【python爬虫】对喜马拉雅上一个专辑的音频进行爬取并保存到本地
【一 爬虫目的】对喜马拉雅上一个专辑的音频进行爬取并保存到本地
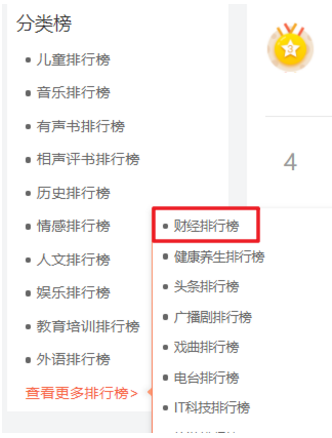
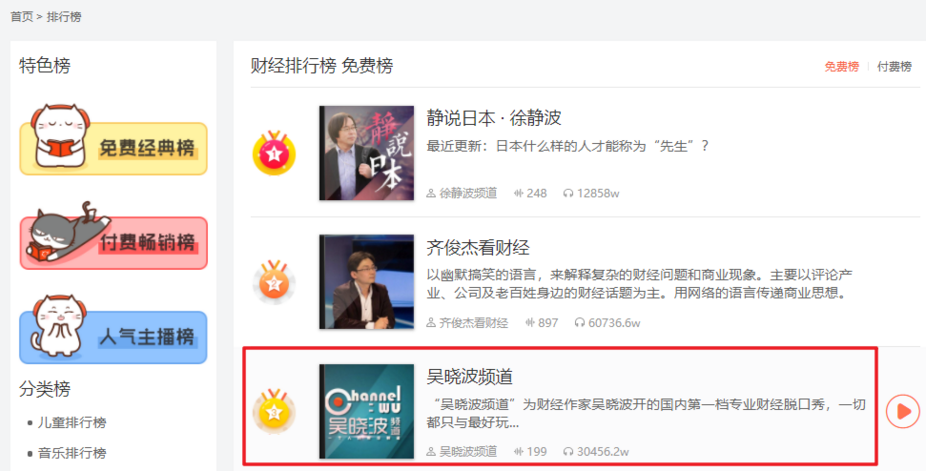
要爬取的喜马拉雅音频数据如下所示:
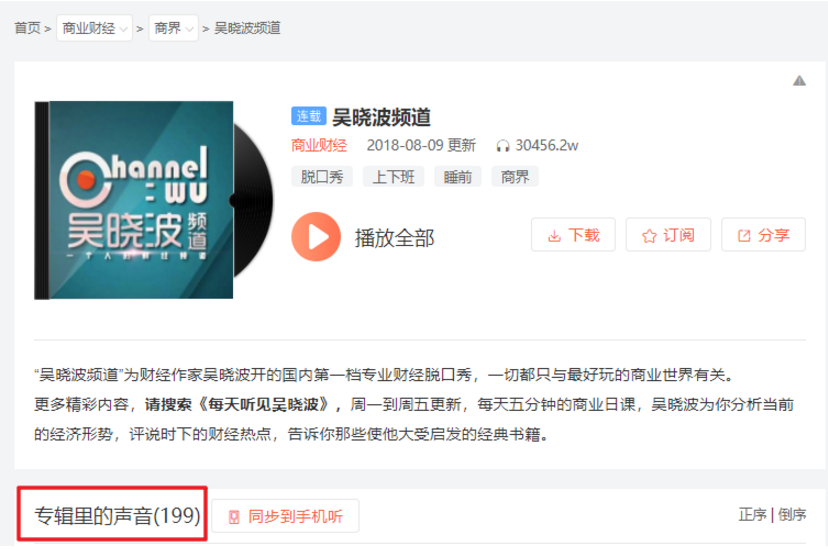
每页30个音频,共x页。
【二 爬取过程】
》》》F12打开谷歌功能,点击Network选项:
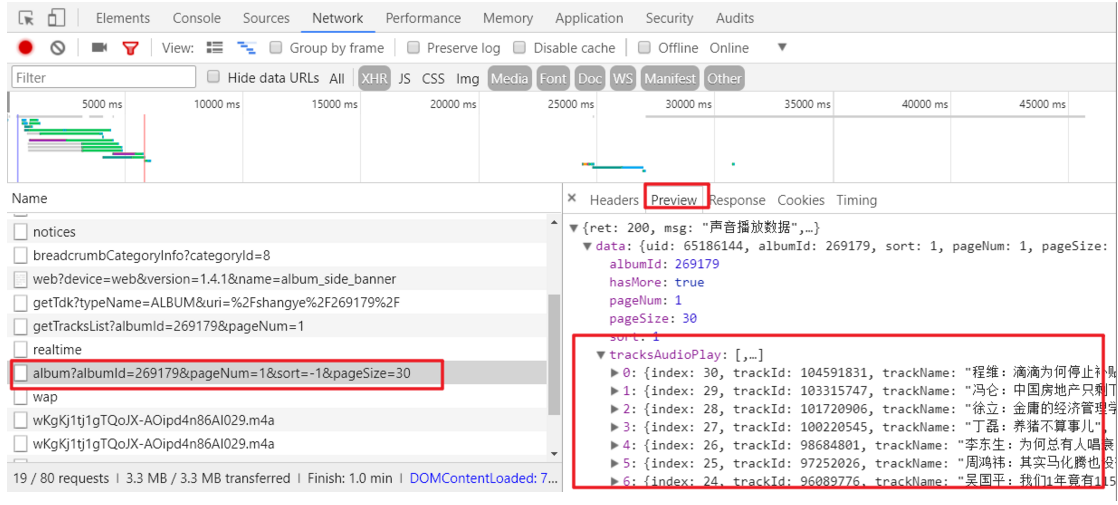
F5刷新后,随便点击一个音频进行播放(这里特别注意):

找到我们要爬取的页面数据的url地址:https://www.ximalaya.com/revision/play/album?albumId=269179&pageNum=1&sort=-1&pageSize=30

【三 代码实现】
#!/usr/bin/env python
# coding:utf-8
# Time:2018-8-14
# Author:ForYou import requests
import json
import re
# import lxml # 是“吴晓波频道”的前3页数据源代码:
"""
https://www.ximalaya.com/revision/play/album?albumId=269179&pageNum=1&sort=-1&pageSize=30
https://www.ximalaya.com/revision/play/album?albumId=269179&pageNum=2&sort=-1&pageSize=30
https://www.ximalaya.com/revision/play/album?albumId=269179&pageNum=3&sort=-1&pageSize=30
"""
class Xima(object):
# def __init__(self, book_name):
def __init__(self, book_name):
# 模拟浏览器
self.headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36"
