Spark天堂之门解密
本课主题
- 什么是 Spark 的天堂之门
- Spark 天堂之门到底在那里
- Spark 天堂之门源码鉴赏
引言
Spark 天堂之门就是SparkContext,这篇文章会从 SparkContext 创建3大核心对象 TaskSchedulerImpl、DAGScheduler 和 SchedulerBackend 开始到注册给 Master 这个过程中的源码鉴赏,SparkContext 是整个 Spark 程序通往集群的唯一通道,它是程序起点,也是程序终点,所以把它称之为天堂之门,看过 Spark HelloWorld 程序的朋友都知道,你在程序的开头必需先定义SparkContext、接着调用 SparkContext 的方法,比如说 sc.textFile(file),最后也会调用 sc.stop( ) 来退出应用程序。现在我们就来看看 SparkContext 里面到底有什么秘密,以及为什么它会被称为天堂之门。希望这篇文章能为读者带出以下的启发:
- 了解在 SparkContext 内部创建了哪些实例对象以及如何创建
- 了解真正是哪个实例对象向 Master 注册以及如何注册
什么是 Spark 的天堂之门
- Spark 程序在运行的时候分为 Driver 和 Executor 两部分
- Spark 程序编写是基于 SparkContext 的,具体来说包含两方面
- Spark 编程的核心基础-RDD 是由 SparkContext 来最初创建的(第一个RDD一定是由 SparkContext 来创建的)
- Spark 程序的调度优化也是基于 SparkContext,首先进行调度优化。
- Spark 程序的注册时通过 SparkContext 实例化时生产的对象来完成的(其实是 SchedulerBackend 来注册程序)
- Spark 程序在运行的时候要通过 Cluster Manager 获取具体的计算资源,计算资源获取也是通过 SparkContext 产生的对象来申请的(其实是 SchedulerBackend 来获取计算资源的)
