Python调用云服务器AWVS13API接口批量扫描(指哪打哪)
最近因为实习的原因,为了减少一部分的工作量,在阿里云服务器上搭建了AWVS扫描器 方便摸鱼
但是发现AWVS貌似没有批量添加的方法,作者只好把整理的URL.txt捏了又捏

手动输入是不可能手动输入的,去查了查网上关于AWVS扫描器API的使用,找到两篇文章:
https://blog.csdn.net/wy_97/article/details/106872773
https://blog.csdn.net/sinat_25449961/article/details/82985638
然后花一个小时的时间整理了一下,因为作者只需要添加任务,以及让扫描任务启动,所以我们也从这两个功能入手,查看API接口。
添加任务接口是:
Method:POST
URL: /api/v1/targets
| 发送参数 | 类型 | 说明 |
|---|---|---|
| address | string | 目标网址:需http或https开头 |
| criticality | Int | 危险程度;范围:[30,20,10,0];默认为10 |
| description | string | 备注 |
具体的使用如下:
'''
create_target函数
功能:
AWVS13
新增任务接口
Method : POST
URL : /api/v1/targets
发送参数:
发送参数 类型 说明
address string 目标网址:需要http或https开头
criticality int 危险程度;范围:[30,20,10,0];默认为10
description string 备注
'''
def create_target(address,description,int_criticality):
url = 'https://' + IP + ':13443/api/v1/targets' headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
values = {
'address': address,
'description': description,
'criticality': int_criticality,
}
data = bytes(json.dumps(values), 'utf-8')
request = urllib.request.Request(url, data, headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
return html
在create_target()函数中,如服务器IP是全局变量,即搭建AWVS的服务器的IP,后面接的端口需要根据实际情况修改。
可以看到现在还没有任务:
简单调用:
#这两处需要修改为你自己的
IP = ''
API_KEY = '' def main():
testurl='https://www.zsjjob.com/'
description="null"
int_criticality=10
print(create_target(testurl,description,int_criticality)) if __name__=='__main__':
main()
运行返回结果为:
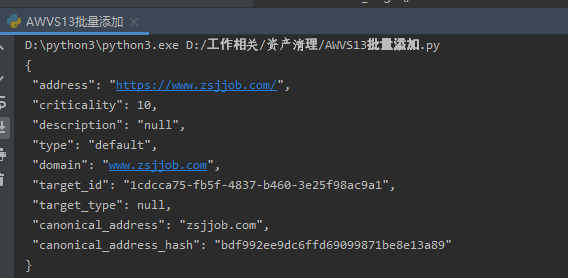
接着我们查看AWVS添加的任务里面
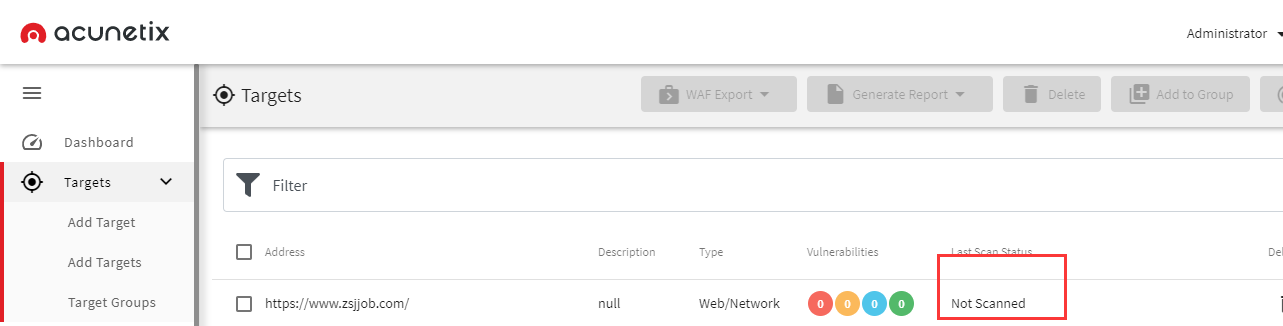
可以看到只是添加到了任务中,还未进行扫描,接着我们查看开始扫描的API:
Method:POST
URL: /api/v1/scans
| 发送参数 | 类型 | 说明 |
| profile_id | string | 扫描类型 |
| ui_session_i | string | 可不传 |
| schedule | json | 扫描时间设置(默认即时) |