}
# self.book_name = "复旦女神教师陈果的幸福哲学课"
self.book_name = book_name
# 这里肯定是存在问题的!
# self.start_url = "https://www.ximalaya.com/revision/play/album?albumId=269179&pageNum={}&sort=-1&pageSize=30"
self.start_url = "https://www.ximalaya.com/revision/play/album?albumId=269179&pageNum={}&sort=-1&pageSize=30"
# self.start_url = "https://www.ximalaya.com/revision/play/album?albumId=6419495&pageNum=1&sort=-1&pageSize=30"
self.book_url = []
for i in range(2): # 先爬取3页;
url =self.start_url.format(i + 1)
self.book_url.append(url)
print(self.book_url) def get_book_msg(self):
"""
从当前url获取到返回的数据,并且取到音频中的url和当前应音频的名字
:return:
"""
all_list = []
for url in self.book_url:
r = requests.get(url, headers=self.headers)
# r.content.decode()是请求当前url得到的俄数据,是一个json类型字符串
# python_dict是通过json.loads()把json类型字符串变为python的字典
pythpon_dict = json.loads(r.content.decode())
book_list = pythpon_dict["data"]["tracksAudioPlay"]
# m = 1 for i in book_list:
# print(("{}"+". "+i["trackName"]+" "+i["src"]).format(m))
# m += 1
list = {}
list["index"] = i["index"]
list["name"] = i["trackName"]
list["src"] = i["src"]
all_list.append(list)
return all_list
def save(self, all_list):
"""保存音频文件""" for i in all_list:
# i实际上就是我们每一个音频的名字和url
# with open(r"D:\喜马拉雅音频下载\{}.m4a".format(self.book_name + i["index"]+". "+i["name"],'ab') ) as f:
# with open(r"D:\喜马拉雅全集音频下载\{}.m4a".format(self.book_name + "{}".format(i["index"])+'. '+i["name"]), 'ab') as f:
# 特别注意:******
re.sub('"|\|:|', '', i['name']) # 这个在爬虫时很重要!******
with open(r"D:\xima\{}.m4a".format(self.book_name + ' '+ str(i["index"])+i["name"]),'ab') as f:
r = requests.get(i["src"], headers=self.headers)
# 通过请求音频的url得到音频的二进制数据,然后把二进制数据保存到本地
print("正在保存第{}条信息".format(i["index"])) # 这句有问题!
f.write(r.content) def run(self):
all_list = self.get_book_msg()
self.save(all_list) if __name__== '__main__':
xima = Xima('吴晓波频道')
# xima = Xima(id, name) # ??
xima.get_book_msg()
xima.run()
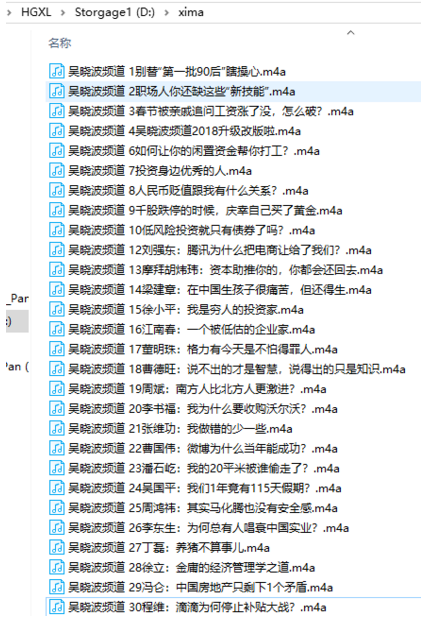
【四 爬取结果】
音频数据已经保存到本地:

The end!
【python爬虫】对喜马拉雅上一个专辑的音频进行爬取并保存到本地的更多相关文章
- Python爬虫入门教程第七讲: 蜂鸟网图片爬取之二
蜂鸟网图片--简介 今天玩点新鲜的,使用一个新库 aiohttp ,利用它提高咱爬虫的爬取速度. 安装模块常规套路 pip install aiohttp 运行之后等待,安装完毕,想要深造,那么官方文 ...
- Python爬虫入门教程 15-100 石家庄政民互动数据爬取
石家庄政民互动数据爬取-写在前面 今天,咱抓取一个网站,这个网站呢,涉及的内容就是 网友留言和回复,特别简单,但是网站是gov的.网址为 http://www.sjz.gov.cn/col/14900 ...
- Python爬虫实践~BeautifulSoup+urllib+Flask实现静态网页的爬取
爬取的网站类型: 论坛类网站类型 涉及主要的第三方模块: BeautifulSoup:解析.遍历页面 urllib:处理URL请求 Flask:简易的WEB框架 介绍: 本次主要使用urllib获取网 ...
- Python学习笔记之爬取网页保存到本地文件
爬虫的操作步骤: 爬虫三步走 爬虫第一步:使用requests获得数据: (request库需要提前安装,通过pip方式,参考之前的博文) 1.导入requests 2.使用requests.get ...
- Java分布式爬虫Nutch教程——导入Nutch工程,执行完整爬取
Java分布式爬虫Nutch教程--导入Nutch工程,执行完整爬取 by briefcopy · Published 2016年4月25日 · Updated 2016年12月11日 在使用本教程之 ...
