Hadoop之block研究
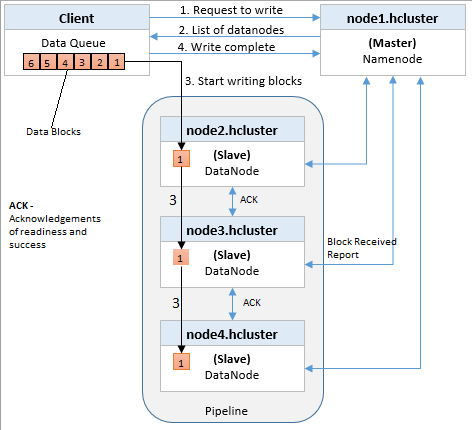
 注释:准备和成功的ACK(确认)
注释:准备和成功的ACK(确认)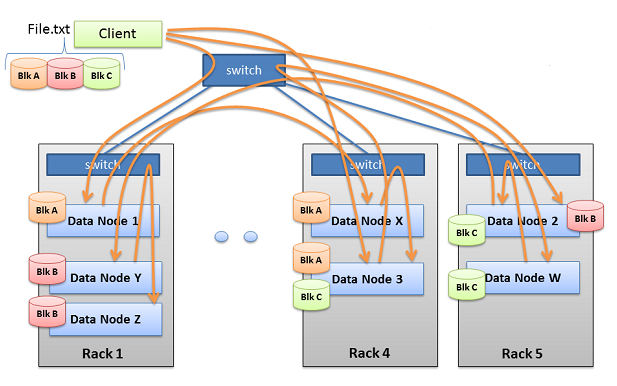

Hadoop之block研究的更多相关文章
- ios之Block研究
Block的好处,我总结了下主要有2点:1.用于回调特别方便,2.可以延长对象的作用区域.但是,Block的内存管理这个模块一直不是很清楚,这个周末好好的看了下Block的原理,有些许心得. 为了性能 ...
- hadoop中block副本的放置策略
下面的这种是针对于塔式服务器的副本的放置策略
- 【转载】Hadoop机架感知
转载自http://www.cnblogs.com/ggjucheng/archive/2013/01/03/2843015.html 背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机 ...
- hadoop机架感知
背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高于跨机架 ...
- Hadoop分布式配置
本作品由Man_华创作,采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可.基于http://www.cnblogs.com/manhua/上的作品创作. 请先参照Linux安 ...
- Hadoop port to Jxta P2P Framework
https://www.java.net/forum/topic/jxta/jxta-community-forum/hadoop-port-jxta-p2p-framework —————————— ...
- HADOOP实战
一.软件版本Centos6.5.VMware 10CDH5.2.0(Hadoop 2.5.0)Hive-0.13 sqoop-1.4.5 二.学完课程之后,您可以:①.一个人搞定企业Hadoop平台搭 ...
- 基于Docker一键部署大规模Hadoop集群及设计思路
一.背景: 随着互联网的发展.互联网用户的增加,互联网中的数据也急剧膨胀.每天产生的数据量数以万计,本地文件系统和单机CPU已无法满足存储和计算要求.Hadoop分布式文件系统(HDFS)是海量数据存 ...
- 第十三章 hadoop机架感知
背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高于跨机架 ...
随机推荐
- CentOS6.5 虚拟机 磁盘扩容
1. 关闭虚拟机 2. 编辑虚拟机设置:增加硬盘的置备大小,或者添加新的硬盘 3. 启动虚拟机,查看可用磁盘大小 : # df -Th Filesystem Type Size Used Avail ...
- 常用的JavaScript设计模式(二)Factory(工厂)模式
Factory通过提供一个通用的接口来创建对象,同时,我们还可以指定我们想要创建的对象实例的类型. 假设现在有一个汽车工厂VehicleFactory,支持创建Car和Truck类型的对象实例,现在需 ...
- QP总体结构
QP是一个基于事件驱动的嵌入式系统软件框架,其总体结构如下图. AO活动对象由事件队列和层次状态机两部分组成,每个AO占有一个优先级: QF量子框架由五个数据结构及操作组成,其数据结构采用了uCOS- ...
- Java学习笔记二十二:Java的方法重写
Java的方法重写 一:什么是方法的重写: 如果子类对继承父类的方法不满意,是可以重写父类继承的方法的,当调用方法时会优先调用子类的方法. 语法规则 返回值类型.方法名.参数类型及个数都要与父类继承的 ...
- Divisibility题解
From lyh 学长 2018.5.3 信(liang)心(liang)杯T3 一道略弱的数论题. 题目描述 给定 n个数,问是否能从中选出恰好 k个数,使得这些数两两之差可以被 m 整除. 输入输 ...
- react路由按需加载方法
使用router4之后以前的按需加载方法require.ensure 是不好使了. 所以我们改用react-loadable插件做按需加载. 第一步: yarn add react-loadable ...
- Mave环境搭建SSM集成空项目
---恢复内容开始--- 一.空项目案例 软件: 链接:https://pan.baidu.com/s/18Fk8frnWMBRho43P98C97w 提取码:0rk7 项目:链接:https://p ...
- LeetCode:34. Search for a Range(Medium)
1. 原题链接 https://leetcode.com/problems/search-for-a-range/description/ 2. 题目要求 给定一个按升序排列的整型数组nums[ ]和 ...
- Spring框架之Filter应用
在web.xml中进行配置,对所有的URL请求进行过滤,就像"击鼓传花"一样,链式处理. 配置分为两种A和B. 在web.xml中增加如下内容: <filter> &l ...
- LVS Nginx HAProxy
转自:http://blog.chinaunix.net/uid-27022856-id-3236257.html LVS 优点:1.抗负载能力强.工作在第4层仅作分发之用,没有流量的产生,这个特点也 ...