- SparkContext 崩溃或者结束的时候整个 Spark 程序也结束啦!
Spark 天堂之门到底在那里
运行一个程序,你会看见 SparkContext 从程序开始到结束都有它的身影,SparkContext 是 Spark 应用程序的核心呀!
[下图是一个 HelloWord 应用程序在 IDEA 中的运行状况]
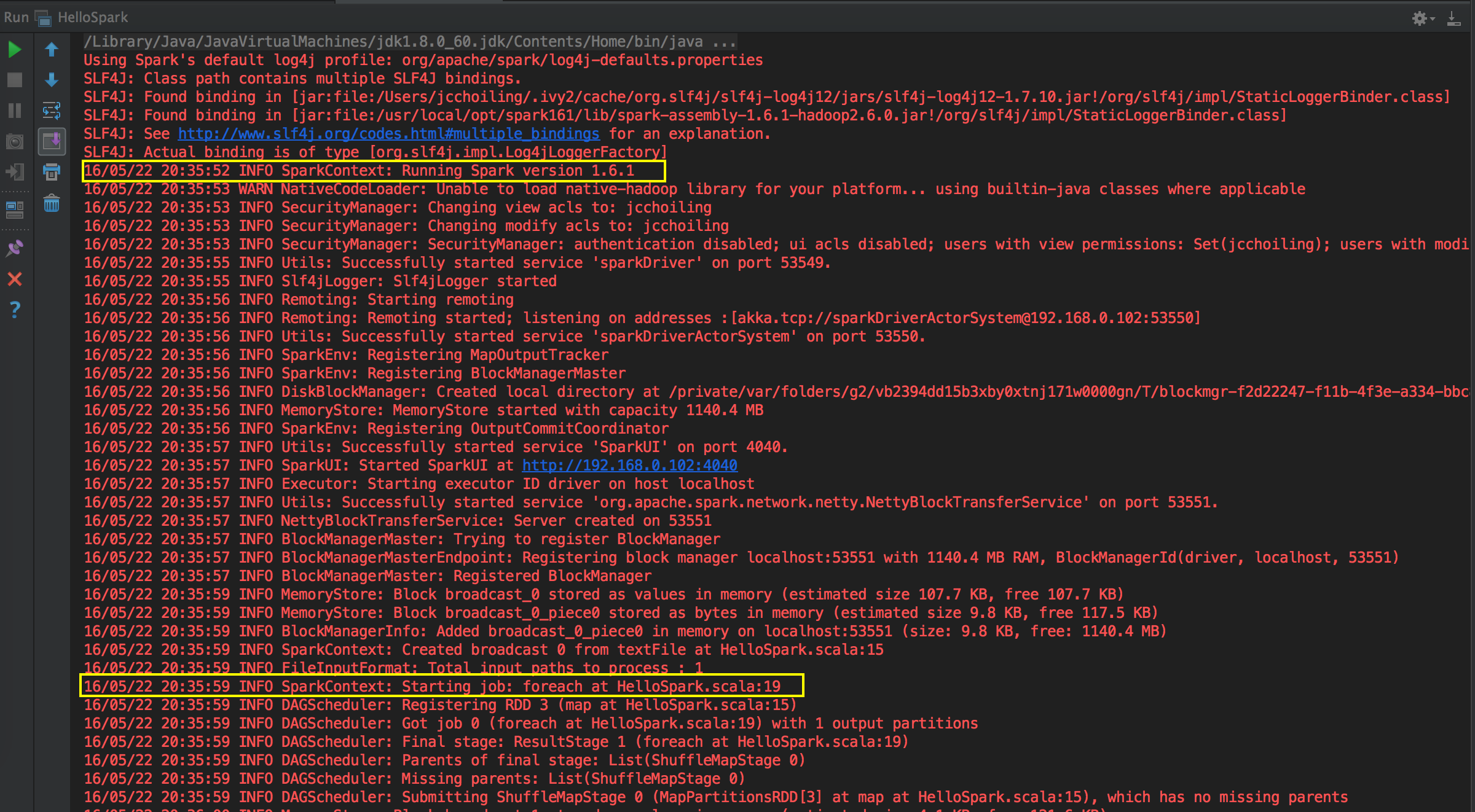
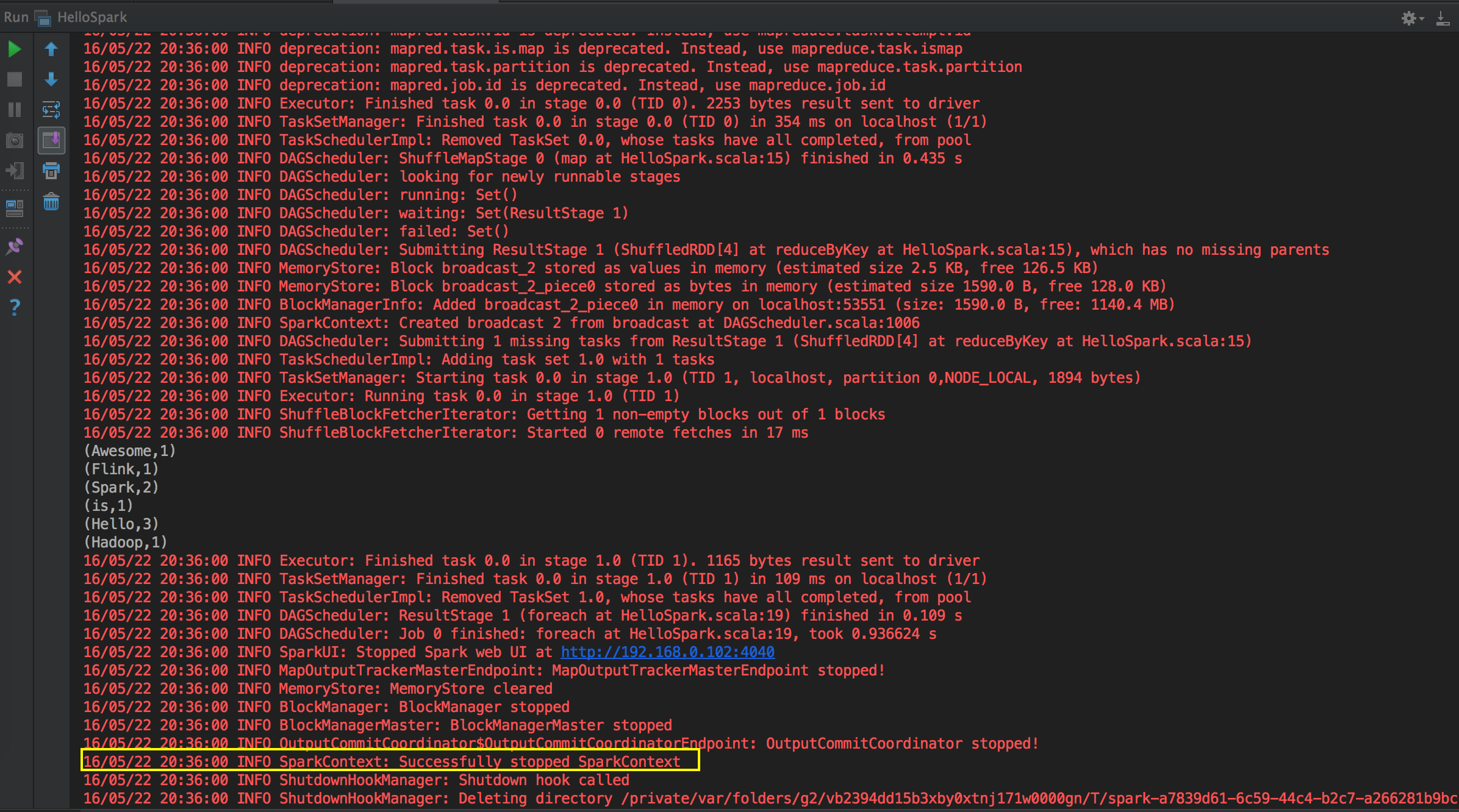
Spark 天堂之门源码鉴赏
这次主要是看当提交Spark程序后,在 SparkContext 实例化的过程中,里面会创建多少个核心实例来为应用程序完成注冊,SparkContext 最主要的是实例化 TaskSchedulerImpl。
[下图是 SparkContext 在创建核心对象后的流程图]
- SparkContext 构建的顶级三大核心:DAGScheduler, TaskScheduler, SchedulerBackend,其中:
- DAGScheduler 是面向 Job 的 Stage 的高层调度器;
- TaskScheduler 是一个接口,是低层调度器,根据具体的 ClusterManager 的不同会有不同的实现,Standalone 模式下具体的实现 TaskSchedulerImpl;
- SchedulerBackend 是一个接口,根据具体的 ClusterManager 的不同会有不同的实现,Standalone 模式下具体的实现是SparkDeploySchedulerBackend
- 从整个程序运行的角度来讲,SparkContext 包含四大核心对象:DAGScheduler, TaskScheduler, SchedulerBackend, MapOutputTrackerMaster
- SparkDeploySchedulerBackend 有三大核心功能:
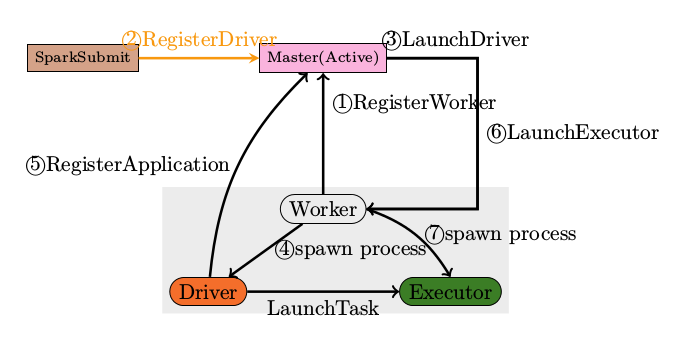
