chapter02 三种决策树模型:单一决策树、随机森林、GBDT(梯度提升决策树) 预测泰坦尼克号乘客生还情况
单一标准的决策树:会根每维特征对预测结果的影响程度进行排序,进而决定不同特征从上至下构建分类节点的顺序。Random Forest Classifier:使用相同的训练样本同时搭建多个独立的分类模型,然后通过投票的方式,以少数服从多数的原则做出最终的分类决策。随机选取特征。GBDT:按照一定次序搭建多个分类模型,模型之间存在依赖关系,一般,每一个后续加入的模型都需要对集成模型的综合性能有所贡献,最终期望整合多个弱分类器,搭建出具有更强分类能力的模型。
#coding=utf8
# 导入pandas用于数据分析。
import pandas as pd
# 从sklearn.tree中导入决策树分类器。
from sklearn.tree import DecisionTreeClassifier
# 使用随机森林分类器进行集成模型的训练以及预测分析。
from sklearn.ensemble import RandomForestClassifier
# 使用梯度提升决策树进行集成模型的训练以及预测分析。
from sklearn.ensemble import GradientBoostingClassifier
# 从sklearn.model_selection中导入train_test_split用于数据分割。
from sklearn.model_selection import train_test_split
# 我们使用scikit-learn.feature_extraction中的特征转换器
from sklearn.feature_extraction import DictVectorizer
# 依然使用sklearn.metrics里面的classification_report模块对预测结果做更加详细的分析。
from sklearn.metrics import classification_report
titanic = pd.read_csv('./Datasets/Titanic/train.csv')
# 机器学习有一个不太被初学者重视,并且耗时,但是十分重要的一环,特征的选择,这个需要基于一些背景知识。根据我们对这场事故的了解,sex, age, pclass这些都很有可能是决定幸免与否的关键因素。
print titanic.info()
X = titanic[['Pclass', 'Age', 'Sex']]
y = titanic['Survived']
# 对当前选择的特征进行探查。
X['Age'].fillna(X['Age'].mean(), inplace=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state = 33)
vec = DictVectorizer(sparse=False)
# 转换特征后,我们发现凡是类别型的特征都单独剥离出来,独成一列特征,数值型的则保持不变。
X_train = vec.fit_transform(X_train.to_dict(orient='record'))
# 同样需要对测试数据的特征进行转换。
X_test = vec.transform(X_test.to_dict(orient='record'))
# 使用默认配置初始化单一决策树分类器。
dtc = DecisionTreeClassifier()
# 使用分割到的训练数据进行模型学习。
dtc.fit(X_train, y_train)
# 用训练好的决策树模型对测试特征数据进行预测。
y_predict = dtc.predict(X_test)
# 使用随机森林分类器进行集成模型的训练以及预测分析。
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
rfc_y_pred = rfc.predict(X_test)
# 使用梯度提升决策树进行集成模型的训练以及预测分析。
gbc = GradientBoostingClassifier()
gbc.fit(X_train, y_train)
gbc_y_pred = gbc.predict(X_test)
print dtc.score(X_test, y_test)
# 输出更加详细的分类性能。
print classification_report(y_predict, y_test, target_names = ['died', 'survived'])
# 输出随机森林分类器在测试集上的分类准确性,以及更加详细的精确率、召回率、F1指标。
print 'The accuracy of random forest classifier is', rfc.score(X_test, y_test)
print classification_report(rfc_y_pred, y_test)
# 输出梯度提升决策树在测试集上的分类准确性,以及更加详细的精确率、召回率、F1指标。
print 'The accuracy of gradient tree boosting is', gbc.score(X_test, y_test)
print classification_report(gbc_y_pred, y_test)
单一决策树结果:

随机森林,GDBT结果:
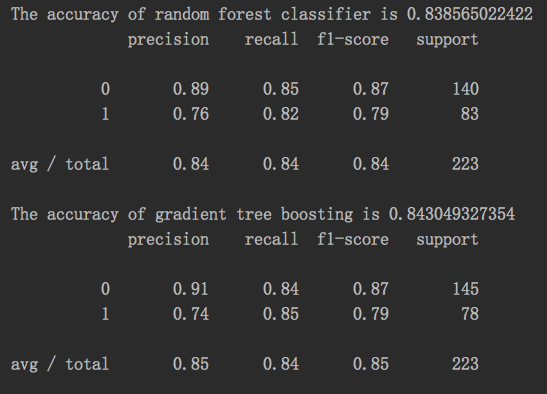
预测性能: GDBT最佳,随机森林次之
一般,工业界为了追求更加强劲的预测性能,使用随机森林作为基线系统(Baseline System)。
chapter02 三种决策树模型:单一决策树、随机森林、GBDT(梯度提升决策树) 预测泰坦尼克号乘客生还情况的更多相关文章
- GBDT 梯度提升决策树简述
首先明确一点,gbdt 无论用于分类还是回归一直都是使用的CART 回归树.不会因为我们所选择的任务是分类任务就选用分类树,这里面的核心是因为gbdt 每轮的训练是在上一轮的训练的残差基础之上进行训练 ...
