MapReduce 开发环境搭建(Eclipse\MyEclipse + Maven)
写在前面的话
可详细参考,一定得去看
HBase 开发环境搭建(Eclipse\MyEclipse + Maven)
Zookeeper项目开发环境搭建(Eclipse\MyEclipse + Maven)
Hive项目开发环境搭建(Eclipse\MyEclipse + Maven)
我这里,相信,能看此博客的朋友,想必是有一定基础的了。我前期写了大量的基础性博文。可以去补下基础。
步骤一:File -> New -> Project -> Maven Project
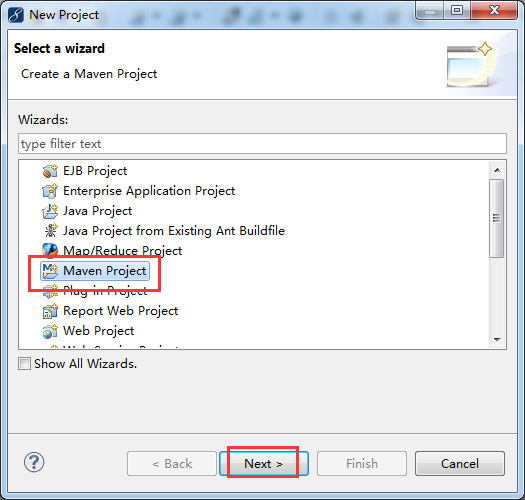
步骤二:自行设置,待会创建的myHBase工程,放在哪个目录下。

步骤三:
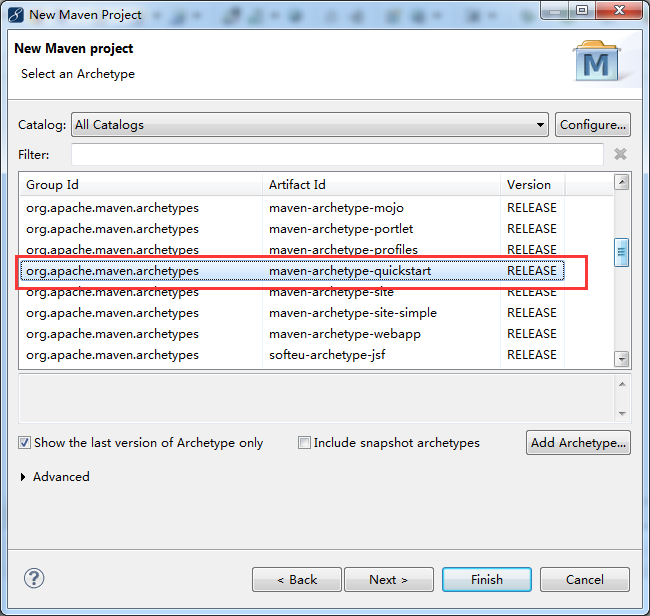
步骤四:自行设置

步骤五:修改jdk

省略,很简单!
步骤六:修改pom.xml配置文件

官网Maven的zookeeper配置文件内容:
地址:http://www.mvnrepository.com/search?q=mapreduce


因为我的hadoop版本是hadoop-2.6.0
参考: http://blog.csdn.net/e421083458/article/details/45792111
1、

