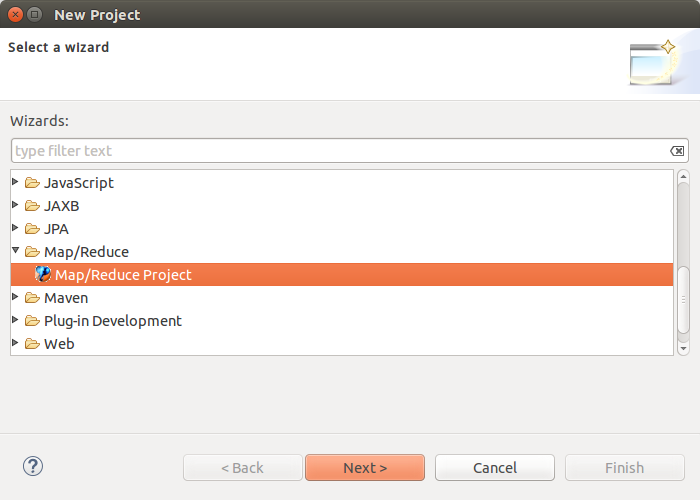
hadoop2.6.0的eclipse插件安装
1.安装插件
下载插件hadoop-eclipse-plugin-2.6.0.jar并将其放到eclips安装目录->plugins(插件)文件夹下。然后启动eclipse。
配置 hadoop 安装目录

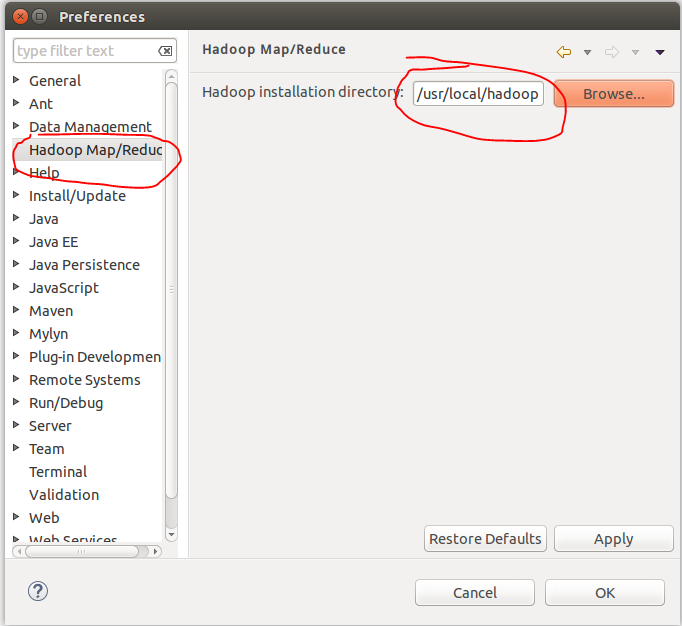
配置Map/Reduce 视图

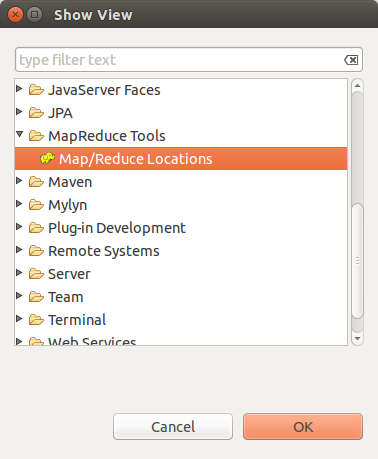

- 点击"大象"
- 在“Map/Reduce Locations” Tab页 点击图标“大象”,选择“New Hadoop location…”,弹出对话框“New hadoop location…”。填写Location name和右边的Port:9000(与配置文件core-site.xml中的保持一致)。

