从零教你使用MindStudio进行Pytorch离线推理全流程
摘要:MindStudio的是一套基于华为自研昇腾AI处理器开发的AI全栈开发工具平台,该IDE上功能很多,涵盖面广,可以进行包括网络模型训练、移植、应用开发、推理运行及自定义算子开发等多种任务。
本文分享自华为云社区《使用MindStudio进行Pytorch离线推理全流程》,作者:yd_281378454。
1 MindStudio环境搭建
本次实验在MindStudio上进行,请先按照教程配置环境,安装MindStudio。
MindStudio的是一套基于华为自研昇腾AI处理器开发的AI全栈开发工具平台,该IDE上功能很多,涵盖面广,可以进行包括网络模型训练、移植、应用开发、推理运行及自定义算子开发等多种任务。MindStudio除了具有工程管理、编译、调试、运行等一般普通功能外,还能进行性能分析,算子比对,可以有效提高工作人员的开发效率。除此之外,MindStudio具有远端环境,运行任务在远端实现,对于近端的个人设备的要求不高,用户交互体验很好,可以让我们随时随地进行使用。
2 VPN安装和配置
安装好MindStudio后,需要配置远程环境。请按照教程进行VPN客户端的安装与配置。安装好VPN后,可以先在终端用ssh指令测试连接。(这一步是验证网络连接是否可用,也可以跳过)
3 创建推理工程
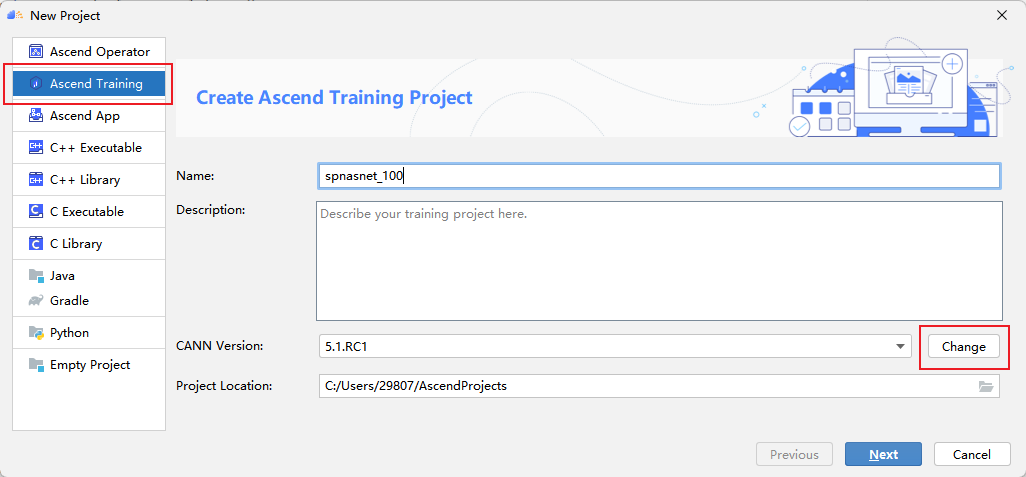
打开MindStudio,点击New Project,进入新建工程界面。选择Ascend APP。填入项目名spnasnet_100。首次新建训练工程时,需要配置CANN的版本。点击Change。