| report_template_id | string | 扫描报告类型(可不传) |
| target_id | string | 目标id |
可以看到必选的就是 扫描类型,扫描时间设置,目标id
而扫描类型 profile_id 可以选择的有:
| 扫描类型 | 值 | 翻译 |
| Full Scan | 11111111-1111-1111-1111-111111111111 | 完全扫描 |
| High Risk Vulnerabilities | 11111111-1111-1111-1111-111111111112 | 高风险漏洞 |
| Cross-site Scripting Vulnerabilities | 11111111-1111-1111-1111-111111111116 | XSS漏洞 |
| SQL Injection Vulnerabilities | 11111111-1111-1111-1111-111111111113 | SQL注入漏洞 |
| Weak Passwords | 11111111-1111-1111-1111-111111111115 | 弱口令检测 |
| Crawl Only | 11111111-1111-1111-1111-111111111117 | Crawl Only |
| Malware Scan | 11111111-1111-1111-1111-111111111120 | 恶意软件扫描 |
我们在代码中使用的是扫描类型对应的值,一般都是直接使用完全扫描
扫描时间设置我们按照默认值设置,目标 id 我们之前已经看到过了,即:
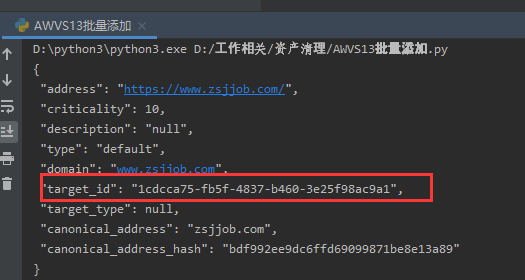
所以我们只要将获取到的target_id和其他两个参数丢进去就行了。
具体使用如下:
'''
start_target
功能:
AWVS13
启动扫描任务接口
Method : POST
URL : /api/v1/scans
发送参数:
发送参数 类型 说明
profile_id string 扫描类型
ui_session_i string 可不传
schedule json 扫描时间设置(默认即时)
report_template string 扫描报告类型(可不传)
target_id string 目标id
'''
def start_target(target_id,profile_id):
url = 'https://' + IP + ':13443/api/v1/scans' # schedule={"disable": False, "start_date": None, "time_sensitive": False}
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
values = {
'target_id': target_id,
'profile_id': profile_id,
'schedule': {"disable":False,"start_date":None,"time_sensitive":False}
}
data = bytes(json.dumps(values), 'utf-8')
request = urllib.request.Request(url, data, headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
# return html
return "now scan {}".format(target_id)
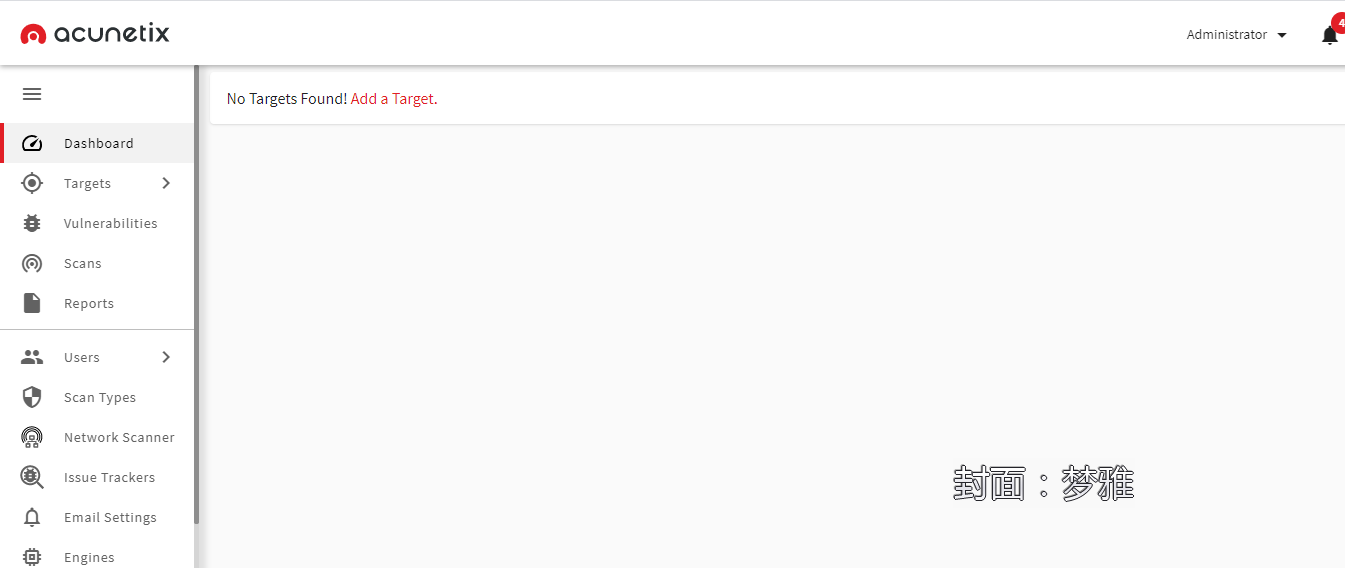
然后先将AWVS上面的任务清空一下,然后整合和调用之前的所有代码。
清空后的AWVS如图:
整合调用的全部代码为(作者去掉了IP和API_KEY,需要读者按照自己的搭建自行添加,另外还需要注意端口的问题)
import json
import ssl