- Python爬虫:新浪新闻详情页的数据抓取(函数版)
上一篇文章<Python爬虫:抓取新浪新闻数据>详细解说了如何抓取新浪新闻详情页的相关数据,但代码的构建不利于后续扩展,每次抓取新的详情页时都需要重新写一遍,因此,我们需要将其整理成函数, ...
- Python 网络爬虫 006 (编程) 解决下载(或叫:爬取)到的网页乱码问题
解决下载(或叫:爬取)到的网页乱码问题 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 Python 的集成开发环境:PyCharm 20 ...
- Python爬虫入门教程 19-100 51CTO学院IT技术课程抓取
写在前面 从今天开始的几篇文章,我将就国内目前比较主流的一些在线学习平台数据进行抓取,如果时间充足的情况下,会对他们进行一些简单的分析,好了,平台大概有51CTO学院,CSDN学院,网易云课堂,慕课网 ...
- Python爬虫入门教程 18-100 煎蛋网XXOO图片抓取
写在前面 很高兴我这系列的文章写道第18篇了,今天写一个爬虫爱好者特别喜欢的网站煎蛋网http://jandan.net/ooxx,这个网站其实还是有点意思的,网站很多人写了N多的教程了,各种方式的都 ...
随机推荐
- rest_framework -- mixins&generics
上面的mixins.generics都是rest_framework里的模块,我们可以继承其中的某些类,达到代码量减少的效果,这里充分体现出了面向对象的继承 一.mixins模块 mixins : f ...
- django-orm简记
首先orm是什么? orm-------->对象关系映射 专业性解释网上一大推,随便搜搜就能了解大概.在我理解(通俗):一个类 ----- 数据库中一张表 类属性 ----- 数据表中的字段名 ...
- [ZJOI2006]超级麻将(动规)
题目描述 很多人都知道玩麻将,当然也有人不知道,呵呵,不要紧,我在这里简要地介绍一下麻将规则: 普通麻将有砣.索.万三种类型的牌,每种牌有1~9个数字,其中相同的牌每个有四张,例如1砣~9砣,1索~9 ...
- 树莓派官方推荐的VNC Viewer配置详解Raspberry Pi3 B+
1GB内存,16GB硬盘容量.这是我目前使用的Pi3树莓派. SVN Viewer远程连接,台式机192.168.1.102连接局域网192.168.1.110上的树莓派.使用的软件是: https: ...
- 富文本编辑器 summernote.js
1.引用js 可在 https://summernote.org/ 官网下载 ,并查看详细的API 引入:summernote.js 和 summernote-zh-CN.js 以及样式文件:su ...
- 中间件kafka
* kafka----一个发布订阅消息系统,中间件:一个分布式.分区.可重复的日志服务kafka需要了解基础几层结构,生产者订阅者等使用方法,和在高并发.一致性场景使用.(凡事面试问一致性.高并发都脱 ...
- Spring常见面试题
本文是通过收集网上各种面试指南题目及答案然后经过整理归纳而来,仅仅是为了方便以后回顾,无意冒犯各位原创作者. Spring框架 1. 什么是Spring? Spring 是个java企业级应用的开源开 ...
- Flask初见
Flask是一个使用 Python 编写的轻量级 Web 应用框架.其 WSIG工具箱采用 Werkzeug ,模板引擎则使用 Jinja2 .Flask使用 BSD 授权. Flask也被称为 “m ...
- asp.net core mvc简介
MVC 通常而言,我们使用.NET Core MVC 构建网页应用与 API,MVC是使用模型-视图-控制器(Model-View-Controller)设计模式. 创建项目 使用如下命令创建一个名称 ...
- pxe无人值守安装linux机器笔记----摘抄
1. 基建工作 1.关闭防火墙 a)service iptables stop b)service ip6tables stop c)chkconfig iptables off d)chkconfi ...