苦或耗时的任务 ...
- 【Azure Redis 缓存 Azure Cache For Redis】使用Redis自带redis-benchmark.exe命令测试Azure Redis的性能
问题描述 关于Azure Redis的性能问题,在官方文档中,可以查看到不同层级Redis的最大连接数,每秒处理请求的性能. 基本缓存和标准缓存 C0 (250 MB) 缓存 - 最多支持 256 个 ...
- Camtasia中对录制视频进行编辑——旁白
相信很多人都遇见过想要录制视频,但是不知道在电脑上用哪一款软件比较好,害怕自己录的视频导出来之后会有水印,或者在录制的过程中遇到麻烦,更或者下载一款带有病毒的软件.那么今天我便给大家推荐一款专业录制屏 ...
- 如何用CDR做出毛笔字效果
不仅仅是水墨字,毛笔字在CDR中的制作也是很简单的.一般来讲,水墨字其实跟毛笔字有相通之处,也可以说毛笔字是水墨字的一种,在CDR中的实现也是既简单又实用的. 方法一:艺术笔工具 艺术笔工具是比较便捷 ...