【python爬虫】对喜马拉雅上一个专辑的音频进行爬取并保存到本地
【一 爬虫目的】对喜马拉雅上一个专辑的音频进行爬取并保存到本地
要爬取的喜马拉雅音频数据如下所示:
每页30个音频,共x页。
【二 爬取过程】
》》》F12打开谷歌功能,点击Network选项:
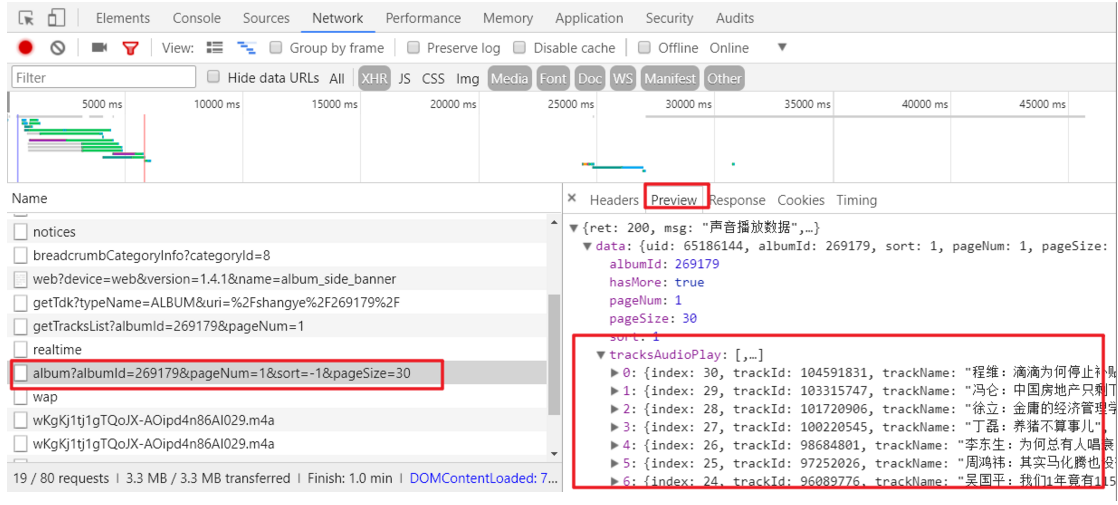
F5刷新后,随便点击一个音频进行播放(这里特别注意):

找到我们要爬取的页面数据的url地址:https://www.ximalaya.com/revision/play/album?albumId=269179&pageNum=1&sort=-1&pageSize=30

【三 代码实现】
#!/usr/bin/env python
# coding:utf-8
# Time:2018-8-14
# Author:ForYou import requests
import json
import re
# import lxml # 是“吴晓波频道”的前3页数据源代码:
"""
https://www.ximalaya.com/revision/play/album?albumId=269179&pageNum=1&sort=-1&pageSize=30
https://www.ximalaya.com/revision/play/album?albumId=269179&pageNum=2&sort=-1&pageSize=30
https://www.ximalaya.com/revision/play/album?albumId=269179&pageNum=3&sort=-1&pageSize=30
"""
class Xima(object):
# def __init__(self, book_name):
def __init__(self, book_name):
# 模拟浏览器
self.headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36"