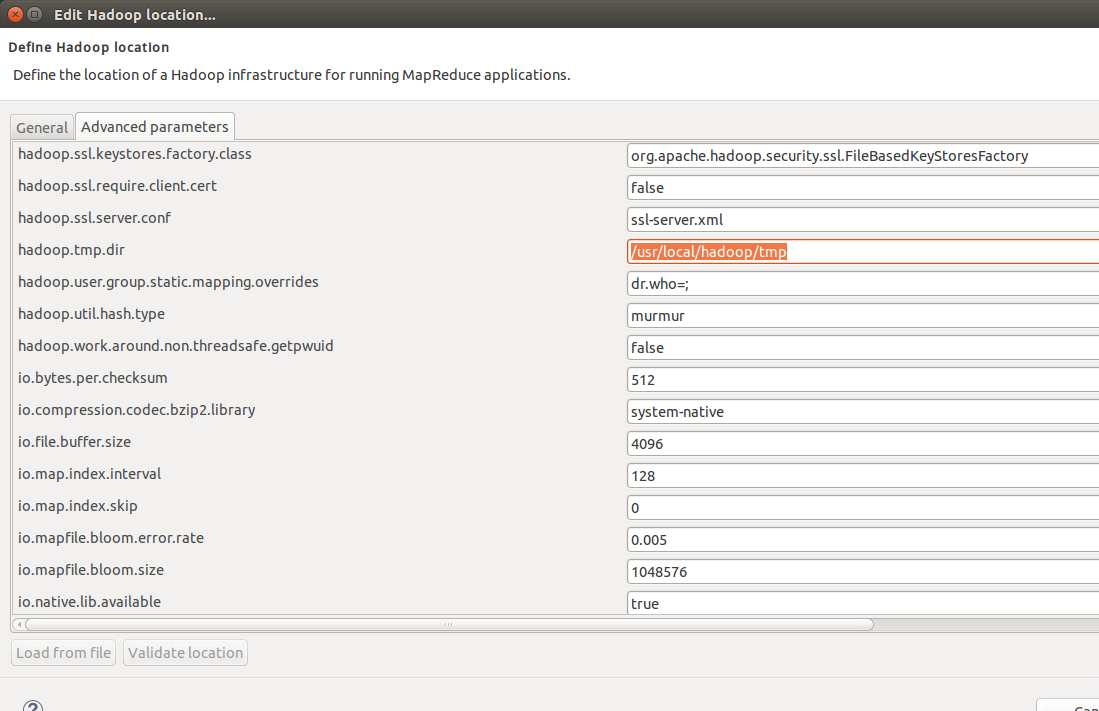
- 在Advanced paramenters中如下图所示找到hadoop.tmp.dir选项,与配置文件core-site.xml保持一致。
以及dfs.namenode.name.dir和dfs.datanode.data.dir与配置文件hdfs-site.xml保持一致
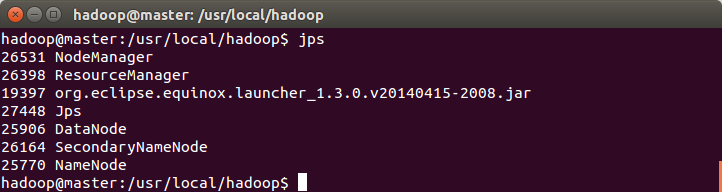
启动hadoop: sbin/start-all.sh 然后执行 jps。多一个org.eclipse.equinox.launcher...
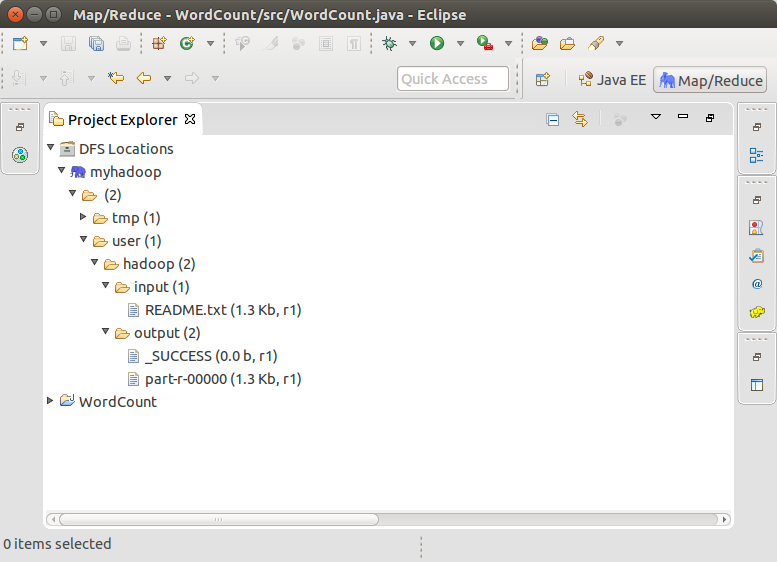