- 负责向Master 連接连接注册当前程序 RegisterWithMaster
- 接收集群中为当前应用程序而分配的计算资源 Executor 的注册并管理 Executors;
- 负责发送 Task 到具体的 Executor 執行
补充说明的是 SparkDeploySchedulerBackend 是被 TaskSchedulerImpl 来管理的!
- 程序一开始运行时会实例化 SparkContext 里的东西,所以不在方法里的成员都会被实例化!一开始实例化的时候第一个关键的代码是 createTaskScheduler,它是位于 SparkContext 的 Primary Constructor 中,当它实例化时会直接被调用,这个方法返回的是 taskScheduler 和 dagScheduler 的实例,然后基于这个内容又构建了 DAGScheduler,然后调用 taskScheduler 的 start( ) 方法,要先创建taskScheduler然后再创建 dagScheduler,因为taskScheduler是受dagScheduler管理的。
[下图是 SparkContext.scala 中的创建 schedulerBackend 和 taskSchdulerImpl 的实例对象]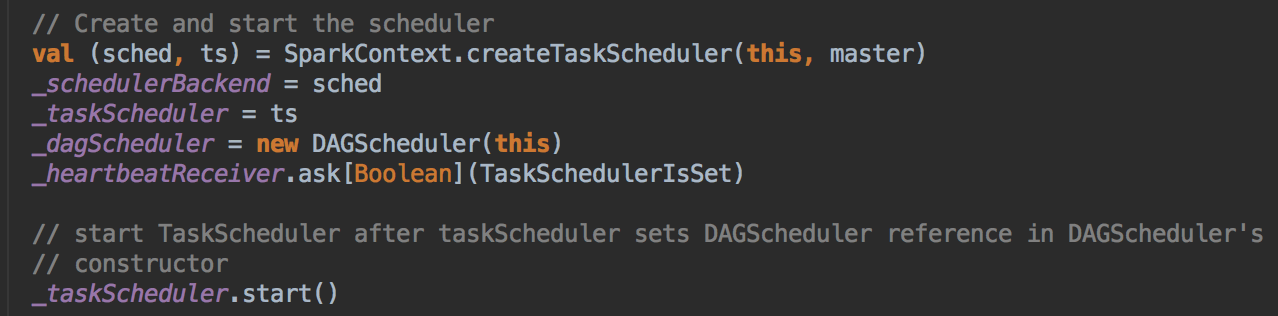
- 调用 createTaskSchedule,这个方法创建了 TaskSchdulerImpl 和 SparkDeploySchedulerBackend,接受第一个参数是 SparkContext 对象本身,然后是字符串,(这也是平时传入 master 里的字符串)
[下图是 HelloSpark.scala 中创建 SparkConf 和 SparkContext 的上下文信息]
[下图是 SparkContext.scala 中的 createTaskScheduler 方法]
- 它会判断一下你的 master 是什么然后具体进行不同的操作!假设我们是Spark 集群模式,它会:
