论文解读(FedGAT)《Federated Graph Attention Network for Rumor Detection》
论文信息
论文标题:Federated Graph Attention Network for Rumor Detection
论文作者:Huidong Wang, Chuanzheng Bai, Jinli Yao
论文来源:2022, arXiv
论文地址:download
论文代码:download
1 Introduction
现有的谣言检测模型都是为单一的社交平台构建的,这忽略了跨平台谣言的价值。本文将联邦学习范式与双向图注意网络谣言检测模型相结合,提出了用于谣言检测的联邦图注意网络(FedGAT)模型。
对于数据安全和隐私保护,不同组织之间的数据通常不能互操作,而且它们不能很容易地聚合和处理,这种无法共享数据的情况被称为 isolated data island problem。
2 Preliminaries
2.1 Problem statement and notation
许多社交网络很难合作解决谣言传播的问题,传统的谣言检测是在单一的社交网络平台进行,通常只是获得某个组织的用户数据,然后建立一个模型来确定一个时间是否发布了虚假的谣言帖子。本文构建的谣言检测模型主要针对不同社交平台之间谣言数据的互操作性,建立了跨平台数据聚合的模型,以提高社交网络中虚假谣言事件的检测效率。
Table 1 总结了本文中使用的一些符号的定义,并将需要处理的谣言检测问题描述如下。
假设有 $k$ 个平台,他们对应的谣言数据集是 $\left\{D_{i}\right\}_{i=1, \ldots, k}^{m}$,其中 ,$D_{i}$ 代表第 $i$ 个平台的谣言数据集。假设 第 $i$ 个平台拥有 $m$ 个 post event,它可以表示为 $\left\{C_{1}, C_{2}, \ldots, C_{m}\right\}$ 。谣言检测的目的是对事件来源帖子的内容是否可靠进行分类,即根据现有知识判断是否为虚假谣言。
2.2 Graph Attention Network
注意力系数计算:
${\Large \alpha_{i j}=\frac{\exp \left(\text { LeakyReLU }\left(a^{T}\left[W \cdot h_{i} \| W \cdot h_{j}\right]\right)\right)}{\sum_{j \in N_{i} \cup i} \exp \left(\operatorname{LeakyReLU}\left(a^{T}\left[W \cdot h_{i} \| W \cdot h_{j}\right]\right)\right)}} \quad\quad\quad(1)$
多头注意力:
${\Large h_{i}^{\prime}=\|_{h e a d=1}^{H e a d s} \sigma\left(\sum\limits_{j \in i \cup i} \alpha_{i j}^{h e a d} W^{h e a d} h_{j}\right)} $
2.3 Federated Learning
联邦学习旨在建立一个基于分布式数据集的联邦学习模型。它通常包括两个过程:模型训练,和模型推理。在模型训练中,各方之间可以进行与模型相关的信息交换。联邦学习是一种算法框架,用于构建具有以下特征的机器学习模型。首先,两个或两个以上的联合学习参与者协作构建一个共享的机器学习模型,每个参与者都有几个训练数据,可以用来训练该模型。第二,在联邦学习模型的训练过程中,每个参与者拥有的数据不会离开参与者,即数据不会离开数据所有者。与联邦学习模式相关的信息可以在双方之间以加密的方式传输和交换,需要确保没有参与者能够推断出其他方的原始数据。此外,联邦学习模型的性能必须能够完全接近理想模型的性能,这意味着通过收集和训练所有训练数据而获得的机器学习模型。
我们使用水平联邦学习,它在样本数据不同的情况下处理具有相同特征 $X$ 和标签信息 $Y$ 的跨平台数据,因此它适用于我们所研究的谣言检测情况。在典型的联邦学习范式中,第 $i$ 个客户端的局部目标函数如 $\text{eq.3}$ 所示。 其中 $D_i$ 为第 $i$ 个客户端的本地数据集,$f$ 为参数为 $w$ 的模型的损失函数,$n_i$ 为第 $i$ 个客户端的数据量。