- 打开Project Explorer,查看HDFS文件系统。这是前篇文章中配置hadoop中的运行的结果。传送门
2.运行WordCount的例子
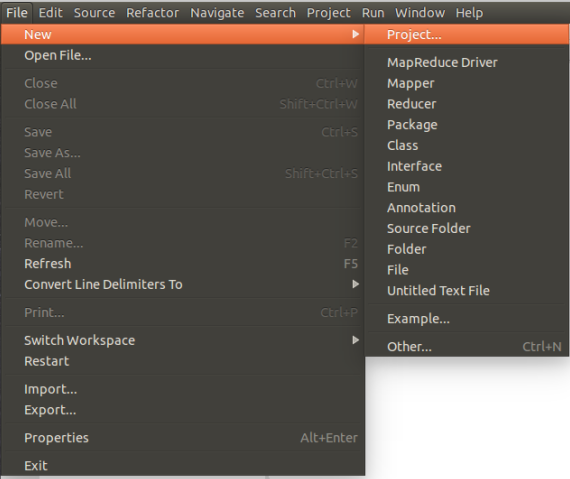
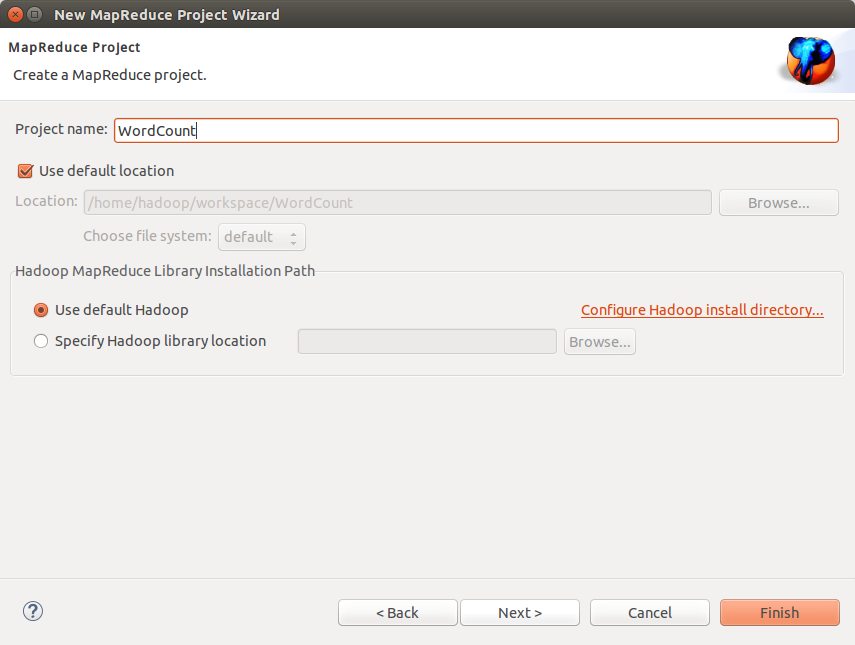
- 新建Map/Reduce任务
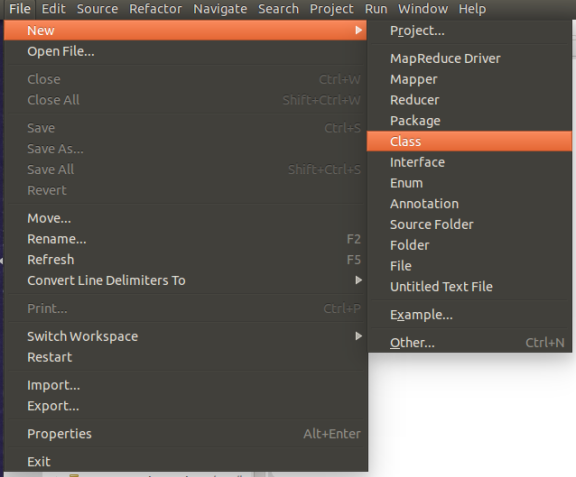
- 编写WordCount
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class WordCount {
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount"); conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(Map.class);