[下图是 SparkContext.scala 中的 SparkMasterRegex 静态对象]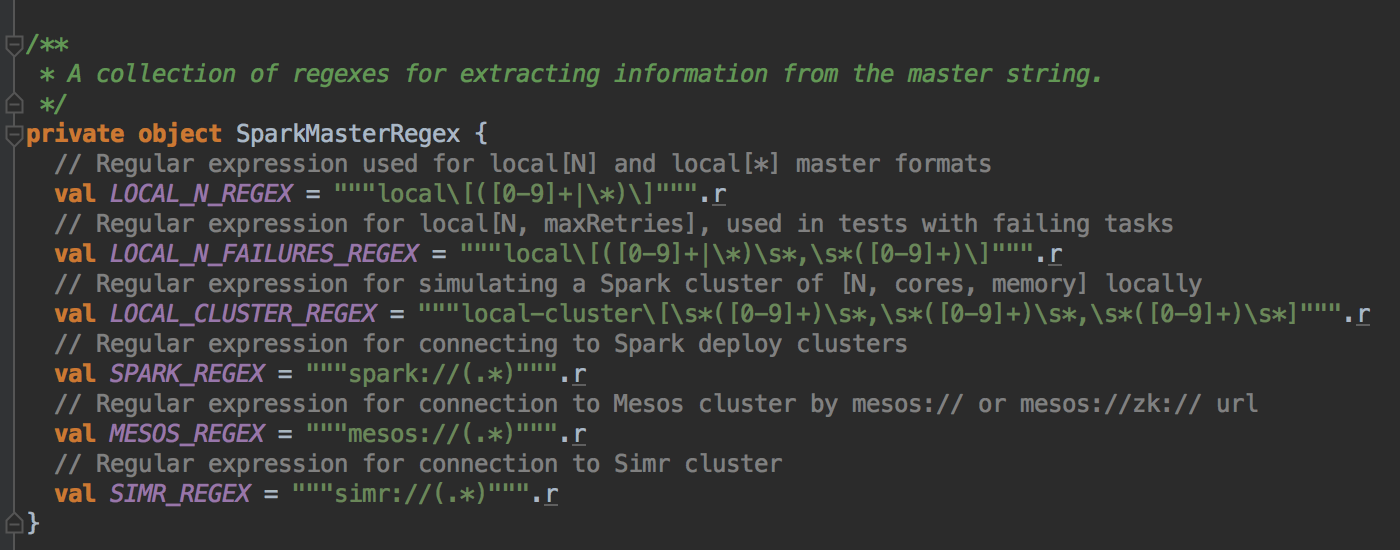
- 创建 TaskSchedulerImpl 实例然后把 SparkContext 传进去;
- 匹配集群中 master 的地址 e.g. spark://
- 创建 SparkDeploySchedulerBackend 实例,然后把 taskScheduler (这里是 TaskSchedulerImpl)、SparkContext 和 master 地址信息传进去;
- 调用 taskScheduler (这里是 TaskSchedulerImpl) 的 initialize 方法 最后返回 (SparkDeploySchedulerBackend, TaskSchedulerImpl) 的实例对象
- SparkDeploySchedulerBackend 是被 TaskSchedulerImpl 来管理的,所以这里要首先把 scheduler 创建,然后把 scheduler 的实例传进去。
[下图是 SparkContext.scala 中的调用模式匹配 SPARK_REGEX 的处理逻辑]
- Task 默认失败后重新启动次数为 4 次
[下图是 TaskSchedulerImpl.scala 中的类和主构造器的调用方法]
TaskSchedulerImpl.initialize( )方法是
- 创建一个 Pool 来初定义资源分布的模式 Scheduling Mode,默认是 先进先出的 模式。

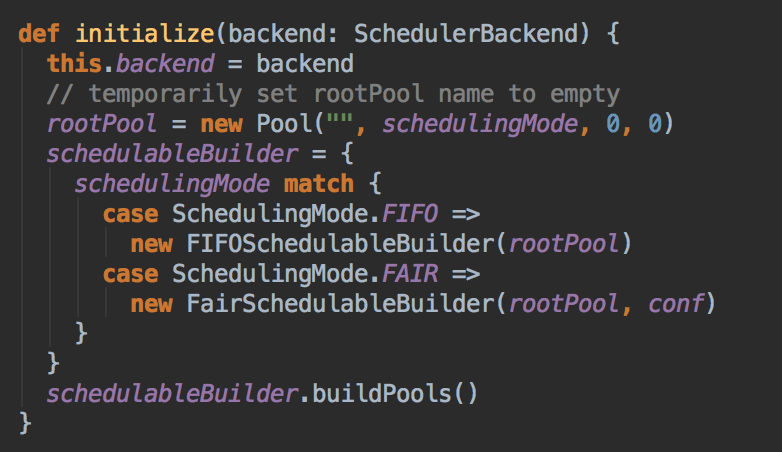
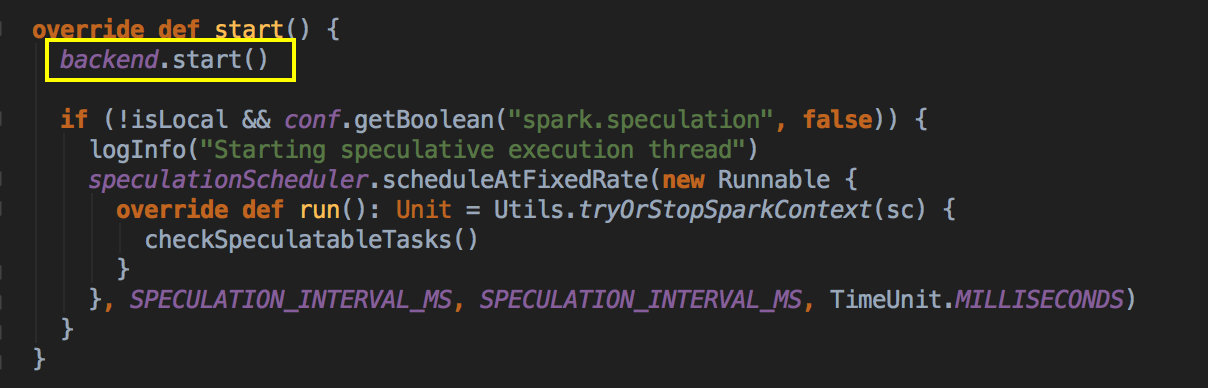
调用 taskScheduler 的 start( ) 方法
- 在这个方法中再调用 backend (SparkDeploySchedulerBackend) 的 start( ) 方法。

- 当通过 SparkDeploySchedulerBackend 注册程序给 Master 的时候会把以上的 command 提交给 Master