${\large F_{i}(w)=\frac{1}{n_{i}} \sum\limits _{j \in D_{i}} f_{j}(w)} \quad\quad\quad(3)$
中心服务器目标函数 $F(w)$ 通常计算为 $\text{eq.4}$ 。其中 $m$ 为参与培训的客户端设备总数,$n$ 为所有客户端数据量之和。
${\Large \min _{w} F(w)=\sum\limits _{i=1}^{m} \frac{n_{i}}{n} F_{i}(w)} \quad\quad\quad(4)$
3 FedGAT model
整体框架如下:
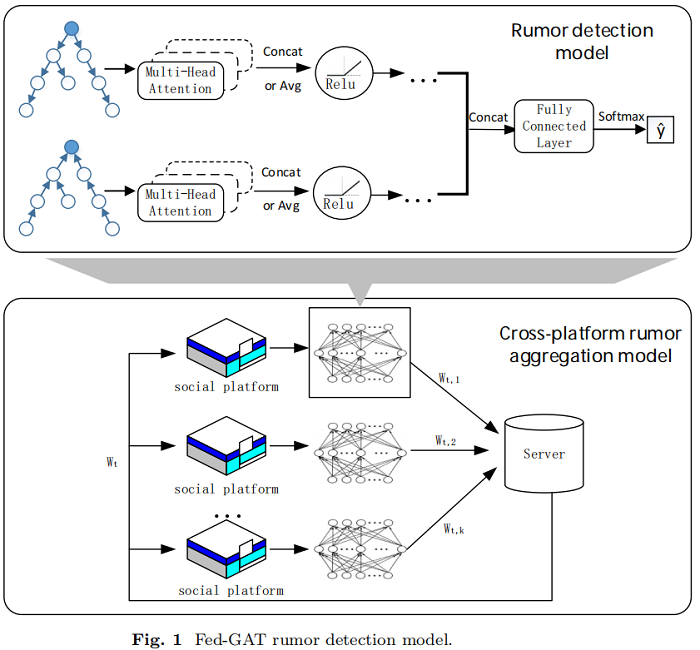
每个社交平台都在本地使用专有数据进行谣言检测,并将检测模型训练过程中生成的模型参数发送到终端服务器进行聚合处理。服务器端的全局模型将处理后的模型参数返回给本地模型,然后本地模型根据跨平台信息对自己模型的参数进行微调。
本文提出的跨平台谣言检测模型包括局部谣言检测模型和跨平台数据处理的联邦学习范式两部分,我们将详细介绍我们的 FedGAT模型。
根据经验,帖子的内容信息可以通过源帖子和转发的帖子之间的内容来反反映。此外,对于每个事件,第一个帖子的原始内容信息往往是最重要的,而后续的转发帖子是对原始帖子内容的评论。所以本文使用 双向图注意网络 作为本文的谣言检测模型的基础,其中,双向模型可以综合谣言信息沿自顶向下和自底向上的传播方向,且GAT模型可以增强对源帖子信息的关注。
3.1 Preprocessing of rumor data
首先,对谣言数据中的文本信息进行词向量处理,并使用 TF-IDF 计算文本中单词的频率作为初始特征。每个单词向量的维度是 5000,每个维数的值表示文章中某个单词的频率。
然后,根据帖子之间的转发关系构建图结构 $\operatorname{Graph}_{i}=\left(V_{i}, E_{i}\right)$。
定义:
- $\operatorname{Graph}_{i}^{T D}=\left(V_{i}, E_{i}^{T D}\right)$
- $Graph_{i}^{B U}=\left(V_{i}, E_{i}^{B U}\right)$
- $A_{i}^{T D}=\left(A_{i}^{B U}\right)^{T}$
- $H_{i}=\left[h_{i, 0}^{T}, h_{i, 1}^{T}, \ldots, h_{i, n_{i}}^{T}\right]$
3.2 Local model training on social platform
多头注意力:
${\large h_{i}^{T D^{\prime}}=\operatorname{Re} L U\left(\underset{h e a d=1}{5} \sigma\left(\sum_{j \in{ }_{i} \cup i} \alpha_{i j}^{T \text { Dhead }} W^{T D h e a d} h_{j}^{T D}\right)\right)} \quad\quad\quad(5)$
${\large h_{i}^{\mathrm{BU}}=\operatorname{Re} L U\left(\underset{h e a d=1}{5} \sigma\left(\sum\limits_{j \in_{i} \cup i} \alpha_{i j}^{\mathrm{BUhead}} W^{\mathrm{BUhead}} h_{j}^{\mathrm{BU}}\right)\right)} \quad\quad\quad(6)$
最后,拼接 top-down 和 bottom-up directions 的嵌入矩阵,最后使用 softmax 函数对输出的分类结果进行处理,如 $\text{Eq.7}$ 所示:
$\hat{y}=\operatorname{softmax}\left(F C\left(\left(H^{T D^{\prime}}, H^{B U^{\prime}}\right)\right)\right) \quad\quad\quad(7)$