conf.setReducerClass(Reduce.class); conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf);
}
}
- 添加log4j.properties文件,很重要。

内容:
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
结果如下

- 空白处右键,配置运行时参数

output写成hdfs://localhost:9000/user/hadoop/output 或者其他名,下面并没有写错。
注意:output文件夹在HDFS文件系统每次运行前必须重新删除,否则出错。或者写成其他名字亦可。
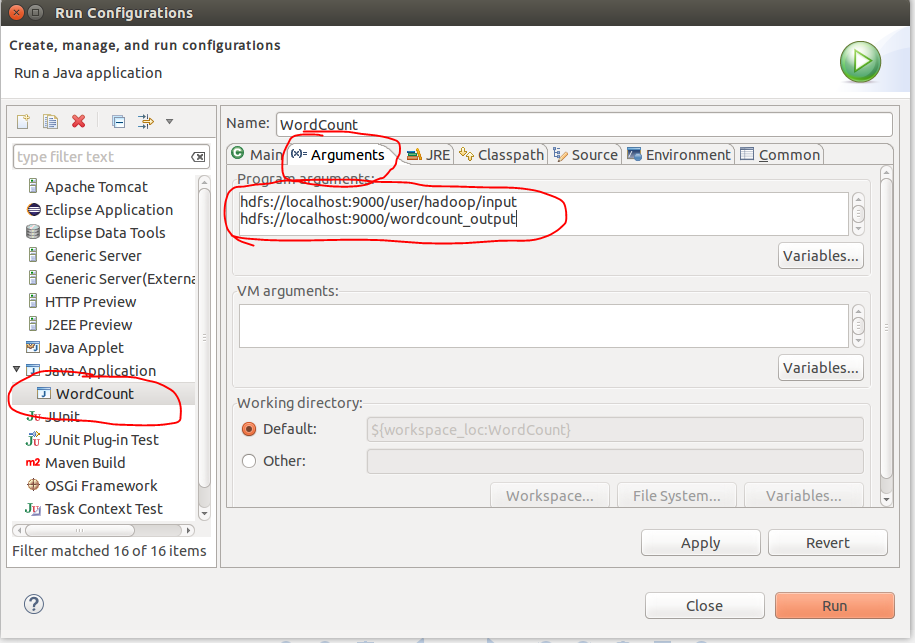
