python3爬取全站美眉图片
爬取网站:https://www.169tp.com/xingganmeinv
该网站美眉图片有数百页,每页24张,共上万张图片,全部爬取下来
import urllib.request
import re
import os
from bs4 import BeautifulSoup page_flag = 0
base_url = "https://www.169tp.com/xingganmeinv/"
first_url ="https://www.169tp.com/xingganmeinv/list_1_1.html"
Imgnums = 0 def get_html(url):
response = urllib.request.urlopen(url)
html = response.read().decode('gb18030')
return html def get_Imgurl_list(html):
img_urllist = re.findall('src=["\']{1}(.+?\.jpg)["\']{1}', html)
return img_urllist def Download(img_urllist,page_flag,final_path,Imgnums):
num = 1
for imgurl in img_urllist:
imgname = "{}{}{}{}.jpg".format(final_path,page_flag,'_',num)
urllib.request.urlretrieve(imgurl,imgname)
print("已经爬取图片名:",imgname)
Imgnums += 1
num += 1 def makedir(path):
path = path.strip()
isExists = os.path.exists(path)
if not isExists:
print("创建了路径为 ",path," 的文件夹")
os.makedirs(path)
return True
else:
print("路径为 ",path," 的文件夹已经存在")
return False filepath = input("请输入保持图片的文件夹路径:")
print(filepath)
name = input("请输入保存图片的文件夹名:")
print(name)
finalpath = filepath + name
makedir(finalpath)
finalpath += '\\'
print(f"图片保存路径: {finalpath}") Download(get_Imgurl_list(first_url),page_flag,finalpath,Imgnums)
mysoup = BeautifulSoup(get_html(first_url),'html.parser')
next_page = mysoup.find('div',attrs = {'class':'page'}).find('li',text = '下一页').find('a')
while next_page:
new_url = base_url + next_page['href']
page_flag += 1
Download(get_Imgurl_list(get_html(new_url)),page_flag,finalpath,Imgnums)
mysoup = BeautifulSoup(get_html(new_url),'html.parser')
next_page = mysoup.find('div',attrs = {'class':'page'}).find('li',text = '下一页').find('a')
print(f"下载完成,共下载了 {Imgnums} 张图片!")
运行截图:
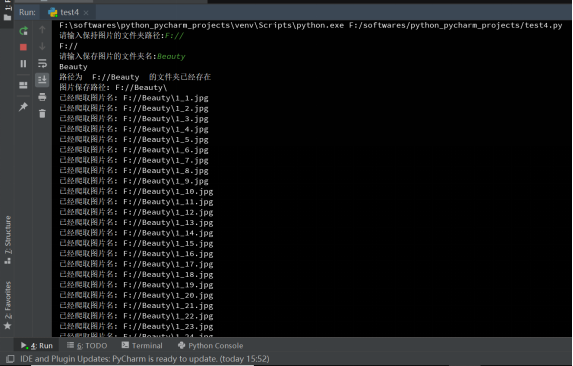
图片名命名规则:存储路径+页码+下划线+图片号+.jpg
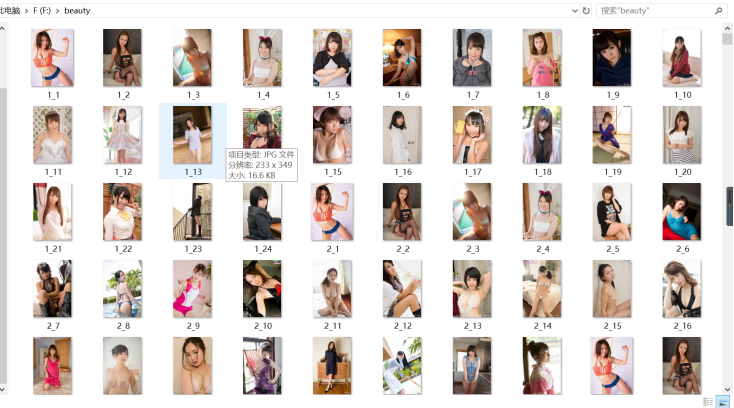
图片文件夹截图:
python3爬取全站美眉图片的更多相关文章
- Python爬取全站妹子图片,差点硬盘走火了!