3.3 Aggregate model parameters on terminal server
水平联合学习的终端服务器是对不同社交平台的模型训练数据进行聚合,在更新全局模型后,将更新后的参数变化发送回这些本地社交平台。在这里的配置中,我们设置了每轮训练的客户端数量和迭代次数等配置文件,并将之前定义的 Bi-GAT 谣言检测模型作为服务器端的初始模型。该模型用于接收所有客户端训练参数信息。
本部分我们选择的聚合函数是经典的 FedAvg 算法,其计算公式如 $\text{Eq.8}$ 所示:
$G^{t+1}=G^{t}+\frac{1}{m} \sum_{i=1}^{m}\left(F_{i}^{t+1}-G^{t}\right) \quad\quad\quad(8)$
其中 $G$ 和 $F$ 分别表示全局模型和局部模型,$t$ 表示第 $t$ 轮训练。它的主要功能是在定义了构造函数后,使用客户端上传的接收模型来更新全局模型。
在服务器上进行参数更新后,社交平台将根据返回的参数信息调整其本地模型。我们将服务器端设置的配置信息复制到本地端。从服务器接收到全局模型的优化参数后,对每个社交平台客户端的谣言检测模型进行修改,如 $\text{Eq.9}$ 所示
$F_{i}^{t+1}=(1-\lambda) F_{i}^{t}+\lambda G^{t} \quad\quad\quad(9)$
其中,$\lambda$ 是一个超参数,用来表示其他社交平台数据对其本地模型的影响程度,并且参与联邦学习的多个社交平台越相似,$\lambda$ 的价值就越大。
4 Experiments
Dataset
结果
$F 1=\frac{2 \cdot \text { Precision } \cdot \text { Recall }}{\text { Precision }+\text { Recall }}$

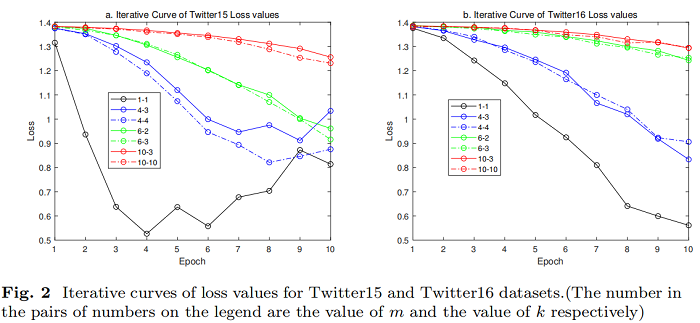
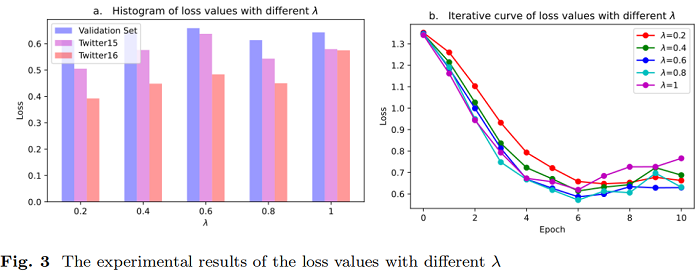
参数分析
5 Conclusion
跨不同社交平台的谣言检测问题是一个值得研究的领域。本文将联邦学习框架与双向图注意网络谣言检测模型相结合,构建了联邦图注意网络模型。它可以解决不同社交平台上的谣言检测中的数据岛隔离问题,并可以安全可靠地进行跨平台的谣言检测。可以从仿真实验结果使用公共Twitter谣言检测数据集提出的 FedGAT 模型可以实现优秀的结果在处理数据集从不同平台的同时,可以发现谣言检测非常适合建立一个模型基于图关注网络。此外,我们还分析了模型中 m、k、λ 等参数的影响。我们发现,模型在不同λ水平下所能达到的最小损失值没有太大差异,但对模型的模型优化率有影响。λ越大,模型训练的损失值可以减小得越快。平台总数 m 的增加不利于更准确的谣言预测。在每个谣言检测训练中,每个训练阶段都应该使用尽可能多的客户数据。
由于本文的实验只是人工构建了数据集来模拟不同社交平台的谣言数据,因此可能与实际的跨平台谣言检测数据集存在一些差异。我们期望跨平台谣言检测FedGAT模型在未来能够基于现实生活中的多社交平台场景进行模型优化。此外,本文中使用的Bi-GAT模型也可以被现有的优秀谣言检测模型所取代,水平联邦学习范式也可以进行相应的修改。我们期待着在未来对谣言检测进行更多的研究。
论文解读(FedGAT)《Federated Graph Attention Network for Rumor Detection》的更多相关文章
- 论文解读《Bilinear Graph Neural Network with Neighbor Interactions》
论文信息 论文标题:Bilinear Graph Neural Network with Neighbor Interactions论文作者:Hongmin Zhu, Fuli Feng, Xiang ...
- 谣言检测——《MFAN: Multi-modal Feature-enhanced Attention Networks for Rumor Detection》
论文信息 论文标题:MFAN: Multi-modal Feature-enhanced Attention Networks for Rumor Detection论文作者:Jiaqi Zheng, ...