2、


暂时这些吧,以后需要,可以自行再加呢!
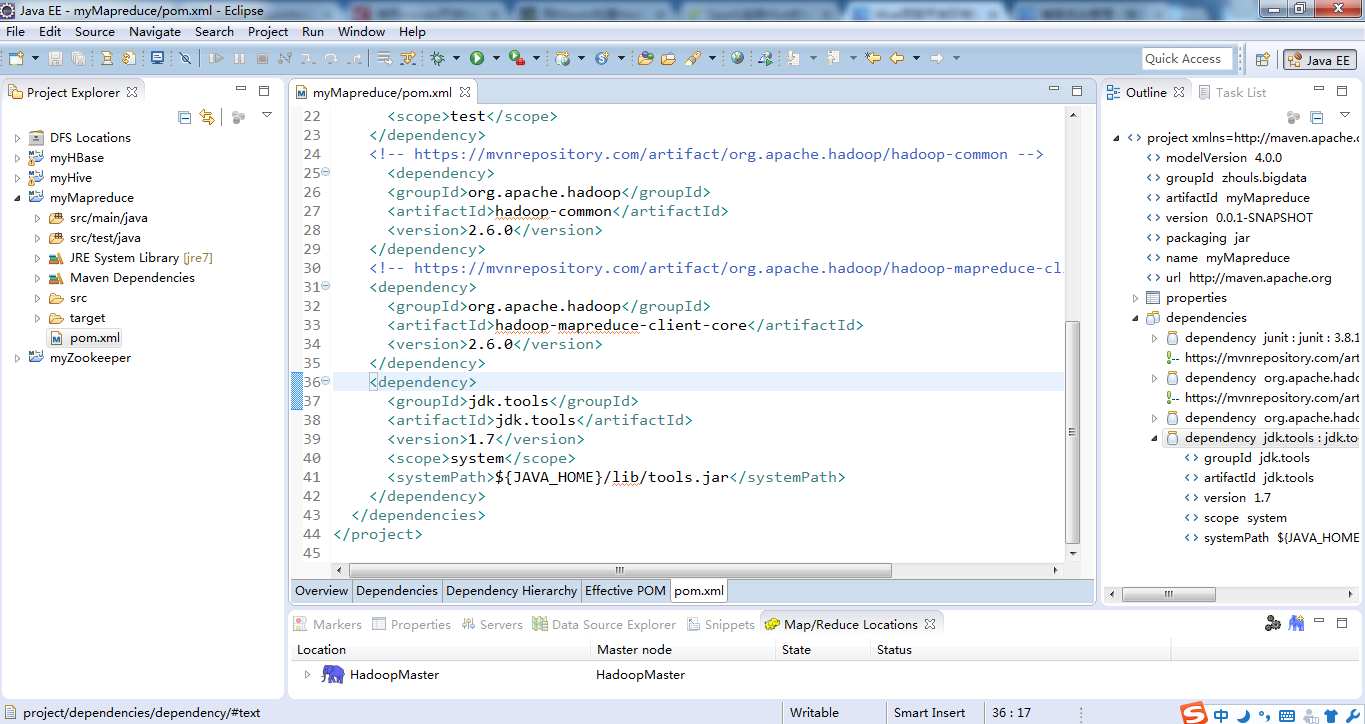
最后的pom.xml配置文件为
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>zhouls.bigdata</groupId>
<artifactId>myMapreduce</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>myMapreduce</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.0</version>
</dependency>
</dependencies>
</project>
当然,这只是初步而已,最简单的,以后可以自行增删。
步骤七:这里,给大家,通过一组简单的Hive应用程序实例来向大家展示Hive的某些功能。
类名为MapReduceTestCase.java