import urllib.request
import os ssl._create_default_https_context = ssl._create_unverified_context #os.environ['http_proxy'] = 'http://127.0.0.1:8080'
#os.environ['https_proxy'] = 'https://127.0.0.1:8080' IP = ''
API_KEY = '' '''
create_target函数
功能:
AWVS13
新增任务接口
Method : POST
URL : /api/v1/targets
发送参数:
发送参数 类型 说明
address string 目标网址:需要http或https开头
criticality int 危险程度;范围:[30,20,10,0];默认为10
description string 备注
'''
def create_target(address,description,int_criticality):
url = 'https://' + IP + ':13443/api/v1/targets' headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
values = {
'address': address,
'description': description,
'criticality': int_criticality,
}
data = bytes(json.dumps(values), 'utf-8')
request = urllib.request.Request(url, data, headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
return html def get_target_list():
url = 'https://' + IP + ':3443/api/v1/targets'
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
return html def profiles_list():
url = 'https://' + IP + ':3443/api/v1/scanning_profiles'
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
return html '''
start_target
功能:
AWVS13
启动扫描任务接口
Method : POST
URL : /api/v1/scans
发送参数:
发送参数 类型 说明
profile_id string 扫描类型
ui_session_i string 可不传
schedule json 扫描时间设置(默认即时)
report_template string 扫描报告类型(可不传)
target_id string 目标id
'''
def start_target(target_id,profile_id):
url = 'https://' + IP + ':13443/api/v1/scans' # schedule={"disable": False, "start_date": None, "time_sensitive": False}
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
values = {
'target_id': target_id,
'profile_id': profile_id,
'schedule': {"disable":False,"start_date":None,"time_sensitive":False}
}
data = bytes(json.dumps(values), 'utf-8')