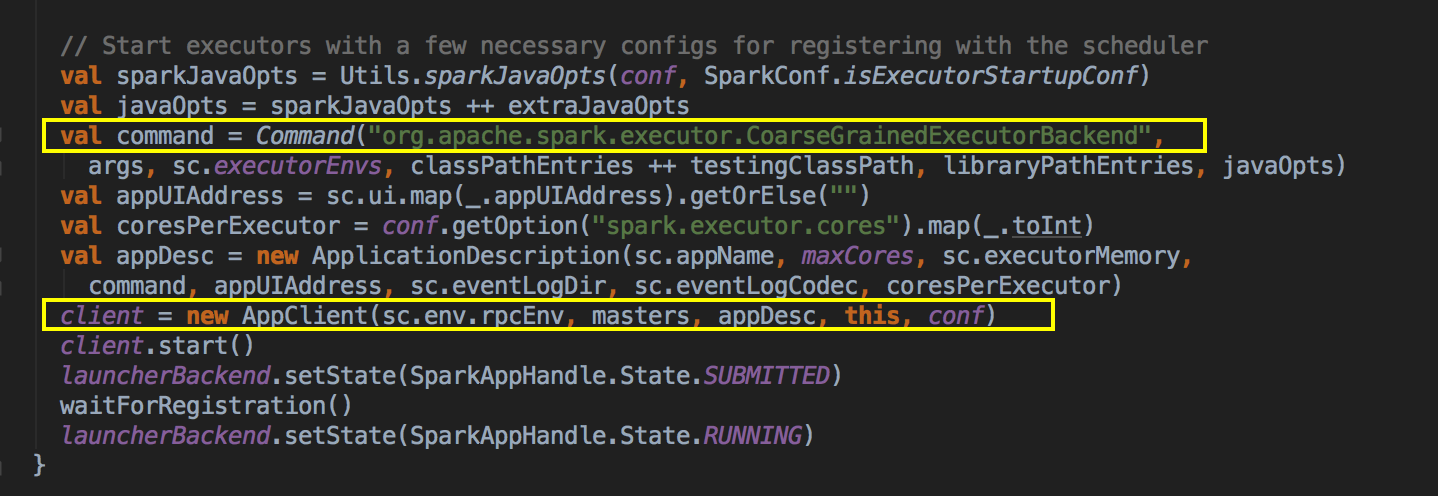
- Master 发指令给 Worker 去启动 Executor 所有的进程的时候加载的 Main 方法所在的入口类就是 command 中的CoarseGrainedExecutorBackend,当然你可以实现自己的 ExecutorBackend,在 CoarseGrainedExecutorBackend 中启动 Executor (Executor 是先注册在实例化),Executor 通过线程池并发执行 Task。
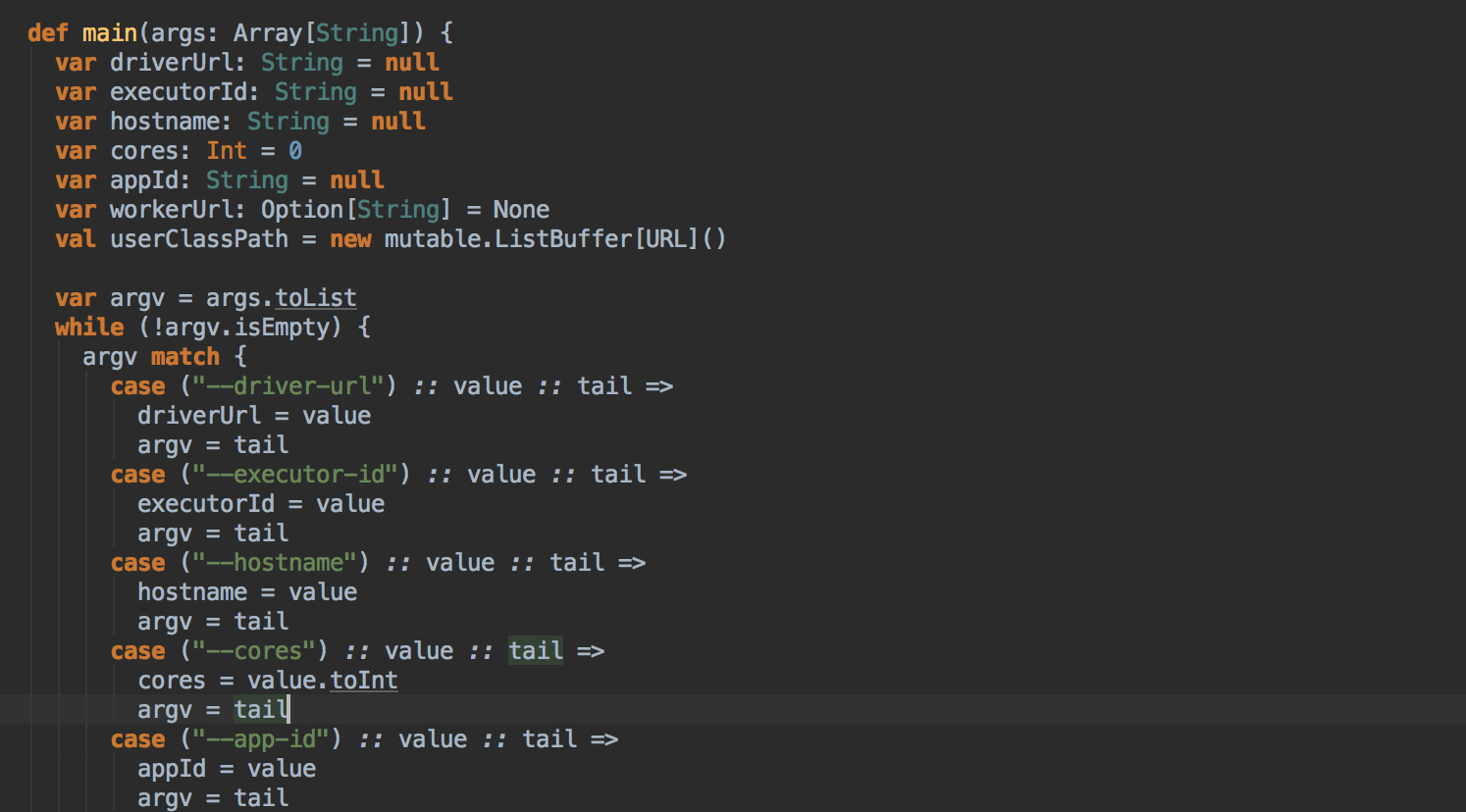
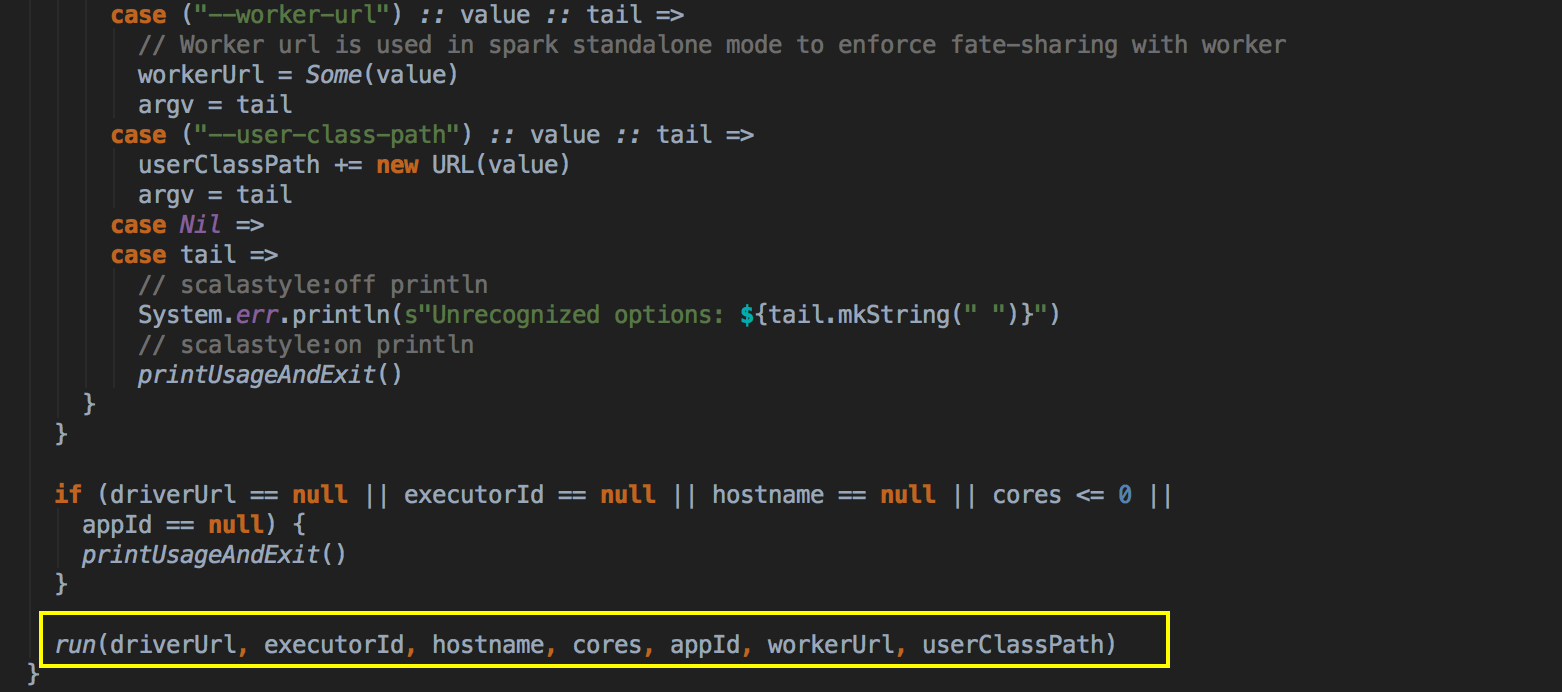
- 这里调用了它的 run 方法
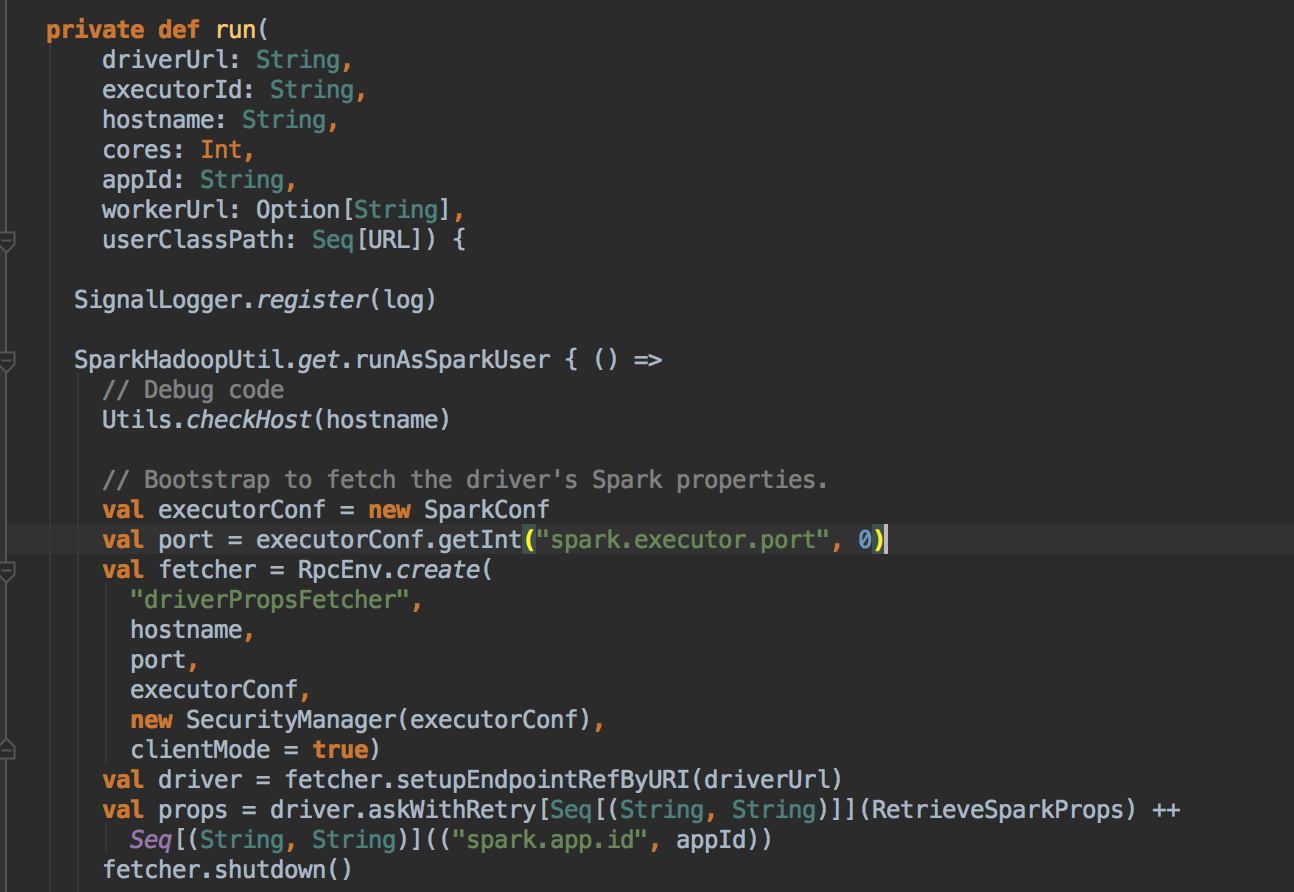
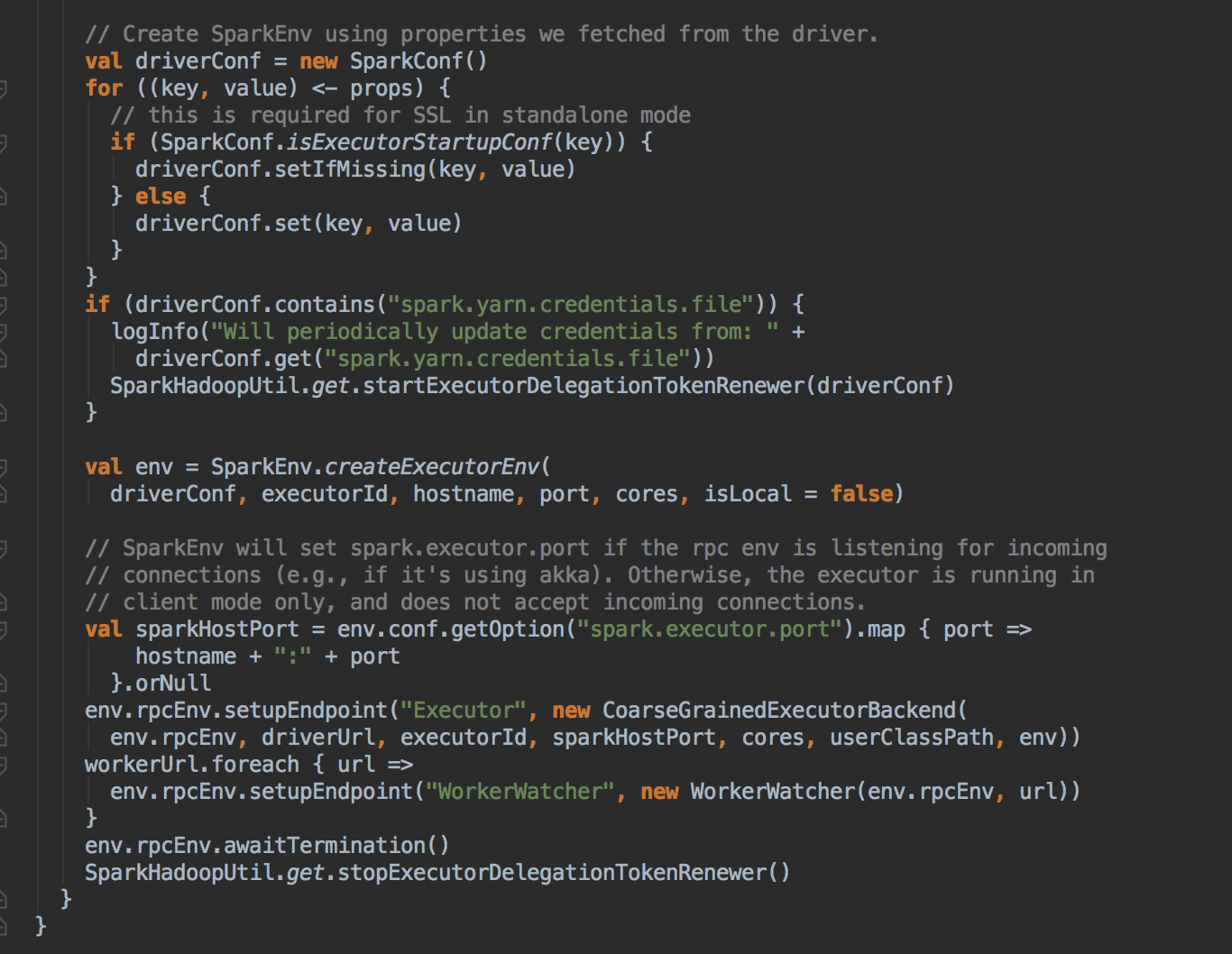
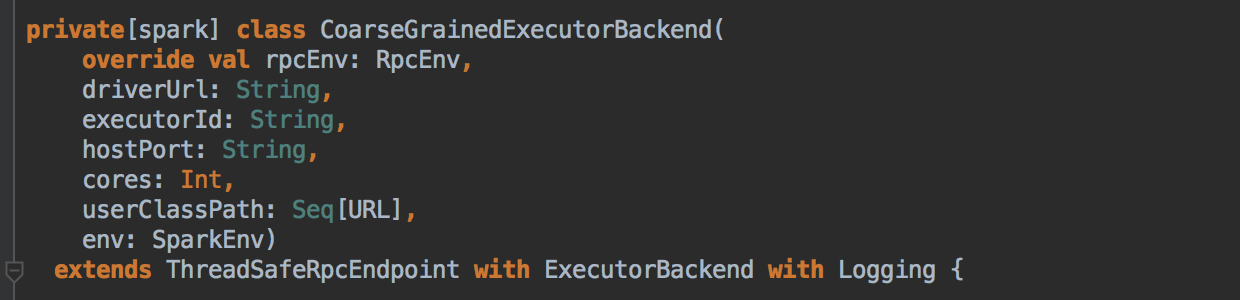
- 注册成功后再实例化

- 然后创建一个很重要的对象,AppClient 对象,然后调用它的 client (AppClient) 的 start( ) 方法,创建一个 ClientEndpoint 对象。


- 它是一个 RpcEndPoint,然后接下来的故事就是向 Master 注冊,首先调用自己的 onStart 方法
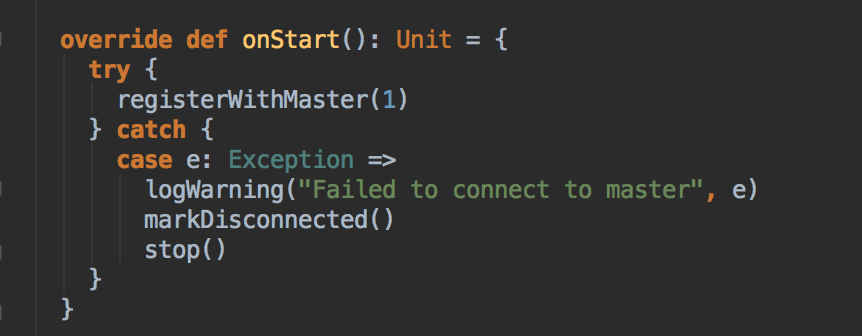
- 然后再调用 registerWithMaster 方法
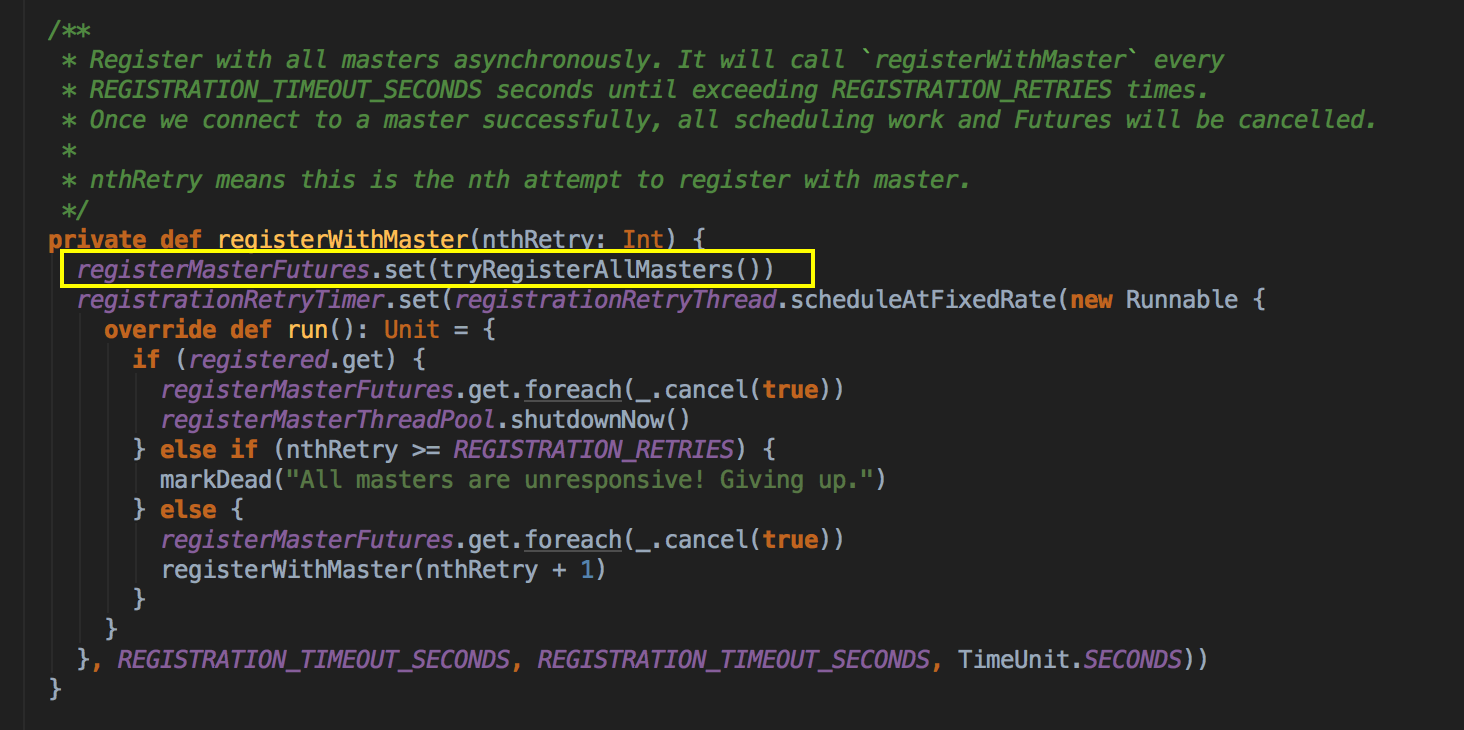
- 从 registerWithMaster 调用 tryRegisterAllMasters,开一条新的线程来注册,然后发送一条信息(RegisterApplication 的case class ) 给 Master,注册是通过 Thread 来完成的。
