MySQL高性能索引策略和查询性能优化
前缀索引和索引选择性
有时候需要索引很长的字符,这会让索引变得大且慢。一个策略是模拟哈希索引。
通常可以索引开始的部分字符,这样可以大大解约索引空间,提高索引效率。但这样会降低索引的选择性。
索引的选择性:不重复的索引值(也成为基数)和数据表的记录总数比值。索引的选择性越高则查询效率越高,因为选择性高的索引可以在查找时过滤更多的行。唯一索引的选择性为1,是选择性最好的。
前缀索引是一种能使索引更小更快的办法,但也有缺点:
MySQL无法使用ORDER BY和GROUP BY,也无法使用覆盖扫描。
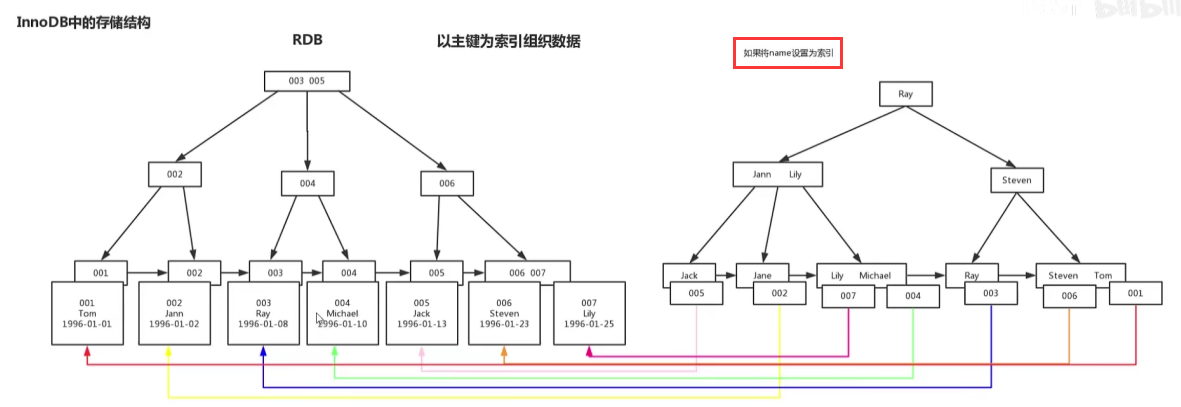
聚簇索引
聚簇索引并不是一种单独的索引类型,是一种数据存储方式。
当表有聚簇索引时,它的数据行实际上存放在索引的叶子页。
聚簇:数据行和相邻的键值紧凑的存储在一起。
如果没有定义主键,InnoDB会选择一个唯一的非空索引代替。
如果没有这样的索引,会隐式定义一个主键作为聚簇索引。
聚簇索引的缺点
插入速度严重依赖插入顺序。按照主键的顺序插入是加载数据到InnoDB表中速度最快的方式。但如果不是按照主键顺序加载数据,最好使用OPYIMIZE TABLE重新组织表。
基于聚簇索引的表在插入新行,或者主键被迁移时,可能会“页分裂”。当行的主键值要求必须将这一行插入到某个已满的页中时,存储引擎会将该页分裂成两个页面来容纳该行,这是一次页分裂操作。页分裂会导致表占用更多的磁盘空间。
覆盖索引
通常大家会根据查询的WHERE条件创建合适的索引,设计优秀的索引也可以使用索引来直接获取列的数据。
如果索引的叶子结点已经包含要查询的数据,那还要什么必要再回表查询呢?如果一个索引包含所有需要查询的字段的值,我们称之为“覆盖索引”。
延迟关联
使用inner join做子查询。在查询的第一个阶段可以使用覆盖索引。虽然无法使用索引覆盖整个查询,但比完全无法利用索引覆盖的好。
冗余和重复索引
索引越大越多,插入数据越慢。
可以使用Percona Toolkit中的pt-duplicate-key-checker分析表结构找出冗余的索引。
单表建多少个索引才合适?