- 机器学习之路:python 集成分类器 随机森林分类RandomForestClassifier 梯度提升决策树分类GradientBoostingClassifier 预测泰坦尼克号幸存者
python3 学习使用随机森林分类器 梯度提升决策树分类 的api,并将他们和单一决策树预测结果做出对比 附上我的git,欢迎大家来参考我其他分类器的代码: https://github.com/l ...
- 【深度森林第三弹】周志华等提出梯度提升决策树再胜DNN
[深度森林第三弹]周志华等提出梯度提升决策树再胜DNN 技术小能手 2018-06-04 14:39:46 浏览848 分布式 性能 神经网络 还记得周志华教授等人的“深度森林”论文吗?今天, ...
- 机器学习之路:python 集成回归模型 随机森林回归RandomForestRegressor 极端随机森林回归ExtraTreesRegressor GradientBoostingRegressor回归 预测波士顿房价
python3 学习机器学习api 使用了三种集成回归模型 git: https://github.com/linyi0604/MachineLearning 代码: from sklearn.dat ...
- Spark2.0机器学习系列之6:GBDT(梯度提升决策树)、GBDT与随机森林差异、参数调试及Scikit代码分析
概念梳理 GBDT的别称 GBDT(Gradient Boost Decision Tree),梯度提升决策树. GBDT这个算法还有一些其他的名字,比如说MART(Multiple Addi ...
- C++二级指针第三种内存模型
#include "stdio.h" #include "stdlib.h" #include "string.h" void main() ...
- ESPlatform 支持的三种群集模型 —— ESFramework通信框架 4.0 进阶(09)
对于最多几千人同时在线的通信应用,通常使用单台服务器就可以支撑.但是,当同时在线的用户数达到几万.几十万.甚至百万的时候,我们就需要很多的服务器来分担负载.但是,依据什么规则和结构来组织这些服务器,并 ...
- Reactor三种线程模型与Netty线程模型
文中所讲基本都是以非阻塞IO.异步IO为基础.对于阻塞式IO,下面的编程模型几乎都不适用 Reactor三种线程模型 单线程模型 单个线程以非阻塞IO或事件IO处理所有IO事件,包括连接.读.写.异常 ...
- HTTPD三种工作模型
HTTPD三种工作模型 MPM是apache的多道处理模块,用于定义apache对客户端请求的处理方式.在linux中apache常用的三种MPM模型分别是prefork.worker和event. ...
随机推荐
- Netcat使用方法
netcat被誉为网络安全界的‘瑞士军刀',相信没有什么人不认识它吧...... 一个简单而有用的工具,透过使用TCP或UDP协议的网络连接去读写数据.它被设计成一个稳定的后门工具,能够直接由其它 ...
- Admin管理后台
Django奉行Python的内置电池哲学.它自带了一系列在Web开发中用于解决常见问题或需求的额外的.可选工具.这些工具和插件,例如django.contrib.redirects都必须在setti ...
- docker 出现 Error response from daemon
第一步:通过dig @114.114.114.114 registry-1.docker.io找到可用IP navy@deepin:~/Desktop$ dig @.docker.io ; <& ...
- C#中使用Log4记录日志
具体步骤如下: 从网上下载log4net对应.net版本的dll 在C#项目中引用该dll 创建log4net对应的配置文件 在程序中使用 log4net的配置文件如下: <?xml versi ...
- eclipse启动时弹出Failed to create the Java Virtual Machine
eclipse启动时弹出Failed to create the Java Virtual Machine 一.现象 今天装eclipse的时候出现Failed to create the Java ...
- 雷林鹏分享:Ruby 循环
Ruby 循环 Ruby 中的循环用于执行相同的代码块若干次.本章节将详细介绍 Ruby 支持的所有循环语句. Ruby while 语句 语法 while conditional [do] code ...
- python打印cookies获取cookie
def test_002_buy_ticket(self): data = [{"}] print(data) data = json.dumps(data) cookies = self. ...
- Jersey 2.x 基于 Servlet 的服务器端应用
下面的依赖通常应用到应用服务器上(servlet 容器),同时这个应用服务器上没有整合任何 JAX-RS 的实现. 因此,这个应用服务器需要包含有 JAX-RS API 和 Jersey 实现,同时部 ...
- ajax post data 获取不到数据,注意contentType
$.ajax({ url:'/web/register/', type:"POST", data:{'user':'66'}, dataType:'json', 这个东西困惑我一天 ...
- JDBC连接SQLSERVER
package xhs;import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; im ...