flume+flume+kafka消息传递+storm消费
通过flume收集其他机器上flume的监测数据,发送到本机的kafka进行消费。
环境:slave中安装flume,master中安装flume+kafka(这里用两台虚拟机,也可以用三台以上)
masterIP 192.168.83.128 slaveIP 192.168.83.129
通过监控test.log文件的变化,收集变化信息发送到主机的flume中,再发送到kafka中进行消费
1、配置slave1在flume中配置conf目录中的example.conf文件,没有就创建一个
#Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = exec
#监控文件夹下的test.log文件
a1.sources.r1.command = tail -F /home/qq/pp/data/test.log
a1.sources.r1.channels = c1 # Describe the sink
##sink端的avro是一个数据发送者
a1.sinks = k1
##type设置成avro来设置发消息
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
##下沉到master这台机器
a1.sinks.k1.hostname = 192.168.83.133
##下沉到mini2中的44444
a1.sinks.k1.port = 44444
a1.sinks.k1.batch-size = # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2、master上配置flume/conf里面的example.conf(标红的注意下)
#me the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
##source中的avro组件是一个接收者服务
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444 # Describe the sink
#a1.sinks.k1.type = logger
#对于sink的配置描述 使用kafka做数据的消费
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = flume_kafka
a1.sinks.k1.brokerList = 192.168.83.128:9092,192.168.83.129:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20 # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3、向监听文件写入字符串(程序循环写入,不用手动修改test.log文件了)
[root@s1 # cd /home/qq/pp/data
[root@s1 home/qq/pp/data# while true
> do
> echo "toms" >> test.log
> sleep
> done
4、查看上面的程序是否执行
#cd /home/qq/pp/data
#tail -f test.log
5、打开消息接收者master的flume
进入flume安装目录,执行如下语句
bin/flume-ng agent -c conf -f conf/example.conf -n a1 -Dflume.root.logger=INFO,console
现在回打印出一些信息
6、启动slave的flume
进入flume安装目录,执行如下语句
bin/flume-ng agent -c conf -f conf/example.conf -n a1 -Dflume.root.logger=INFO,console
7、 进入master ---kafka安装目录
1)启动zookeeper
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
2)启动kafka服务
bin/kafka-server-start.sh -daemon config/server.properties
3)创建topic
kafka-topics.sh --create --topic flume_kafka --zookeeper 192.168.83.129:,192.168.83.128: --partitions --replication-factor 1
4)创建消费者
bin/kafka-console-consumer.sh --bootstrap-server 192.168.83.128:,192.168.83.129: --topic flume_kafka --from-beginning
5)然后就会看到消费之窗口打印写入的信息,

8、此时启动 eclipse实例(https://www.cnblogs.com/51python/p/10908660.html),注意修改ip以及topic
如果启动不成功看看是不是kafka设置问题(https://www.cnblogs.com/51python/p/10919330.html第一步虚拟机部署)
启动后会打印出结果(这是第二次测试不是用的toms而是hollo word测试的,此处只是一个实例)
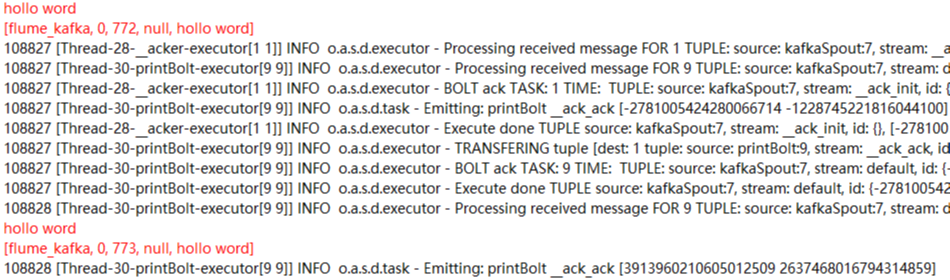
ok!一个流程终于走完了!
参考:
https://blog.csdn.net/luozhonghua2014/article/details/80369469?utm_source=blogxgwz5
https://blog.csdn.net/wxgxgp/article/details/85701844
https://blog.csdn.net/tototuzuoquan/article/details/73203241
flume+flume+kafka消息传递+storm消费的更多相关文章
- Flume、Kafka、Storm结合
Todo: 对Flume的sink进行重构,调用kafka的消费生产者(producer)发送消息; 在Sotrm的spout中继承IRichSpout接口,调用kafka的消息消费者(Consume ...
