scrapy微信爬虫使用总结
scrapy+selenium+Chrome+微信公众号爬虫
概述
1、微信公众号爬虫思路:
2、scrapy框架图
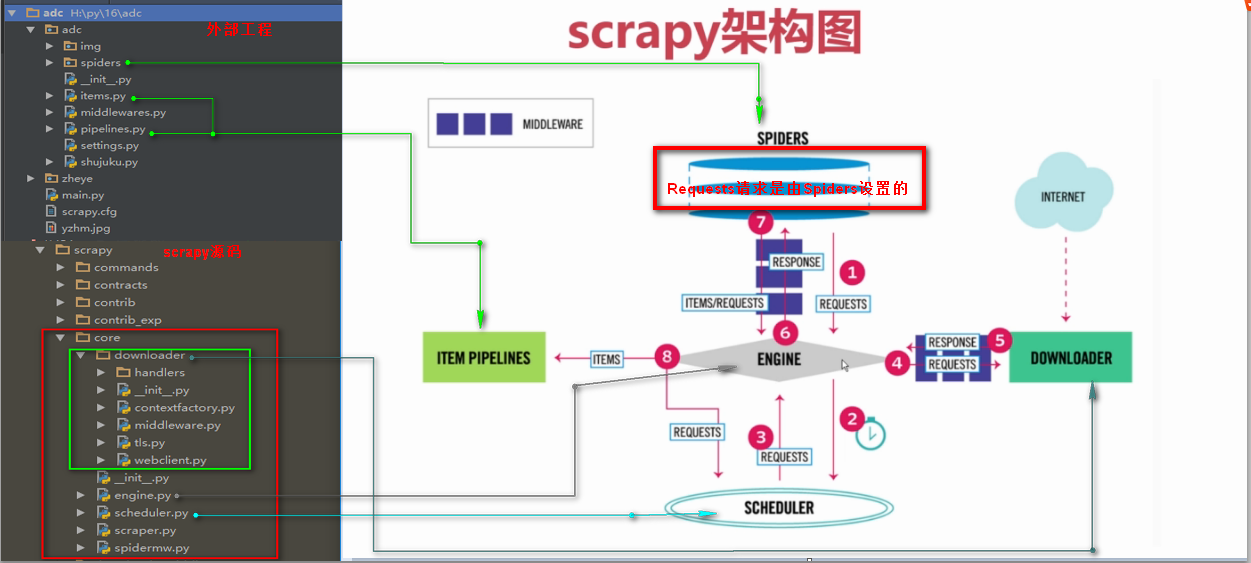
3、scrapy经典教程
参考:
4、其它
参考:
实践
1、环境的安装
- selenium安装(pip install selenium)
- chromedriver安装(注意与chrome版本兼容问题)
- beautifulsoup4
- scrapy
- MongoDB、pymongo
MongoDB:
具体命令如下:
python连接MongoDB,需安装pip install mongoengine
启动:
sudo ./mongod --port 27017 dbpath "/software/mongodb-4.0.0/data/db" --logpath "/software/mongodb-4.0.0/log/mongodb.log" --logappend --replSet rs0
Windows下MongoDB数据导出:
mongodump --port 27017 -d wechat -o D:\MongoDB
Linux下MongoDB数据导入:
./mongorestore -h 127.0.0.1 --port 27017 -d wechat --drop /software/mongodb-4.0.0/wechat
数据导入时注意:
Do you run mongo in replica set, i.e., mongod --replSet rs0?