}
# self.book_name = "复旦女神教师陈果的幸福哲学课"
self.book_name = book_name
# 这里肯定是存在问题的!
# self.start_url = "https://www.ximalaya.com/revision/play/album?albumId=269179&pageNum={}&sort=-1&pageSize=30"
self.start_url = "https://www.ximalaya.com/revision/play/album?albumId=269179&pageNum={}&sort=-1&pageSize=30"
# self.start_url = "https://www.ximalaya.com/revision/play/album?albumId=6419495&pageNum=1&sort=-1&pageSize=30"
self.book_url = []
for i in range(2): # 先爬取3页;
url =self.start_url.format(i + 1)
self.book_url.append(url)
print(self.book_url) def get_book_msg(self):
"""
从当前url获取到返回的数据,并且取到音频中的url和当前应音频的名字
:return:
"""
all_list = []
for url in self.book_url:
r = requests.get(url, headers=self.headers)
# r.content.decode()是请求当前url得到的俄数据,是一个json类型字符串
# python_dict是通过json.loads()把json类型字符串变为python的字典
pythpon_dict = json.loads(r.content.decode())
book_list = pythpon_dict["data"]["tracksAudioPlay"]
# m = 1 for i in book_list:
# print(("{}"+". "+i["trackName"]+" "+i["src"]).format(m))
# m += 1
list = {}
list["index"] = i["index"]
list["name"] = i["trackName"]
list["src"] = i["src"]
all_list.append(list)
return all_list
def save(self, all_list):
"""保存音频文件""" for i in all_list:
# i实际上就是我们每一个音频的名字和url
# with open(r"D:\喜马拉雅音频下载\{}.m4a".format(self.book_name + i["index"]+". "+i["name"],'ab') ) as f:
# with open(r"D:\喜马拉雅全集音频下载\{}.m4a".format(self.book_name + "{}".format(i["index"])+'. '+i["name"]), 'ab') as f:
# 特别注意:******
re.sub('"|\|:|', '', i['name']) # 这个在爬虫时很重要!******
with open(r"D:\xima\{}.m4a".format(self.book_name + ' '+ str(i["index"])+i["name"]),'ab') as f:
r = requests.get(i["src"], headers=self.headers)
# 通过请求音频的url得到音频的二进制数据,然后把二进制数据保存到本地
print("正在保存第{}条信息".format(i["index"])) # 这句有问题!
f.write(r.content) def run(self):
all_list = self.get_book_msg()
self.save(all_list) if __name__== '__main__':
xima = Xima('吴晓波频道')
# xima = Xima(id, name) # ??
xima.get_book_msg()
xima.run()
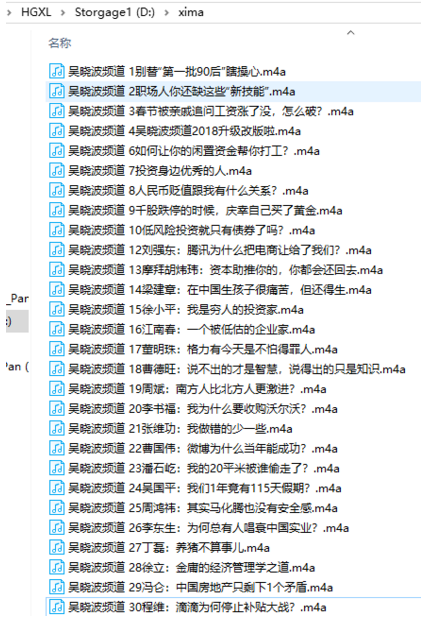
【四 爬取结果】
音频数据已经保存到本地:

The end!
【python爬虫】对喜马拉雅上一个专辑的音频进行爬取并保存到本地的更多相关文章
- Python爬虫入门教程第七讲: 蜂鸟网图片爬取之二
蜂鸟网图片--简介 今天玩点新鲜的,使用一个新库 aiohttp ,利用它提高咱爬虫的爬取速度. 安装模块常规套路 pip install aiohttp 运行之后等待,安装完毕,想要深造,那么官方文 ...
- Python爬虫入门教程 15-100 石家庄政民互动数据爬取
石家庄政民互动数据爬取-写在前面 今天,咱抓取一个网站,这个网站呢,涉及的内容就是 网友留言和回复,特别简单,但是网站是gov的.网址为 http://www.sjz.gov.cn/col/14900 ...
- Python爬虫实践~BeautifulSoup+urllib+Flask实现静态网页的爬取
爬取的网站类型: 论坛类网站类型 涉及主要的第三方模块: BeautifulSoup:解析.遍历页面 urllib:处理URL请求 Flask:简易的WEB框架 介绍: 本次主要使用urllib获取网 ...
- Python学习笔记之爬取网页保存到本地文件
爬虫的操作步骤: 爬虫三步走 爬虫第一步:使用requests获得数据: (request库需要提前安装,通过pip方式,参考之前的博文) 1.导入requests 2.使用requests.get ...