- 基于Flume+Kafka+ Elasticsearch+Storm的海量日志实时分析平台(转)
0背景介绍 随着机器个数的增加.各种服务.各种组件的扩容.开发人员的递增,日志的运维问题是日渐尖锐.通常,日志都是存储在服务运行的本地机器上,使用脚本来管理,一般非压缩日志保留最近三天,压缩保留最近1 ...
- 大数据平台架构(flume+kafka+hbase+ELK+storm+redis+mysql)
上次实现了flume+kafka+hbase+ELK:http://www.cnblogs.com/super-d2/p/5486739.html 这次我们可以加上storm: storm-0.9.5 ...
- Kafka实战-Flume到Kafka
1.概述 前面给大家介绍了整个Kafka项目的开发流程,今天给大家分享Kafka如何获取数据源,即Kafka生产数据.下面是今天要分享的目录: 数据来源 Flume到Kafka 数据源加载 预览 下面 ...
- 【转】Kafka实战-Flume到Kafka
Kafka实战-Flume到Kafka Kafka 2015-07-03 08:46:24 发布 您的评价: 0.0 收藏 2收藏 1.概述 前面给大家介绍了整个Kafka ...
- Flume+LOG4J+Kafka
基于Flume+LOG4J+Kafka的日志采集架构方案 本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具, ...
- Kafka实战-Flume到Kafka (转)
原文链接:Kafka实战-Flume到Kafka 1.概述 前面给大家介绍了整个Kafka项目的开发流程,今天给大家分享Kafka如何获取数据源,即Kafka生产数据.下面是今天要分享的目录: 数据来 ...
- 入门大数据---Flume整合Kafka
一.背景 先说一下,为什么要使用 Flume + Kafka? 以实时流处理项目为例,由于采集的数据量可能存在峰值和峰谷,假设是一个电商项目,那么峰值通常出现在秒杀时,这时如果直接将 Flume 聚合 ...
- Flume与Kafka集成
一.Flume介绍 Flume是一个分布式.可靠.和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能 ...
随机推荐
- UICollectionViewFlowLayout & UICollectionViewDelegateFlowLayout
A concrete layout object that organizes items into a grid with optional header and footer views for ...
- GridView中字符串太长处理方式
<asp:TemplateField HeaderText="子机构编号"> <ItemTemplate> <asp:Label ID="L ...
- NFS指定端口,NFS缓存(转载)
nfs服务端: #编辑/etc/nfsmount.conf,在末尾添加: #RQUOTAD_PORT=30001#LOCKD_TCPPORT=30002#LOCKD_UDPPORT=30002#MOU ...
- Django工程
一.Django工程创建 1.Django安装: pip3 install django 安装成功后,会在python的安装目录下“Scripts"中生成”django-admin.exe& ...
- Python学习【第3篇】:Python之运算符
一.运算符 计算机可以进行的运算有很多种,不只是加减乘除,它和我们人脑一样,也可以做很多运算. 种类:算术运算,比较运算,逻辑运算,赋值运算,成员运算,身份运算,位运算,今天我们先了解前四个. 算术运 ...
- STM32学习笔记:读写内部Flash(介绍+附代码)
一.介绍 首先我们需要了解一个内存映射: stm32的flash地址起始于0x0800 0000,结束地址是0x0800 0000加上芯片实际的flash大小,不同的芯片flash大小不同. RAM起 ...
- tensorflow的数据输入
tensorflow有两种数据输入方法,比较简单的一种是使用feed_dict,这种方法在画graph的时候使用placeholder来站位,在真正run的时候通过feed字典把真实的输入传进去.比较 ...
- 像 IDE 一样使用 vim
本文转载自:https://github.com/yangyangwithgnu/use_vim_as_ide ##[目录] 0 vim 必知会........0.1 .vimrc 文件....... ...
- 最小生成树prime算法模板
#include<stdio.h> #include<string.h> using namespace std; int map[505][505]; int v, e; i ...
- windows下swoole安装教程
1)下载安装cygwin(根据操作系统选择32位或者64位): https://cygwin.com/install.html 选择在windows中虚拟环境的root目录 选择下载安装的网络节点,如 ...