request = urllib.request.Request(url, data, headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
# return html
return "now scan {}".format(target_id) def stop_target(target_id):
url = 'https://' + IP + ':3443/api/v1/scans/' + target_id + '/abort'
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
print(html) def target_status(target_id):
url = 'https://' + IP + ':3443/api/v1/scans/' + target_id
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
print(html) def get_target_result(target_id, scan_session_id):
url = 'https://' + IP + ':3443/api/v1/scans/' + target_id + '/results/' + scan_session_id + '/vulnerabilities '
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
print(html) '''
主要使用批量添加与启动扫描任务的功能
即create_target()函数与start_target()函数 '''
def main():
testurl='https://www.zsjjob.com/'
description="null"
int_criticality=10
target_id=create_target(testurl,description,int_criticality).split('"')[21]
print(start_target(target_id,'11111111-1111-1111-1111-111111111111')) if __name__=='__main__':
main()
运行之
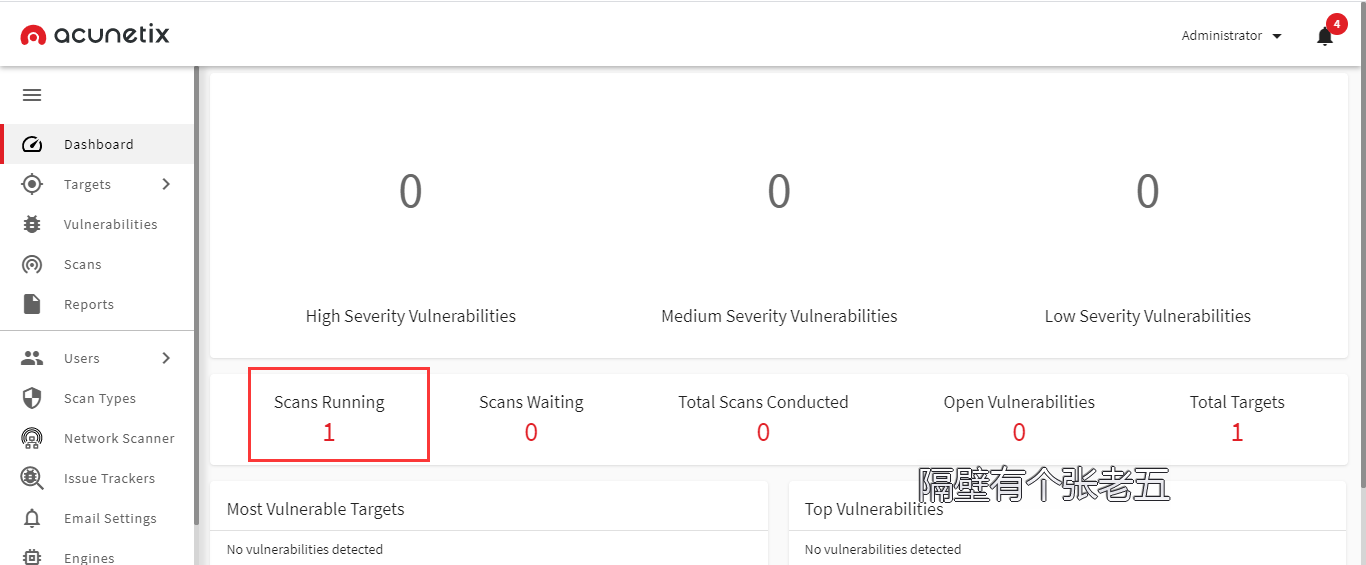
可以看到任务已经自动运行起来了,读者可以根据自己的URL.txt,修改上述代码,使其更符合业务需求。
另外需要注意的是,AWVS的批量添加URL中,都是需要http或者https开头的!!
以上(开始快乐批量扫描趴)
参考链接:
https://blog.csdn.net/sinat_25449961/article/details/82985638
https://blog.csdn.net/wy_97/article/details/106872773
Python调用云服务器AWVS13API接口批量扫描(指哪打哪)的更多相关文章
- Python调用7zip命令实现文件批量解压
Python调用7zip命令实现文件批量解压 1.输入压缩文件所在的路径 2.可以在代码中修改解压到的文件路径和所需要解压的类型,列入,解压文件夹下面所有的mp4格式的文件 3.cmd 指的就是Pyt ...
- express:webpack dev-server开发中如何调用后端服务器的接口?
开发环境: 前端:webpack + vue + vue-resource,基于如下模板创建的开发环境: https://github.com/vuejs-templates/webpack ...
- Python实现云服务器防止暴力密码破解
云服务器防止暴力密码破解 云服务器暴露在公网上,每天都有大量的暴力密码破解,更换端口,无济于事,该脚本监控安全日志,获取暴力破解的对方ip,加入hosts黑名单 路径说明 描述 路径 登录安全日志 / ...