- Java分布式爬虫Nutch教程——导入Nutch工程,执行完整爬取
Java分布式爬虫Nutch教程--导入Nutch工程,执行完整爬取 by briefcopy · Published 2016年4月25日 · Updated 2016年12月11日 在使用本教程之 ...
- Python爬虫:新浪新闻详情页的数据抓取(函数版)
上一篇文章<Python爬虫:抓取新浪新闻数据>详细解说了如何抓取新浪新闻详情页的相关数据,但代码的构建不利于后续扩展,每次抓取新的详情页时都需要重新写一遍,因此,我们需要将其整理成函数, ...
- Python 网络爬虫 006 (编程) 解决下载(或叫:爬取)到的网页乱码问题
解决下载(或叫:爬取)到的网页乱码问题 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 Python 的集成开发环境:PyCharm 20 ...
- Python爬虫入门教程 19-100 51CTO学院IT技术课程抓取
写在前面 从今天开始的几篇文章,我将就国内目前比较主流的一些在线学习平台数据进行抓取,如果时间充足的情况下,会对他们进行一些简单的分析,好了,平台大概有51CTO学院,CSDN学院,网易云课堂,慕课网 ...
- Python爬虫入门教程 18-100 煎蛋网XXOO图片抓取
写在前面 很高兴我这系列的文章写道第18篇了,今天写一个爬虫爱好者特别喜欢的网站煎蛋网http://jandan.net/ooxx,这个网站其实还是有点意思的,网站很多人写了N多的教程了,各种方式的都 ...
随机推荐
- ETO的公开赛T1《矿脉开采》题解(正解)(by Zenurik)
作为T1,当然是越水越好啦qwq 显然经目测可得,那个所谓的质量评级根本就没卵用,可以直接\(W_i = W_i^{V_i}\)累积到利润里面. 这样,本问题显然是一个"子集和"问 ...
- windows10安装mysql8.0.11(免安装版)
1.MySQL8.0.11下载网址:https://dev.mysql.com/downloads/mysql/ 2.配置环境变量:我的电脑->属性->高级系统设置->环境变量-&g ...
- VULTR的VPS在centos的操作系统中出现网站无法访问 80端口被firewall禁止
导语:叶子在为一位客户配置web服务器环境的时候,出现网站不能访问的情况,但ping正常.客户的服务器是在VULTR上购买的VPS,安装的操作系统为centos 7.3.经过叶子的分析,认为是防火墙阻 ...
- CSS3--j惊艳到你的新前端
一.css3的选择器 1. 父子选择器 直接关系 .box>.com 2. 兄弟选择器 相邻关系 .box+.com <span>hello</span> <p&g ...
- YII2.O学习三 前后台用户数据表分离
之前我们完成了Advanced 模板安装,也完成了安装adminlte 后台模板,这一步是针对前端和后台用户使用不同的数据库表来管理,做到前后台用户分离的效果: 复制一张user数据表并重命名为adm ...
- Laravel -- Blade模板
{{--流程控制--}} @if($name == '1') this is 1 @elseif($name == '2') this.is 2 @else who am i? @endif @for ...
- Windows10 快捷键
windows 10快捷键: F1 打开帮助 F2 重命名 F3 打开搜索文件和文件夹 F4 打开地址栏常用的地址 F5 刷新 F11 全屏 选择文件和内容: shift + 上下左右键选择连续的 ...
- CS61B sp2018笔记 | Lists
Lists csdn同作者原创地址 1. IntLists 下面我们来一步一步的实现List类,首先你可以实现一个最简单的版本: public class IntList { public int ...
- Java技术——I/O知识学习
个字节,主要用在处理二进制数据,字节用来与文件打交道,所有文件的储存都是通过字节(byte)的方式,在磁盘上保留的并不是文件的字符而是先把字符编码成字节,再储存这些字节到磁盘.在读取文件(特别是文本文 ...
- java二分法来求一个数组中一个值的key
package TestArray; import java.util.Arrays; /** * 二分法查找 */ public class Test { public static void ma ...