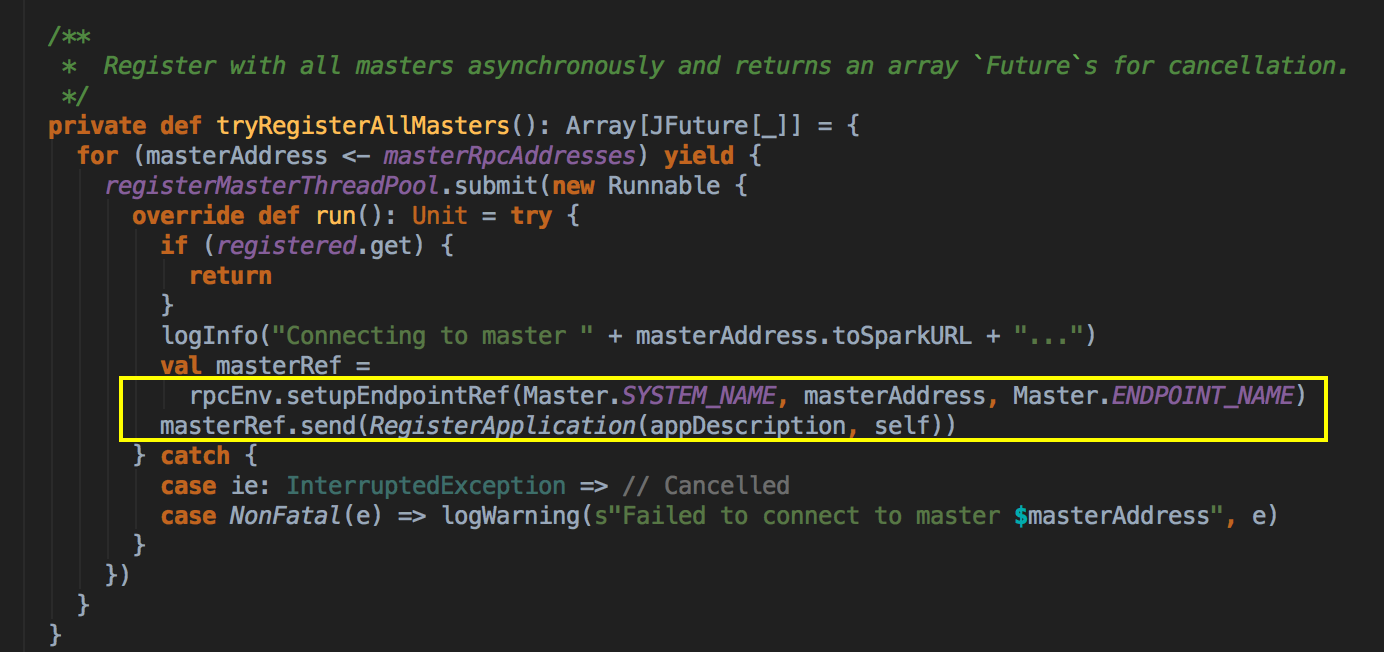

ApplicationDescription 的 case class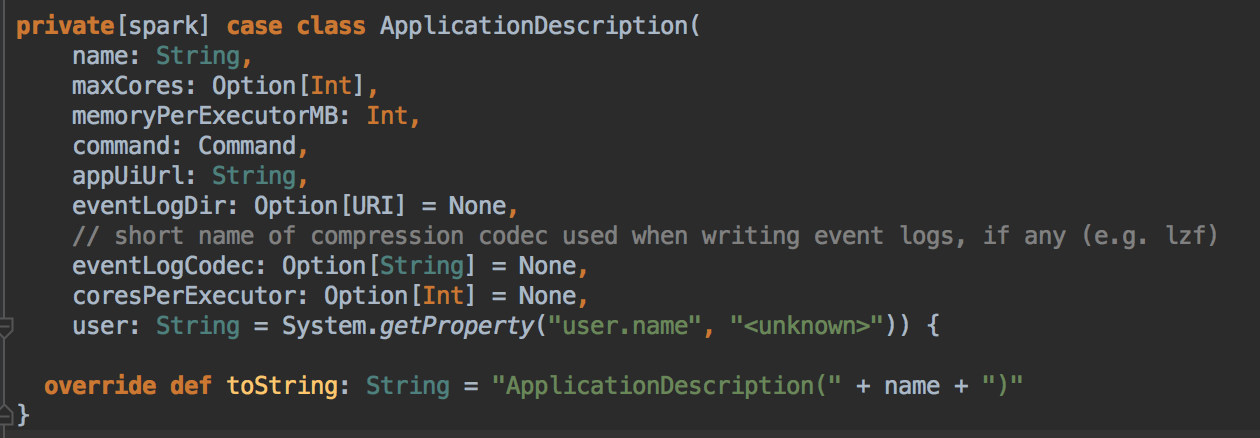
- Master 收到了这个信息便开始注册,注册后最后再次调用 schedule( ) 方法
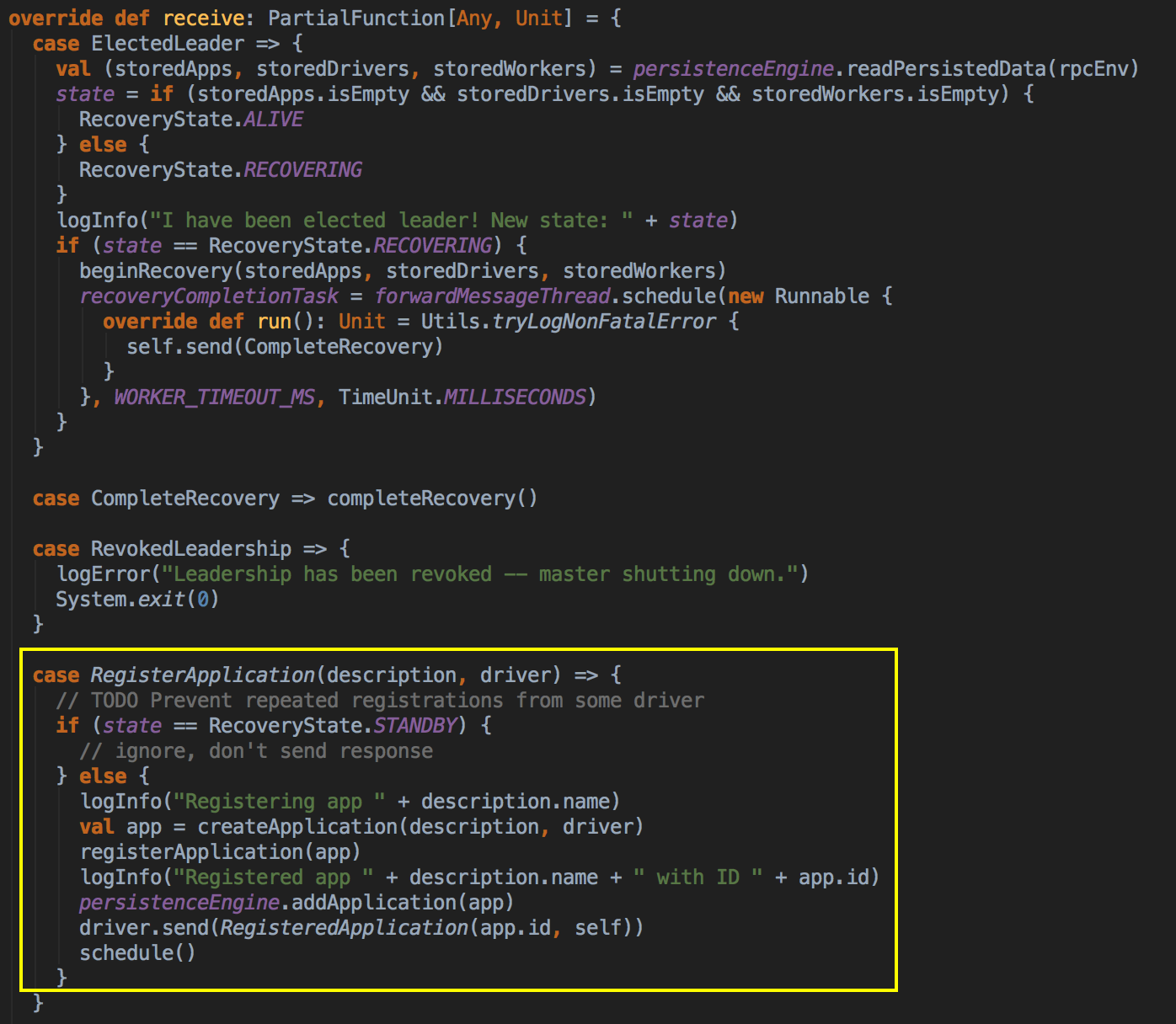
总结
SparkContext 开启了天堂之门:Spark 程序是通过 SparkContext 发布到 Spark集群的SparkContext 导演了天堂世界:Spark 程序运行都是在 SparkContext 为核心的调度器的指挥下进行的:SparkContext 关闭了天堂之门:SparkContext 崩溃或者结束的是偶整个 Spark 程序也结束啦!
程序提交整体流程如下图:
Spark天堂之门解密的更多相关文章
- [Spark内核] 第28课:Spark天堂之门解密
本課主題 什么是 Spark 的天堂之门 Spark 天堂之门到底在那里 Spark 天堂之门源码鉴赏 引言 我说的 Spark 天堂之门就是SparkContext,这篇文章会从 SparkCont ...
- Spark RDD解密
1. 基于数据集的处理: 从物理存储上加载数据,然后操作数据,然后写入数据到物理设备; 基于数据集的操作不适应的场景: 不适合于大量的迭代: 不适合交互式查询:每次查询都需要对磁盘进行交互. 基于数 ...
- 14.spark RDD解密
开篇:spark各种库,sparksql,sparkmachicelearning,等这么多库底层都是封装的RDD.意味着 1:RDD本身提供了通用的抽象, 2:spark现在有5个子框架,sql,S ...
- [Spark内核] 第33课:Spark Executor内幕彻底解密:Executor工作原理图、ExecutorBackend注册源码解密、Executor实例化内幕、Executor具体工作内幕