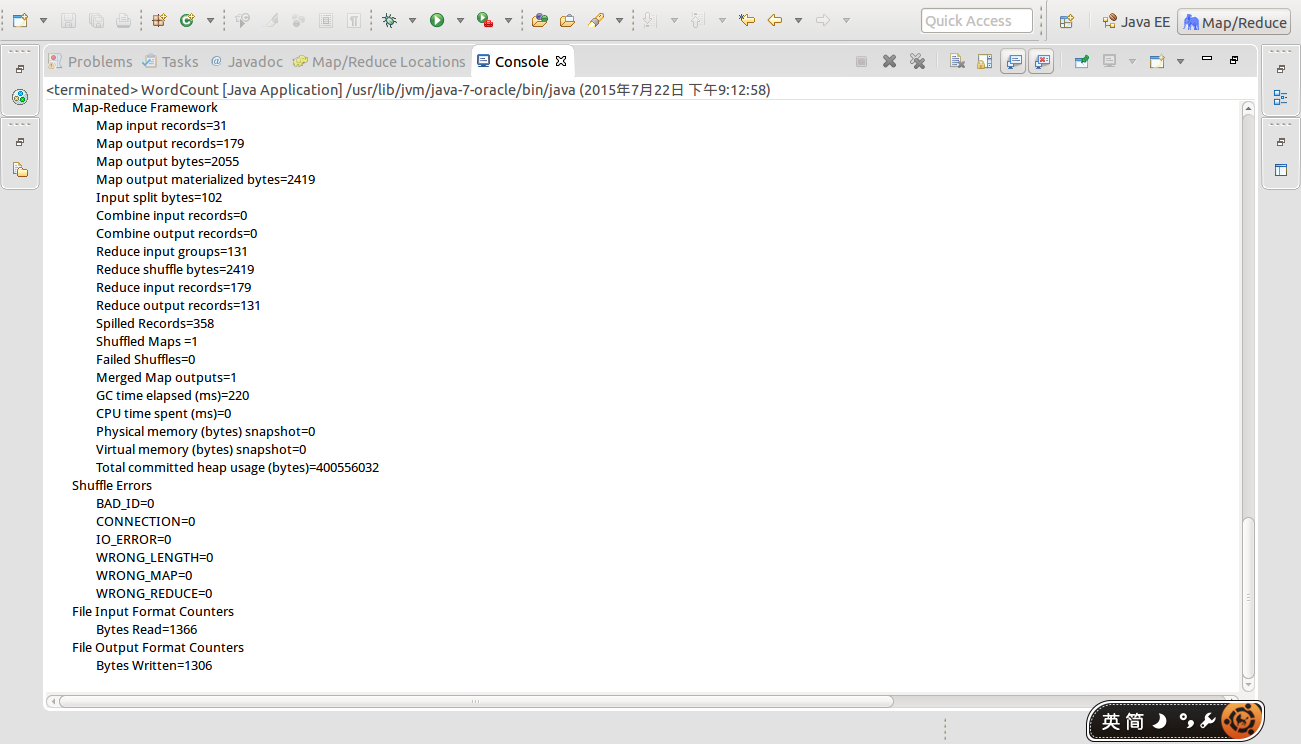
最后点Run运行。控制台输出
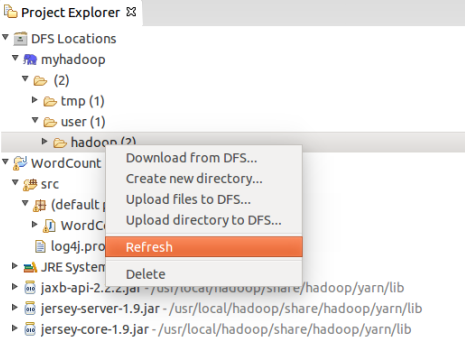
- Project Explorer反应并不及时,点击F5刷新或者:
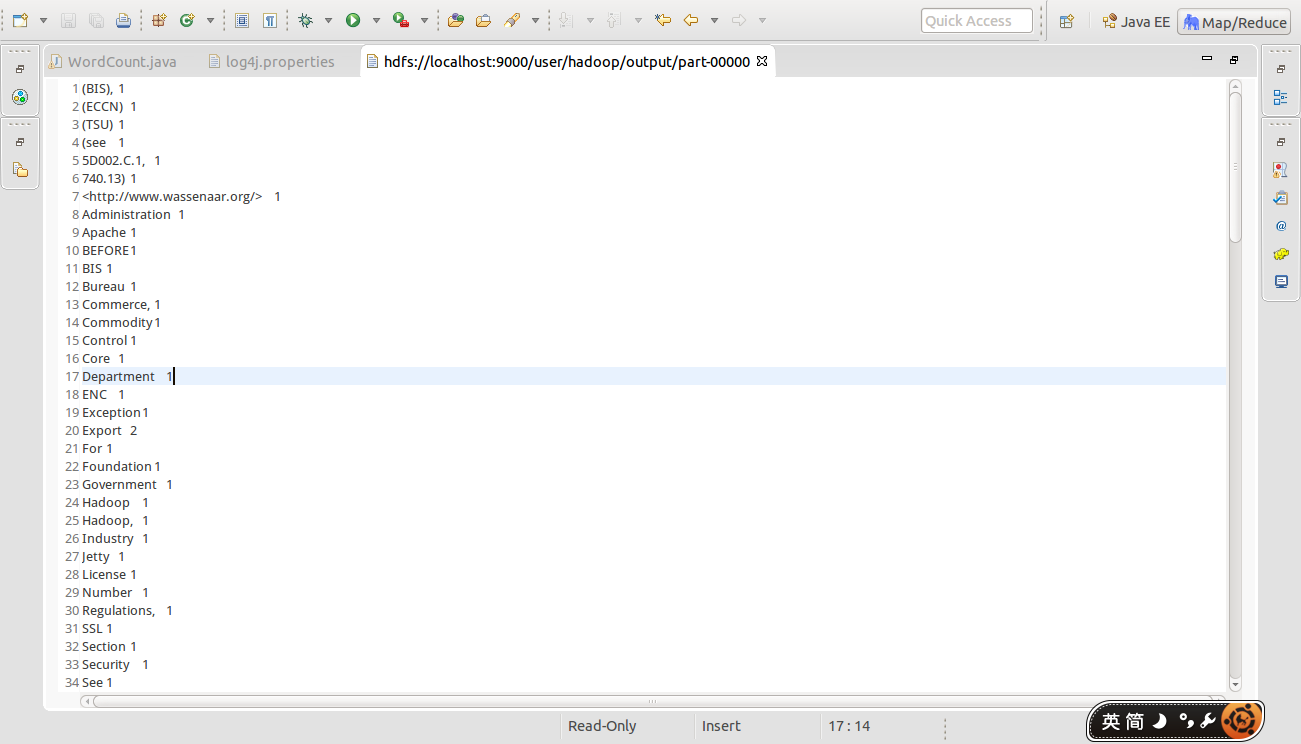
- 最后查看结果,结果放在output文件夹中(与Run Configurations中配置的地址一致)

hadoop2.6.0的eclipse插件安装的更多相关文章
- hadoop2.6.0的eclipse插件编译和设置
编译hadoop2.6.0的eclipse插件 下载源码: git clone https://github.com/winghc/hadoop2x-eclipse-plugin.git 编译源码: ...