- 在windows下用python调用darknet的yolo接口
0,目标 本人计算机环境:windows7 64位,安装了vs2015专业版,python3.5.2,cygwin,opencv3.3,无gpu 希望实现用python调用yolo函数,实现物体检测. ...
- Python调用百度地图API实现批量经纬度转换为实际省市地点(api调用,json解析,excel读取与写入)
1.获取秘钥 调用百度地图API实现得申请百度账号或者登陆百度账号,然后申请自己的ak秘钥.链接如下:http://lbsyun.baidu.com/apiconsole/key?applicatio ...
- 简单实现Python调用有道API接口(最新的)
# ''' # Created on 2018-5-26 # # @author: yaoshuangqi # ''' import urllib.request import urllib.pars ...
- python调用nmap进行扫描
#coding=utf-8 import nmap import optparse import threading import sys import re ''' 需安装python_nmap包, ...
- 用Python调用华为云API接口发短信
[摘要] 用Python调用华为云API接口实现发短信,当然能给调用发短信接口前提条件是通过企业实名认证,而且有一个通过审核的短信签名,话不多说,showcode #!/usr/bin/python3 ...
- python调用腾讯云短信接口
目录 python调用腾讯云短信接口 账号注册 python中封装腾讯云短信接口 python调用腾讯云短信接口 账号注册 去腾讯云官网注册一个腾讯云账号,通过实名认证 然后开通短信服务,创建短信应用 ...
随机推荐
- C++ 数据结构 3:树和二叉树
1 树 1.1 定义 由一个或多个(n ≥ 0)结点组成的有限集合 T,有且仅有一个结点称为根(root),当 n > 1 时,其余的结点分为 m (m ≥ 0)个互不相交的有限集合T1,T2, ...
- mysql实现当前行的值累加上一行的值
数据库钱包表有日期.收入.支出三个字段.用mysql语句计算每日余额,得如下结果 select m.*, @total :=@total + 收入 - 支出 as 钱包余额 ( select * fr ...
- 【Java】线程的 6 种状态
一.线程状态的枚举 Java的线程从创建到销毁总共有6种状态.这些状态被定义在Thread类种的内部枚举 State 中,分别如下: 1.NEW:初始状态. 线程实例已创建,但未启动. // 实例创建 ...
- typora 图片存储在COS
背景 一直在使用的markdown编辑器:typora ,在其内部图片默认是存储在本机C盘中的,现想将图片方放到云端存储,节省存储空间 方法 将typora中的图片上传到腾讯云的COS中 参考:链接 ...
- centos6安装calamari
安装操作系统 首先安装操作系统centos6,安装过程选择的是base server,这个不相同不要紧,出现缺少包的时候去iso找出来安装就可以了 calamari的简单介绍 首先简单的介绍下cala ...
- nginx开启目录浏览
使用nginx作为下载站点,开启目录浏览的功能 在/etc/nginx/sites-enabled/default中添加: autoindex on ; autoindex_exact_size of ...
- 使用electron+vue开发一个跨平台todolist(便签)桌面应用
# 1 最近一直在使用electron开发桌面应用,对于一个web开发者来说,html+javascript+css的开发体验让我非常舒服.之前我一直简单的以为electron只是张网页加个壳,和那些 ...
- MySQL存储索引InnoDB数据结构为什么使用B+树,而不是其他树呢?
InnoDB的一棵B+树可以存放多少行数据? 答案:约2千万 为什么是这么多? 因为这是可以算出来的,要搞清楚这个问题,先从InnoDB索引数据结构.数据组织方式说起. 计算机在存储数据的时候,有最小 ...
- ServerLess之云函数实践-天气API
关注我的个人博客,发掘更多的内容 ServerLess之云函数实践-天气API 前言 云计算是大势所趋 Serverless 架构即"⽆服务器"架构,它是一种全新的架构方式,是云计 ...
- 万字长文带你掌握Java数组与排序,代码实现原理都帮你搞明白!
查找元素索引位置 基本查找 根据数组元素找出该元素第一次在数组中出现的索引 public class TestArray1 { public static void main(String[] arg ...