在这严寒的冬日,为了点燃我们的热情,今天小编可是给大家带来了偷偷收藏了很久的好东西.大家要注意点哈,我第一次使用的时候,大意导致差点坏了大事哈! 1.所需库安装 2.网站分析 首先打开妹子图的官网(m ...
- Python3爬取美女妹子图片转载
# -*- coding: utf-8 -*- """ Created on Sun Dec 30 15:38:25 2018 @author: 球球 "&qu ...
- python3爬取动态网站图片
思路: 1.图片放在<image>XXX</image>标签中 2.利用fiddler抓包获取存放图片信息的js文件url 3.利用requests库获取html内容,然后获取 ...
- python3爬取1024图片
这两年python特别火,火到博客园现在也是隔三差五的出现一些python的文章.各种开源软件.各种爬虫算法纷纷开路,作为互联网行业的IT狗自然看的我也是心痒痒,于是趁着这个雾霾横行的周末瞅了两眼,作 ...
- python3爬取女神图片,破解盗链问题
title: python3爬取女神图片,破解盗链问题 date: 2018-04-22 08:26:00 tags: [python3,美女,图片抓取,爬虫, 盗链] comments: true ...
- 如何用python爬虫从爬取一章小说到爬取全站小说
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http ...
- python 爬虫入门----案例爬取上海租房图片
前言 对于一个net开发这爬虫真真的以前没有写过.这段时间学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup. ...
- Python3 爬取微信好友基本信息,并进行数据清洗
Python3 爬取微信好友基本信息,并进行数据清洗 1,登录获取好友基础信息: 好友的获取方法为get_friends,将会返回完整的好友列表. 其中每个好友为一个字典 列表的第一项为本人的账号信息 ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
随机推荐
- IntelliJ IDEA开发工具println报错的解决方法
IntelliJ IDEA 编译 JSP,出现 out.println 报错,下图所示: 报错原因:println报红,这是因为没有关联好服务器! 解决方案:点击File->Project st ...
- silverlight generic.xaml 包含中文 编译错误的问题
发现我在一个dll工程里面新建一个xaml文件起名成generic.xaml 如果这个xaml里面存在中文则会编译错误,发现这样建立的xaml使用的是gb2312编码 果断文件-另存为-编码另存为 u ...
- SQL点点滴滴_查询类型和索引-转载
当您考虑是否要对列创建索引时, 请估计在查询中使用列的方式, 下表介绍了索引对其有用的查询类型. 表中的示例基于 AdventureWorks2008R2 示例数据库, 在 SQL Server Ma ...
- linux命令整理
Linux系统命令 1. ls 查看某个 目录下 所有文件的大小总和 ls -lR| awk 'BEGIN{size=0;} /^[-l]/{size+=$5;print $0;} END{print ...
- 什么是封装? ----------------php中"public"类似的访问修饰符分别有什么作用?----什么是抽象?抽象的关键字以及用法----- 什么是接口?接口的关键字以及用法-------------
什么是封装? ------------------------------------封装是php面向对象的其中一个特性,将多个可重复使用的函数封装到一个类里面.在使用时直接实例化该类的某一个方法,获 ...
- Windows软件静默安装
Install Software in A Slient Way 一般来说,不同的软件的封装类型都有固定的静默安装命令. 查看软件的封装类型 双击setup.exe,在弹出窗口的左上角单击,选择&qu ...
- php 上传大文件注意问题
一.如果要对文件进行复杂的处理,注意设置php.ini中的max_execution_time.max_input_time为足够大,如大量字符串处理urlencode等. 二.如果文件处理要占用较大 ...
- 应用服务&领域服务
应用服务&领域服务 DDD理论学习系列——案例及目录 1. 引言 单从字面理解,不管是领域服务还是应用服务,都是服务.而什么是服务?从SOA到微服务,它们所描述的服务都是一个宽泛的概念,我们可 ...
- Json 和 Jsonlib 的使用
什么是 Json JSON(JvaScript Object Notation)(官网网站:http://www.json.org/)是 一种轻量级的数据交换格式. 易于人阅读和编写.同时也易于机器解 ...
- ListView实现分页加载(一)制作Demo
一.什么是分页加载 在下面的文章中,我们来讲解LitView分页加载的实现.什么是分页加载呢?我们先看几张效果图吧,如下: ...