本課主題 Spark Executor 工作原理图 ExecutorBackend 注册源码鉴赏和 Executor 实例化内幕 Executor 具体是如何工作的 [引言部份:你希望读者看完这篇博客 ...
- [Spark内核] 第36课:TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本課主題 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本课主题 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- Spark Executor内幕彻底解密:Executor工作原理图、ExecutorBackend注册源码解密、Executor实例化内幕、Executor具体工作内幕
本课主题 Spark Executor 工作原理图 ExecutorBackend 注册源码鉴赏和 Executor 实例化内幕 Executor 具体是如何工作的 Spark Executor 工作 ...
- 王家林 大数据Spark超经典视频链接全集[转]
压缩过的大数据Spark蘑菇云行动前置课程视频百度云分享链接 链接:http://pan.baidu.com/s/1cFqjQu SCALA专辑 Scala深入浅出经典视频 链接:http://pan ...
- Spark 学习笔记大纲
Spark 内核 第28课:Spark天堂之门解密 (点击进入博客)从 SparkContext 创建3大核心对象开始到注册给 Master 这个过程中的源码鉴赏 第29课:Master HA彻底解密 ...
随机推荐
- java mybatis学习二
<select id="find1" parameterType="java.util.HashMap" resultType="com.xxx ...
- [转] 浏览器自动化测试初探:使用 phantomjs 与 casperjs
[From] https://www.qcloud.com/community/article/641602001489391648 作者:yangchunwen 首先要解释一下为什么叫浏览器自动化测 ...