- Hadoop-2.3.0的Eclipse插件编译
Hadoop-2.3.0的Eclipse插件编译 #cd /usr/local/src/hadoop2x-eclipse-plugin-master/src/contrib/eclipse-plugi ...
- Activiti BPMN 2.0 designer eclipse插件安装
官方网是这样说的: https://www.activiti.org/userguide/index.html#springSpringBoot The following installation ...
- 在fedora20下配置hadoop2.5.1的eclipse插件
(博客园-番茄酱原创) 在我的系统中,hadoop-2.5.1的安装路径是/opt/lib64/hadoop-2.5.1下面,然后hadoop-2.2.0的路径是/home/hadoop/下载/had ...
- Android模拟神器Genymotion eclipse插件安装问题出解决
我之前一直是打开eclipse之前直接运行Genymotion模拟器就可以连接到adb了,非常方便,但最近突然想来装个eclipse的Genymotion插件玩玩,安装时居然出错了,于是不折腾好心里不 ...
- jBPM 6 开发 eclipse 插件安装
jBPM 6 开发 eclipse 插件安装 概述 与之前的jBPM 5相比,jBPM 6 新引入的kjars及mavenized的特性,使流程开发设计与之前有了很大的不同,本文主要说明jBPM 6 ...
- 常用的4个eclipse插件安装过程及使用方法
最近整合了4个常用eclipse插件安装过程,分别是PMD.checkstyle.findbugs.sourcemonitor插件.因为我这里没有外网,所以所有的插件不是最新版,建议有网的童鞋自行在外 ...
- (转载)eclipse插件安装的四种方法
eclipse插件安装的四种方法 Eclipse插件的安装方法 1.在eclipse的主目录(ECLIPSE_HOME, 比如在我的机器上安装的目录是:D:\eclipse)有一个plugins的目录 ...
- CentOS7-64bit 编译 Hadoop-2.5.0,并分布式安装
摘要 CentOS7-64bit 编译 Hadoop-2.5.0,并分布式安装 目录[-] 1.系统环境说明 2.安装前的准备工作 2.1 关闭防火墙 2.2 检查ssh安装情况,如果没有则安装ssh ...
随机推荐
- Spark的Driver节点和Executor节点
转载自:http://blog.sina.com.cn/s/blog_15fc03d810102wto0.html 1.驱动器节点(Driver) Spark的驱动器是执行开发程序中的 main方法的 ...
- redis_cluster部署过程
Redis集群1.多个redis节点网络互联,数据共享2.所有的节点都是一主一从(可以是多个从),其中从不提供服务3.不支持同时处理多个键(如mset/mget),因为redis需要把键均匀分布在各个 ...
- JMS术语
Provider(MessageProvider):生产者Consumer(MessageConsumer):消费者PTP:Point to Point,即点对点的消息模型Pub/Sub:Publis ...
- PHP实现创建一个文件
方法一:file_put_content($filename,$content); function mk_document($filename,$content=''){ // var_dump(_ ...
- 使用Xib创建自定义视图(不是cell)时需要注意的问题
开发项目过程中,有些地方不免会用到Xib来提高开发效率,如果你的手速够快,写代码建视图,我并不反对这样做.因为我以前也是纯手写代码开发. 进入正题,Xib好用,但是这些下面这些问题需要注意一下. 问题 ...
- Java HashMap详细介绍和使用示例
①对HashMap的整体认识 HashMap是一个散列表,它存储的内容是键值对(key-value)映射. HashMap继承于AbstractMap,实现了Map.Cloneable.java.io ...
- C++ vector 用法
转自http://www.cnblogs.com/wang7/archive/2012/04/27/2474138.html#undefined 在c++中,vector是一个十分有用的容器,下面对这 ...
- suse linux 常用命令
功能:rm 命令,删除一个目录中的一个或多个文件或目录(文件夹). 它也可以将某个目录及其下的所有文件及子目录均删除. 对于链接文件,只是删除了链接,原有文件均保持不变. 文件一旦被删除,它不能被恢复 ...
- GZFramework错误(升级修改)日志
sqlserver下事务中处理出现为初始化selectcommand的connection属性修改CommandDataBase中的PrepareCommand方法
- 用C#连接SFTP服务器并进行上传下载文件
1.使用软件连接可采用WinSCP进行: 文件协议选择SFTP,端口号默认22 2.使用C#代码操作 参考:http://www.cnblogs.com/binw/p/4065642.html 主要引 ...