If yes, please remember to run in your mongo shell the command: rs.initiate()
参考:
2、cookie获取
selenium进行登录验证,保存cookies,为scrapy做准备。
3、爬虫
- cookies:scrapy spider初始化函数调用Chromedriver,并获取cookies
- 定位:spider初始化函数利用Chromedriver定位到需要抓取的页面
- 解析:parse函数处理Chromedriver自动定scrapy爬虫利用selenium实现用户登录和cookie传递位的页面信息,以及下一页URL
- 保存:scrapy配置MongoDB保存数据
参考:
scrapy爬虫利用selenium实现用户登录和cookie传递
4、django调用爬虫
5、django构建搜索引擎,搜索爬过的信息
参考:
环境配置:
elasticsearch-rtf安装、pip install mongo-connector、pip install mongo-connector[elastic5]、pip install elastic2-doc-manager
MongoDB数据同步到elasticsearch:
mongo-connector -m localhost:27017 -t localhost:9200 -d elastic2_doc_manager
其它问题
1、selenium在新页面定位元素问题
参考:
解决Selenium弹出新页面无法定位元素问题(Unable to locate element)
3、在管道中关闭爬虫
spider.crawler.engine.close_spider(spider, 'bandwidth_exceeded')
scrapy微信爬虫使用总结的更多相关文章
- 爬虫学习之基于Scrapy的爬虫自动登录
###概述 在前面两篇(爬虫学习之基于Scrapy的网络爬虫和爬虫学习之简单的网络爬虫)文章中我们通过两个实际的案例,采用不同的方式进行了内容提取.我们对网络爬虫有了一个比较初级的认识,只要发起请求获 ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- Scrapy框架-----爬虫
说明:文章是本人读了崔庆才的Python3---网络爬虫开发实战,做的简单整理,希望能帮助正在学习的小伙伴~~ 1. 准备工作: 安装Scrapy框架.MongoDB和PyMongo库,如果没有安装, ...
- Scrapy创建爬虫项目
1.打开cmd命令行工具,输入scrapy startproject 项目名称 2.使用pycharm打开项目,查看项目目录 3.创建爬虫,打开CMD,cd命令进入到爬虫项目文件夹,输入scrapy ...
- Scrapy - CrawlSpider爬虫
crawlSpider 爬虫 思路: 从response中提取满足某个条件的url地址,发送给引擎,同时能够指定callback函数. 1. 创建项目 scrapy startproject mysp ...
- 【Python爬虫实战】微信爬虫
所谓微信爬虫,即自动获取微信的相关文章信息的一种爬虫.微信对我们的限制是很多的,所以我们需要采取一些手段解决这些限制主要包括伪装浏览器.使用代理IP等方式http://weixin.sogou.com ...
- 第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点 1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
随机推荐
- HTTP从入门到入土(5)——HTTP报文格式
HTTP报文格式 HTTP报文分为请求报文和响应报文,只有发送了请求报文,才会有响应报文. 常见的报文格式如下所示:
- web前端----JavaScript的BOM
一.引入 到目前为止,我们已经学过了JavaScript的一些简单的语法.但是这些简单的语法,并没有和浏览器有任何交互. 也就是我们还不能制作一些我们经常看到的网页的一些交互,我们需要继续学习BOM和 ...
- Centos下安装git高版本2.1.2
安装依赖软件 # yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel asciidoc # yum in ...
- Android实践项目汇报(总结)-修改
天气客户端开发报告 1系统需求分析 1.1功能性需求分析 天气预报客户端,最基本就是为用户提供准确的天气预报信息.天气查询结果有两种:一种是当天天气信息,信息结果比较详细,除温度.天气状况外还可以提示 ...
- Program Size
在Keil中编译工程成功后,在下面的Bulid Ouput窗口中会输出下面这样一段信息: Program Size: Code=6320 RO-data=4864 RW-data=44 ZI-d ...
- 【转】iOS学习之iOS禁止Touch事件
iOS程序中有时会有需要禁止应用接收Touch的要求(比如动画进行时,防止触摸事件触发新方法). 一.一般有两种: 1.弄个遮罩层,禁止交互: 2.使用UIApplication中的方法进行相关的交互 ...
- SQL数据插入字符串时转义函数
函数一: std::string CheckString(std::string& strSource) { std::string strOldValue = "'"; ...
- Ansible 入门指南 - 常用模块
介绍 module 文档: 官宣-模块分类的索引 官宣-全部模块的索引 在playbook脚本中,tasks 中的每一个 action都是对 module的一次调用.在每个 action中: 冒号前面 ...
- HDU 6148 Valley Numer (数位DP)题解
思路: 只要把status那里写清楚就没什么难度T^T,当然还要考虑前导零! 代码: #include<cstdio> #include<cstring> #include&l ...
- Adobe Reader 2019 Offline Installer, Free Download - Best PDF Reader
https://ridnt-b.blogspot.com/2018/01/adobe-reader-2018-free-download.html http://ardownload.adobe.co ...