使用Chrome console提取页面数据
使用Chrome console提取页面数据
1、需求介绍
在做课题研究的过程中,遇到这样一个问题,有一个页面中包含很多IP地址,需要把这些IP地址提取出来保存到文件中。如下图所示:
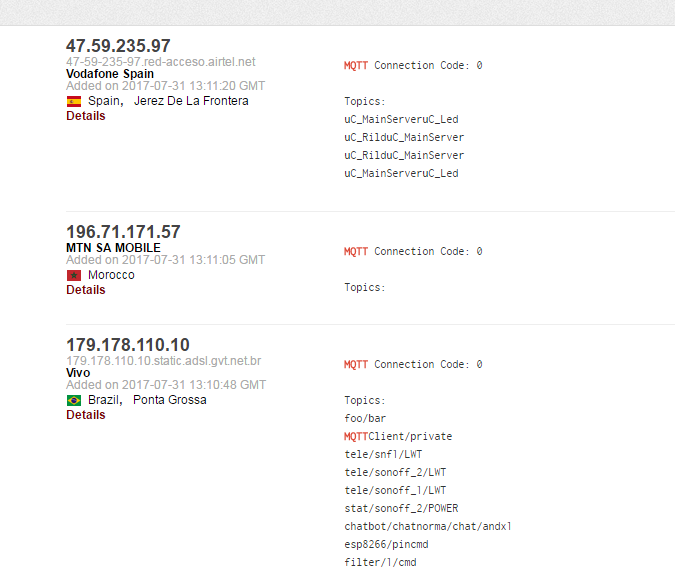
一开始的做法是一个个选中然后复制到.txt中,这样未免也太多繁琐,因此想到使用前端的工具进行提取。
2、实例
首先按F12键,打开控制台面板;定位到我们所需要数据的标签;
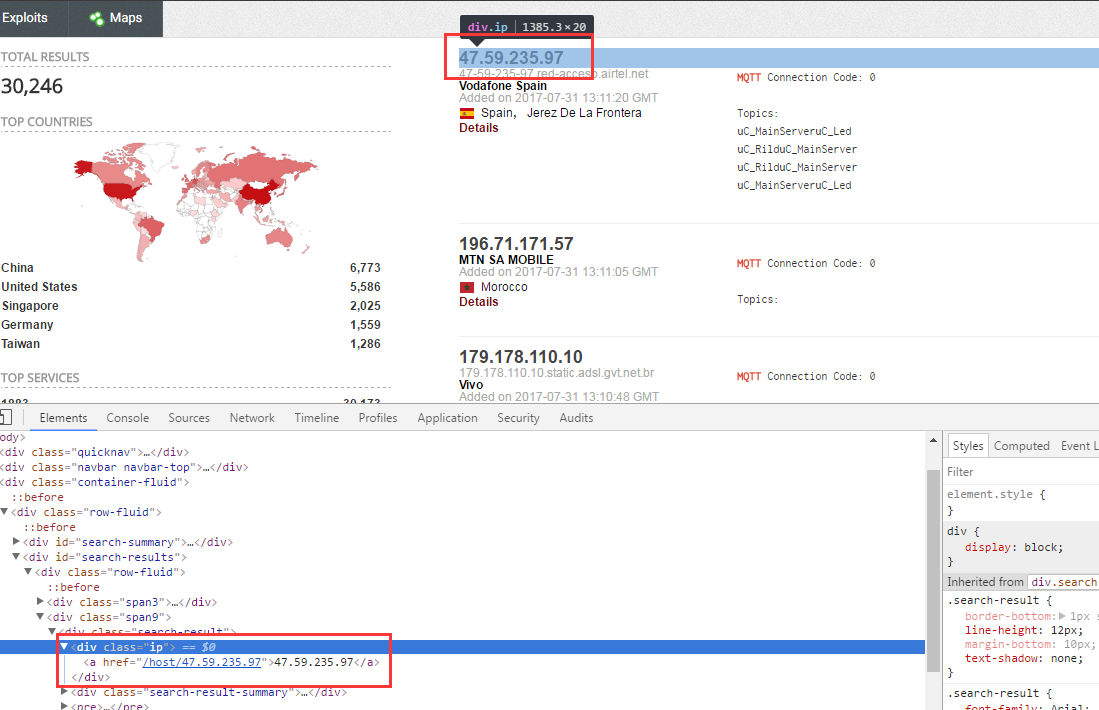
然后控制台输入以下代码:这样就把IP地址提取出来了,选中复制即可。
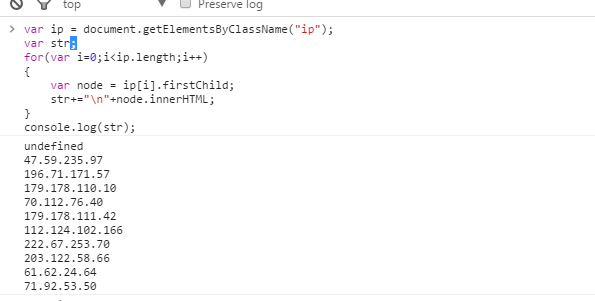
//方法1:获取标签提取
var ip = document.getElementsByClassName("ip");
var str;
for(var i=0;i<ip.length;i++)
{
var node = ip[i].firstChild;
str+="\n"+node.innerHTML;
}
console.log(str); //方法2:正则提取
var tag = document.getElementsByClassName("span9")[0];
var re = new RegExp();
var str = tag.innerHTML;
var re = /\d+\.\d+\.\d+\.\d+/g;
var arr = str.match(re);
console.log(arr);
//数组去重
arr.sort();
for(var i = 0; i < arr.length-1;) {
//用当前的元素与他的前一个元素进行对比
if(arr[i] == arr[i + 1]) {
//如果相同的话,就删除掉第i个元素
arr.splice(i, 1);
}else{ i++;}
}
console.log(arr);
3、Chrome concole介绍
console.clear(); //清空控制台信息
console.group(); //输出一组信息的开头
console.groupEnd();//结束一组信息的输出
var isTrue = false;
console.assert(isTrue,"为True时输出");
console.count();//统计代码被执行的次数,放在函数里面
console.dir(myObject);//输出对象信息
console.time();//计时开始
console.timeEnd();//计时结束 支持jQuery选择器;
copy(document.body);将控制台获取到的内容复制到粘贴板
keys(myObj);输出key
values(myObj);输出value 快捷键:
ctrl+回车;//不执行换到下一行
上下箭头,翻看执行过的代码
Console的具体方法:
4、总结
想掌握concole的用法,打开浏览器多操作几遍就掌握住了。
使用Chrome console提取页面数据的更多相关文章
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(2)
上半部分内容链接 : https://www.cnblogs.com/lowmanisbusy/p/9069330.html 四.json和jsonpath的使用 JSON(JavaScript Ob ...