- 爬虫之re块解析
一.re 这个去匹配比较麻烦,以后也比较少用,简单看一个案例就行 ''' 爬取数据流程: 1.指定url 2.发起请求 3.获取页面数据 4.数据解析 5.持久化存储 ''' import reque ...
- PIE SDK地图鼠标事件监听
1.功能简介 地图鼠标事件包含鼠标的按下MouseDown(),弹起MouseUp(),移动MouseMove()等事件,通过这些事件可以对地图进行动态的操作,接下来以地图状态栏的信息为例具体介绍如何 ...
- js插件编程-tab框
JS代码 (function (w) { //tab对象 function Tab(config) { //定义变量,防止变量污染 this.tabMenus=null; this.tabMains= ...
- Django From表单定制
参考文档: Forms The Forms API Working with forms 一.简单的Form表达定制 1)首先我们得定制Form表单类,下面我们创建一个简单的类: class Book ...
- Linux 上安装 weblogic12C (远程图形界面安装) (二)
上一篇Linux 上安装 weblogic12C (静默安装)介绍了静默方式安装weblogic12C的方式,这一篇主要介绍在windows主机上通过远程图形界面的方式安装weblogic的方式 一. ...
- 封装Lua for C#
http://blog.csdn.net/rcfalcon/article/details/5583095
- Oracle关于All和Any
简单的说 All等价于N个And语句,Any等价于N个or语句.
- linux下Oracle 相关命令
#注意:例子中的oralce命令在/home/oracle/oracle/product/10.2.0/db_1/bin目录.#你可以自己修改成自己的目录. A.#dbstart //启动数据库 #d ...