- 论文笔记之:Graph Attention Networks
Graph Attention Networks 2018-02-06 16:52:49 Abstract: 本文提出一种新颖的 graph attention networks (GATs), 可 ...
- 《Graph Attention Network》阅读笔记
基本信息 论文题目:GRAPH ATTENTION NETWORKS 时间:2018 期刊:ICLR 主要动机 探讨图谱(Graph)作为输入的情况下如何用深度学习完成分类.预测等问题:通过堆叠这种层 ...
- graph attention network(ICLR2018)官方代码详解(tensorflow)-稀疏矩阵版
论文地址:https://arxiv.org/abs/1710.10903 代码地址: https://github.com/Diego999/pyGAT 之前非稀疏矩阵版的解读:https://ww ...
- graph attention network(ICLR2018)官方代码详解(te4nsorflow)
论文地址:https://arxiv.org/abs/1710.10903 代码地址: https://github.com/Diego999/pyGAT 我并没有完整看过这篇论文,但是在大致了解其原 ...
- 论文解读《Cauchy Graph Embedding》
Paper Information Title:Cauchy Graph EmbeddingAuthors:Dijun Luo, C. Ding, F. Nie, Heng HuangSources: ...
- 目标检测论文解读1——Rich feature hierarchies for accurate object detection and semantic segmentation
背景 在2012 Imagenet LSVRC比赛中,Alexnet以15.3%的top-5 错误率轻松拔得头筹(第二名top-5错误率为26.2%).由此,ConvNet的潜力受到广泛认可,一炮而红 ...
- 论文笔记:(2019)GAPNet: Graph Attention based Point Neural Network for Exploiting Local Feature of Point Cloud
目录 摘要 一.引言 二.相关工作 基于体素网格的特征学习 直接从非结构化点云中学习特征 从多视图模型中学习特征 几何深度学习的学习特征 三.GAPNet架构 3.1 GAPLayer 局部结构表示 ...
随机推荐
- 分享一个基于Abp Vnext开发的API网关项目
这个项目起源于去年公司相要尝试用微服务构建项目,在网关的技术选型中,我们原本确认了ApiSix 网关,如果需要写网关插件需要基于Lua脚本去写,我和另外一个同事当时基于这个写了一个简单的插件,但是开发 ...
- Seata-初体验以及避坑
Seata是什么 这里引用官方解释 Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务.Seata 将为用户提供了 AT.TCC.SAGA 和 XA 事务模式,为用 ...
- linux 安装redis及问题收集
contos 7 下安装redis教程可参照https://www.cnblogs.com/hxun/p/11075755.html值得注意的是在第6步方法一(所以建议使用方法二),如果直接使用xft ...
- ubu18时间设置
ubu18 日期设置 1.date date 命令修改系统时间,重启失效,需要写入硬件Bios #查看日期 date #修改日期 date -s "2022-01-14 09:32:00&q ...
- JAVA基础-11-Java Number 类--九五小庞
问题:一直有疑惑,为什么java中学习了基本数据类型,而不使用,使用的是封装的对象. 解答: 一般地,当需要使用数字的时候,我们通常使用内置数据类型,如:byte.int.long.double 等. ...
- 在win10系统环境下,安装配置sublime 3,构建python和vue.js开发环境(插件)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_131 疫情当下,最近一直在用mac下的虚拟机运行win10系统,由于在线人数过多,直播授课的时候使用vscode的时候内存暴涨,于 ...
- AWS EKS 创建k8s生产环境实例
#AWS EKS 创建k8s生产环境实例 在AWS部署海外节点, 图简单使用web控制台创建VPC和k8s集群出错(k8s), 使用cli命令行工具创建成功 本实例为复盘, 记录aws命令行工具创建e ...
- EPLAN 中的符号、元件、部件与设备之间的区别
符号(Symbol):电气符号是电器设备(Electrical equipment)的一种图形表达,符号存放在符号库中,是广大电气工程师之间的交流语言,用来传递系统控制的设计思维的.将设计思维体现出来 ...
- tomcat线程池
tomcat线程池和普通的线程池设计上有所区别,下面主要来看看它是如何设计的 tomcat中线程池的创建 org.apache.tomcat.util.net.AbstractEndpoint#cre ...
- 关于linux的一点好奇心(四):tail -f文件跟踪实现
关于文件跟踪,我们有很多的实际场景,比如查看某个系统日志的输出,当有变化时立即体现,以便进行问题排查:比如查看文件结尾的内容是啥,总之是刚需了. 1. 自己实现的文件跟踪 我们平时做功能开发时,也会遇 ...