大表,主键有一个唯一索引。再有一到两个组合索引,最多三个索引足够用了。
索引数量不能超过4个/表。
一切服从应用需要。在一张表上创建多少索引,创建什么样的索引,并无一定之规。不能说一张表上有了 7个索引,就不能再创建第 8个索引了。
索引的多少取决于具体的业务场景。
在oltp中,表经常需要insert等,那么索引不能过多,一般超过3个就会对性能有影响。
在olap中如果表只是用于查询,那么建多个索引也无妨。
索引和锁
索引可以让查询锁定更少的行。但是,如果索引无法过滤掉无效的行,那么在InnoDB检索到数据并返回给服务器层以后,MySQL才能用那个用WHERE子句,这时已经无法避免锁定行了:InnoDB已经锁定了这些行。
mysql> select actor_id from sakila.actor where actor_id < 5 and actor_id <> 1 for update;
虽然这条查询返回的是2,3,4,但是实际上获取了1-4的排他锁。
话句话说,存储引擎的操作是“找小于5的记录”,服务器并没有告诉InnoDB可以过滤第1行的WHERE条件。注意到EXPLAIN的Extra列出现了“Using where”,这表示MySQL将存储引擎返回行以后再应用WHERE过滤条件。
using where 代表MYSQL服务器层在存储引擎层返回行以后再应用WHERE过滤条件
查询性能优化
对于性能低下的查询,通过两个步骤来分析非常有效:
1、确认应用程序是否在检索大量超过需要的数据。这意味着访问了过多的行或者是过多的列。
2、确认MySQL服务器层是否在分析大量超过需要的数据行。
比如使用 * 来返回全部列,其实有些列是用不到的,应该精简,或者说重复查询相同改的数据,这应该把这种数据放到缓存里,下次查先从缓存取,热点数据每次取可以给加过期时间。
确认EXPLAIN中扫描的行数和访问类型
在EXPLAIN中的type列是访问类型,从全表扫描、索引扫描、范围扫描、唯一索引查询、常数引用(全索范唯),他们的查询速度是从慢到快。
Reference
《高性能MySQL》
MySQL高性能索引策略和查询性能优化的更多相关文章
- Atitit 如何利用先有索引项进行查询性能优化
Atitit 如何利用先有索引项进行查询性能优化 1.1. 再分析的话就是我们所写的查询条件,其实大部分情况也无非以下几种:1 1.2. 范围查找 动态索引查找1 1.2.1. 索引联合 所谓的索引联 ...
- 高性能MySQL笔记 第6章 查询性能优化
6.1 为什么查询速度会慢 查询的生命周期大致可按照顺序来看:从客户端,到服务器,然后在服务器上进行解析,生成执行计划,执行,并返回结果给客户端.其中“执行”可以认为是整个生命周期中最重要的阶段. ...
- mysql高性能索引策略
转载说明:http://www.nyankosama.com/2014/12/19/high-performance-index/ 1. 引言 随着互联网时代地到来,各种各样的基于互联网的应用和服务进 ...
- 高性能mysql——高性能索引策略
<高性能MySQL>读书笔记 一. 索引的优点 1. 索引可以让服务器快速定位到表的指定位置,大大减少了服务器需要扫描的数量: 2. 最常见的B-Tree索引按照顺序存储数据,可以用来做o ...
- 高性能MySQL(五):查询性能优化
当向MySQL 发送一个请求的时候MySQL 到底做了什么? 1.客户端发送一条查询给服务器 2.服务器先检查查询缓存,如果命中了缓存,则立即返回存储在缓存中的结果.否则进入下一阶段 3.服务器端进行 ...
- mysql中百万级别分页查询性能优化
前提条件: 1.表的唯一索引 2.百万级数据 SQL语句: select c.* FROM ( SELECT a.logid FROM tableA a where 1 = 1 <#if pho ...