package zhouls.bigdata.myMapreduce;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MapReduceTestCase
{
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(MapReduceTestCase.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("hdfs:/HadoopMaster:9000/djt.txt"));
FileOutputFormat.setOutputPath(job, new Path("hdfs:/HadoopMaster:9000/word-count"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
或者
package zhouls.bigdata.myMapreduce;
import java.io.IOException;
import java.util.regex.Pattern;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* 基于样本数据做Hadoop工程师薪资统计:计算各工作年限段的薪水范围
*/
public class SalaryCount extends Configured implements Tool
{
public static class SalaryMapper extends Mapper<LongWritable, Text, Text, Text>
{
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
{
// 美团 3-5年经验 15-30k 北京 【够牛就来】hadoop高级工程...
//北信源 3-5年经验 15-20k 北京 Java高级工程师(有Hadoo...
// 蘑菇街 3-5年经验 10-24k 杭州 hadoop开发工程师
//第一步,将输入的纯文本文件的数据转化成String
String line = value.toString();//读取每行数据
String[] record = line.split( "\\s+");//使用空格正则解析数据
//key=record[1]:输出3-5年经验
//value=record[2]:15-30k
//作为Mapper输出,发给 Reduce 端
//第二步
if(record.length >= 3)//因为取得的薪资在第3列,所以要大于3
{
context.write( new Text(record[1]), new Text(record[2]) );
//Map输出,record数组的第2列,第3列
}
}
}
public static class SalaryReducer extends Reducer< Text, Text, Text, Text>
{
public void reduce(Text Key, Iterable< Text> Values, Context context) throws IOException, InterruptedException
{
int low = 0;//记录最低工资
int high = 0;//记录最高工资
int count = 1;
//针对同一个工作年限(key),循环薪资集合(values),并拆分value值,统计出最低工资low和最高工资high
for (Text value : Values)
{
String[] arr = value.toString().split("-");//其中的一行而已,15 30K
int l = filterSalary(arr[0]);//过滤数据 //15
int h = filterSalary(arr[1]);//过滤数据 //30
if(count==1 || l< low)
{
low = l;
}
if(count==1 || h>high)
{
high = h;
}
count++;
}
context.write(Key, new Text(low + "-" +high + "k"));//即10-30K
}
}
//正则表达式提取工资值,因为15 30k,后面有k,不干净
public static int filterSalary(String salary)//过滤数据
{
String sal = Pattern.compile("[^0-9]").matcher(salary).replaceAll("");
return Integer.parseInt(sal);
}
public int run(String[] args) throws Exception
{
//第一步:读取配置文件
Configuration conf = new Configuration();//读取配置文件
//第二步:输出路径存在就先删除
Path out = new Path(args[1]);//定义输出路径的Path对象,mypath
FileSystem hdfs = out.getFileSystem(conf);//通过路径下的getFileSystem来获得文件系统
if (hdfs.isDirectory(out))
{//删除已经存在的输出目录
hdfs.delete(out, true);
}
//第三步:构建job对象
Job job = new Job(conf, "SalaryCount" );//新建一个任务
job.setJarByClass(SalaryCount.class);//设置 主类
//通过job对象来设置主类SalaryCount.class
//第四步:指定数据的输入路径和输出路径
FileInputFormat.addInputPath(job, new Path(args[0]));// 文件输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 文件输出路径
//第五步:指定Mapper和Reducer
job.setMapperClass(SalaryMapper.class);// Mapper
job.setReducerClass(SalaryReducer.class);// Reducer
//第六步:设置map函数和reducer函数的输出类型
job.setOutputKeyClass(Text.class);//输出结果key类型
job.setOutputValueClass(Text.class);//输出结果的value类型
//第七步:提交作业
job.waitForCompletion(true);//等待完成退出作业
return 0;
}
/**