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(1)
一.数据类型及解析方式 一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值.内容一般分为两部分,非结构化的数据 和 结构化的数据. 非结构化数据:先有数据,再有结构, 结构化数 ...
- chrome console的使用 : 异常和错误的处理 – Break易站
本文内容来自:chrome console的使用 : 异常和错误的处理 – Break易站 利用 Chrome DevTools 提供的工具,您可以修复引发异常的网页和在 JavaScript 中调试 ...
- 爬虫(二)Python网络爬虫相关基础概念、爬取get请求的页面数据
什么是爬虫 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程. 哪些语言可以实现爬虫 1.php:可以实现爬虫.php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆 ...
- python爬虫解析页面数据的三种方式
re模块 re.S表示匹配单行 re.M表示匹配多行 使用re模块提取图片url,下载所有糗事百科中的图片 普通版 import requests import re import os if not ...
- 用chrome console实现自动化操作网页
因为chrome console只能访问当前页的上下文(以及chrome扩展的上下文),无法访问其他标签页面的上下文,所以局限性较大,仅适用于一些较简单的操作 经实践,可以在chrome的一个标签页的 ...
- Chrome扩展开发之三——Chrome扩展中的数据本地存储和下载
目录: 0.Chrome扩展开发(Gmail附件管理助手)系列之〇——概述 1.Chrome扩展开发之一——Chrome扩展的文件结构 2.Chrome扩展开发之二——Chrome扩展中脚本的运行机制 ...
- 转:SQL SERVER数据库中实现快速的数据提取和数据分页
探讨如何在有着1000万条数据的MS SQL SERVER数据库中实现快速的数据提取和数据分页.以下代码说明了我们实例中数据库的“红头文件”一表的部分数据结构: CREATE TABLE [dbo]. ...
- 从奥鹏一个答案提取页面 看jquery知识点
http://oldlearn.open.com.cn/OEMSExercise/HomeworkReview.aspx?HomeworkId=9c034488-0a3d-4b9d-a6cc-e42 ...
随机推荐
- delphi Table切换控件顺序问题
delphi Table切换控件顺序问题 Tagorder的值就是确定Table键切换顺序的 以上做法只能解决同一类型的多个控件(如Edit1,edit2....)显示顺序问题 假如有不同类型的控件如 ...
- LightOJ 1094 - Farthest Nodes in a Tree
http://lightoj.com/volume_showproblem.php?problem=1094 树的直径是指树的最长简单路. 求法: 两遍BFS :先任选一个起点BFS找到最长路的终点, ...
- Magicodes.NET框架之路[转]
插件式框架 响应式布局以及前后端对移动设备的支持 便捷的业务代码生成,比如CRUD生成,并且表单支持根据不同数据类型或特性生成相应的展示组件. 从框架到插件包括代码生成模板均走开源路线,便于理解和定制 ...
- Android 增量更新研究
Android 增量更新实例(Smart App Updates) http://blog.csdn.net/duguang77/article/details/17676797 Android AP ...
- 设置和获取html、文本和值
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- PLSQL基本操作手册
第1章 用PLSQL连接Oracle数据库 PLSQL只能用来连接Oracle数据库(不象PB还可以连接JDBC.ODBC),所以必须首先安装并配置Oracle客户端. §1.1 初次登录PLSQL ...
- 洛谷P5050 【模板】多项式多点求值
传送门 人傻常数大.jpg 因为求逆的时候没清零结果调了几个小时-- 前置芝士 多项式除法,多项式求逆 什么?你不会?左转你谷模板区,包教包会 题解 首先我们要知道一个结论\[f(x_0)\equiv ...
- css中的左右垂直居中的问题,可兼容各种版本浏览器的写法
如题分为垂直居中,左右居中,先挑简单的记录. 一.左右居中 1.我刚开始写代码的时候,老师就直接告诉我一个简单的方法,那就是: width:500px; height:200px; margin:0 ...
- css3 -webkit-filter
-webkit-filter是css3的一个属性,Webkit率先支持了这几个功能,感觉效果很不错.下面咱们就学习一下filter这个属性吧. 现在规范中支持的效果有: grayscale 灰度 ...
- 963 AlvinZH打怪刷经验(背包DP大作战R)
963 AlvinZH打怪刷经验 思路 这不是一道普通的01背包题.大家仔细观察数据的范围,可以发现如果按常理来的话,背包容量特别大,你也会TLE. 方法一:考虑01背包的一个常数优化----作用甚微 ...