- MySQL查询性能优化七种武器之索引下推
前面已经讲了MySQL的其他查询性能优化方式,没看过可以去了解一下: MySQL查询性能优化七种武器之索引潜水 MySQL查询性能优化七种武器之链路追踪 今天要讲的是MySQL的另一种查询性能优化方式 ...
- Sql Server查询性能优化之走出索引的误区
据了解绝大多数开发人员对于索引的理解都是一知半解,局限于大多数日常工作没有机会.也什么没有必要去关心.了解索引,实在哪天某个查询太慢了找到查询条件建个索引就ok,哪天又有个查询慢了,再建立个索引就是, ...
- 高性能mysql 第六章查询性能优化 总结(上)查询的执行过程
6 查询性能优化 6.1为什么查询会变慢 这里说明了的查询执行周期,从客户端到服务器端,服务器端解析,优化器生成执行计划,执行(可以细分,大体过程可以通过show profile查看),从服务器端返 ...
- mysql笔记03 查询性能优化
查询性能优化 1. 为什么查询速度会慢? 1). 如果把查询看作是一个任务,那么它由一系列子任务组成,每个子任务都会消耗一定的时间.如果要优化查询,实际上要优化其子任务,要么消除其中一些子任务,要么减 ...
随机推荐
- linux查看进程信息
top 实时查看进程信息,展示进程id,使用内存,占用cpu等信息,可以查看内容占用最多.cpu使用最多的进程,然后再根据进程id查看进程的详细信息.实时更新 ps 瞬时查看进程情况,ps -ef | ...
- C#——》创建Windows服务,发布并调试Windows服务
一,创建一个windows服务项目. 二,双击Service1.cs进入设计界面,在空白处右键单击选择添加安装程序,如下图所示. 三,添加安装程序后,会进入如下图界面,生成两个组件:serviceP ...
- #硬件 #资讯 #科普 #短报 SSD价格跳水根本停不下来!不断刷出新低
一份来自日本的统计显示,10~12月的初步统计显示,PC市场的指标产品中,256GB TLC颗粒SSD价格再次下跌2美元,现在只有29.5美元.这已经是该指标产品连续5个季度下跌,创下史上心底记录,同 ...
- 关于在Eclipse中使用EclEmma
在LAB2中,要求使用EclEmma来统计JUnit测试用例的代码覆盖度.下面就来说说如何进行基本的使用来应付实验(bushi). 在这给出完全体,可以访问下面的网址进行学习. http://www. ...
- 微信小程序通过经纬度计算两点之间距离
小程序中通过经纬度计算两点之间的距离km 1.拾取两地经纬度坐标 . data:{ //当前定位位置 latitude: null, longitude: null, // 目的地坐标 latitud ...
- create-react-app react 使用dll抽离公共库,大幅缩减项目体积,及项目打包速度
1.安装依赖(clean-webpack-plugin.add-asset-html-webpack-plugin.webpack-cli) yarn add clean-webpack-plugin ...
- 01. JavaScript基础知识
一.JavaScript简介 JavaScript 是一门解释型编程语言,解释型编程语言指代码不需要手动编译,而是通过解释器边解释边执行.所以,要运行 JS,我们需要在计算机中安装 JS 的解释器 ...
- BOM的概述及方法
BOM的概述: bom 称为浏览器对象模型(bowser object model),也就意味他可以获取浏览器上的所有内容以及相关的操作.BOM缺乏规范的,存在共有对象来解决这个问题,但是共有对象也存 ...
- MSSQL数据类型
数据类型 描述 备注 对应vba类型 字符 char(n) n为1-8000字符之间 nchar(n) n为1-4000 unicode字符之间 nvarchar(max) ...
- Kafka源码阅读系列——Producer
Producer Kafka源码的exmaple模块有一个Producer类,继承了Thread类,构造方法会指定topic,是否异步,是否幂等,配置Kafka集群信息,初始化一个KafkaProdu ...