* @param args 输入文件、输出路径,可在Eclipse中Run Configurations中配Arguments,如:
* hdfs://HadoopMaster:9000/salary.txt
* hdfs://HadoopMaster:9000/salary/out
*/
public static void main(String[] args) throws Exception
{
//第一步
String[] args0 =
{
"hdfs://HadoopMaster:9000/salary/",
"hdfs://HadoopMaster:9000/salary/out"
};
//第二步
int ec = ToolRunner.run(new Configuration(), new SalaryCount(), args0);
//第一个参数是读取配置文件,第二个参数是主类Temperature,第三个参数是输如路径和输出路径的属组
System.exit(ec);
}
}
MapReduce 开发环境搭建(Eclipse\MyEclipse + Maven)的更多相关文章
- 基于 Eclipse 的 MapReduce 开发环境搭建
文 / vincentzh 原文连接:http://www.cnblogs.com/vincentzh/p/6055850.html 上周末本来要写这篇的,结果没想到上周末自己环境都没有搭起来,运行起 ...
- android开发1:安卓开发环境搭建(eclipse+jdk+sdk)
计划折腾折腾安卓开发了,从0开始的确很痛苦,不过相信上手应该也不会太慢.哈哈 一.Android简介 Android 是基于Linux内核的软件平台和操作系统. Android构架主要由3部分组成,l ...
- Linux学习总结(十)—— Java开发环境搭建:JDK+Maven
Java开发环境最基础的两个开源软件是JDK和Maven. JDK 到Oracle官网下载相对应的源码包,这里我选择的是:Linux x64系统的jdk-8u131-linux-x64.tar.gz. ...
- JavaWeb开发环境搭建Eclipse配置Tomcat
转载请标明出处:http://blog.csdn.net/wu_wxc/article/details/48651251本文出自[吴孝城的CSDN博客] 工具: Eclipse官网下载:http:// ...
- mac下搭建java开发环境:eclipse+tomcat+maven
一.安装eclipse 直接下载 二.安装JDK 下载mac版专用的jdk1.7,地址如下:http://jdk7.java.net/macportpreview/, 确认java使用的版本:开一个终 ...
- Java WEB开发环境搭建以及创建Maven Web项目
根据此链接博文学习配置: http://www.cnblogs.com/zyw-205520/p/4767633.html 1.JDK的安装 自行百度,(最好是jdk1.7版本的) 测试如下图,即完成 ...
- JAVA开发环境搭建 - Eclipse基本配置
Eclipse设置的内容包括许多方面,不同的开发人员,不同的项目需要,可能对Eclipse的设置不尽相同.如下内容仅是对本人的一些基本设置做一些记录,以作备忘.后期会逐渐对相关内容进行更新,仅供参考. ...
- Ubuntu下Java开发环境搭建(eclipse)
最近把工作环境转移到了Ubuntu Kylin下,发现在这下面Java环境还是很方便的.然而也经历了一些摸索的过程,故作文以记之. 一/开发前准备 安装系统/配置软件源,这部分内容没什么需要注意的.O ...
- windows8.1下android开发环境搭建(Eclipse+Android sdk+ADT+Genymotion)
一.基本jdk.eclipse环境 二.android sdk 1.下载安装:https://developer.android.com/sdk/installing/index.html?pkg=t ...
随机推荐
- iOS开发笔记--宏定义的黑魔法 - 宏菜鸟起飞手册
宏定义在C系开发中可以说占有举足轻重的作用.底层框架自不必说,为了编译优化和方便,以及跨平台能力,宏被大量使用,可以说底层开发离开define将寸步难行.而在更高层级进行开发时,我们会将更多的重心放在 ...
- mysql 查询重复值命令
积累备忘啊: ; 从t_maintenanceinfo表查询重复记录的mtiId 和ip字段,以及重复条数
- 在linux下,查看一个运行中的程序, 占用了多少内存
1. 在linux下,查看一个运行中的程序, 占用了多少内存, 一般的命令有 (1). ps aux: 其中 VSZ(或VSS)列 表示,程序占用了多少虚拟内存. RSS列 表示, 程序占用了多少物 ...
- linux查找某个文件中单词出现的次数
文件名称:list 查找单词名称:test 操作命令: (1)more list | grep -o test | wc -l (2)cat list | grep -o test | wc -l ( ...
- editplus的配置文件来支持sql语法高亮【转】
editplus默认是没有sql语法高亮的,原因是它的内部没有sql.stx的这样一个语法文件 我们自己在 EditPlus 的安装目录下面新建一个文件名为sql.stx,然后打开editplus ...
- RxJava学习(三)
变换 所谓变换,就是将事件序列中的对象或整个序列进行加工处理,转换成不同的事件或事件序列. 1) API 首先看一个 map() 的例子: Observable.just("images/l ...
- MapReduce编程系列 — 3:数据去重
1.项目名称: 2.程序代码: package com.dedup; import java.io.IOException; import org.apache.hadoop.conf.Configu ...
- node.js模块之http模块
如果你想向远程服务器发起HTTP 连接,Node 也是很好的选择.Node 在许多情景下都很适合使用,如使用Web service,连接到文档数据库,或是抓取网页.你可以使用同样的http 模块来发起 ...
- 解决git Push时请求username和password,而不是ssh-key验证
转载自:https://blog.lowstz.org/posts/2011/11/23/why-git-push-require-username-password-github/ 之前开始用git ...
- C++重载输入和输出操作符以及IO标准库中的刷新输入缓冲区残留字符问题
今天在做C++ Primer习题的14.11时,印象中应该挺简单的一题,结果却费了很长时间. 类定义: typedef string Date; class CheckoutRecord{ publi ...