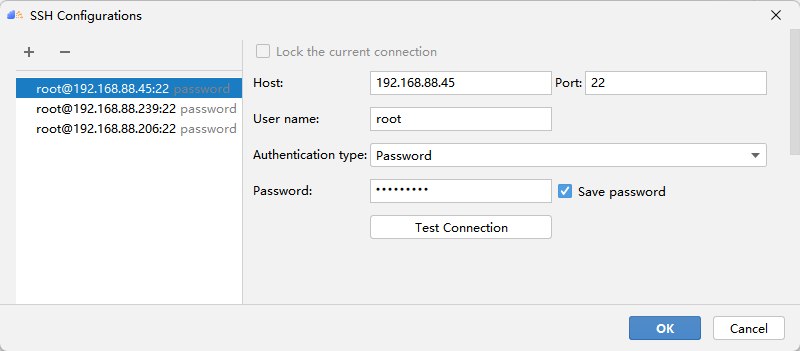
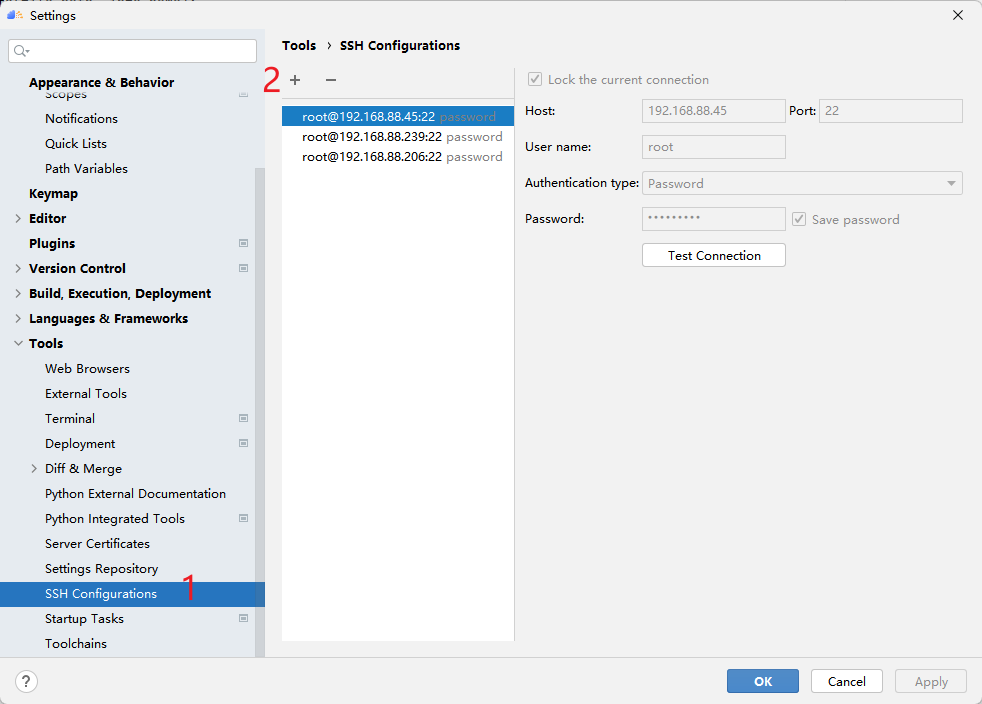
点击 + 配置远程连接,然后根据选项填入自己服务器的ip地址、端口号、用户名和密码等。
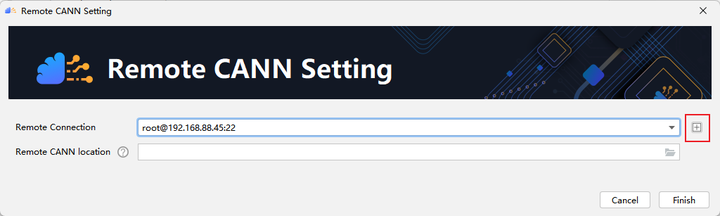
配置Remote CANN location。该参数需要填入ascend-toolkit在服务器上的路径地址。在这里,我们toolkit的路径如下:/usr/local/Ascend/ascend-toolkit/5.1.RC1。点击finishing进行配置。初次配置时时间稍长,请耐心等待。
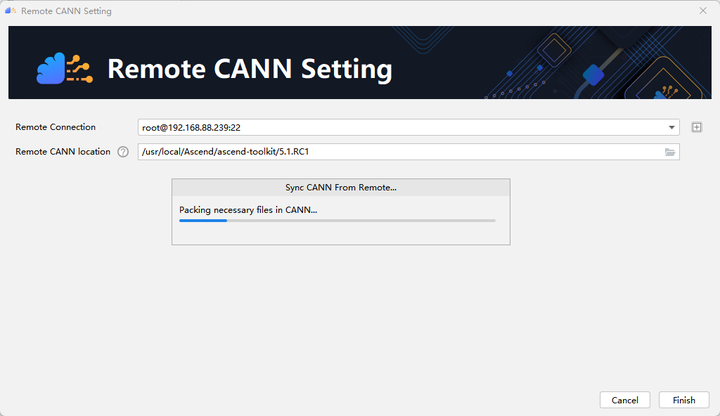
点击Next,选择Pytorch Project。
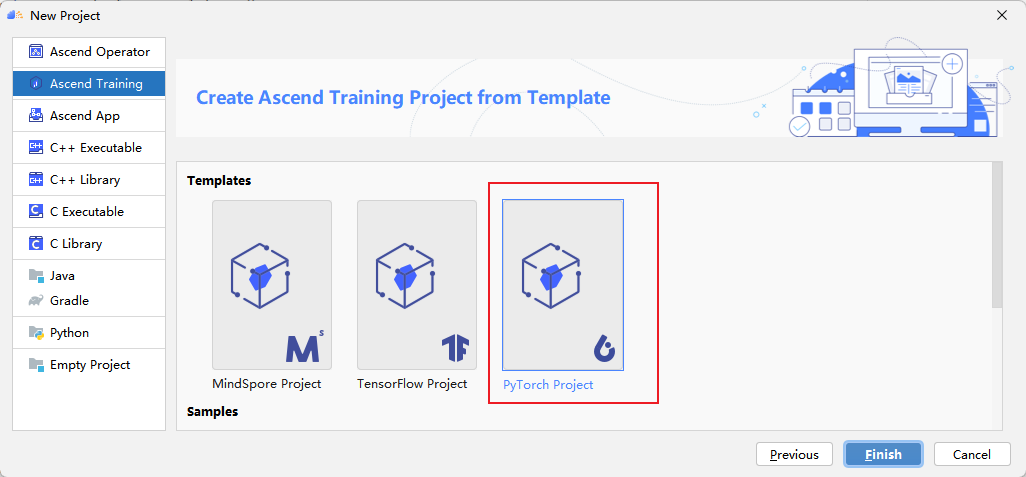
点击Finish,完成工程创建,进入工程主界面。
4 配置SSH和Deployment
在MindStudio的远程服务中,定义了SSH 配置和Deployment两个概念。前者SSH 配置类似MobaxTerm中的Session的概念,用户可以保存多个远程服务器的连接配置。后者Deployment管理远程开发时的本地文件与远程文件的同步。配置好Deployment后,我们就可以像使用本地python环境一样去使用远程的python环境了。点击File -> Settings -> Tools,即可看到两个设置的入口,下面分别介绍如何配置他们。
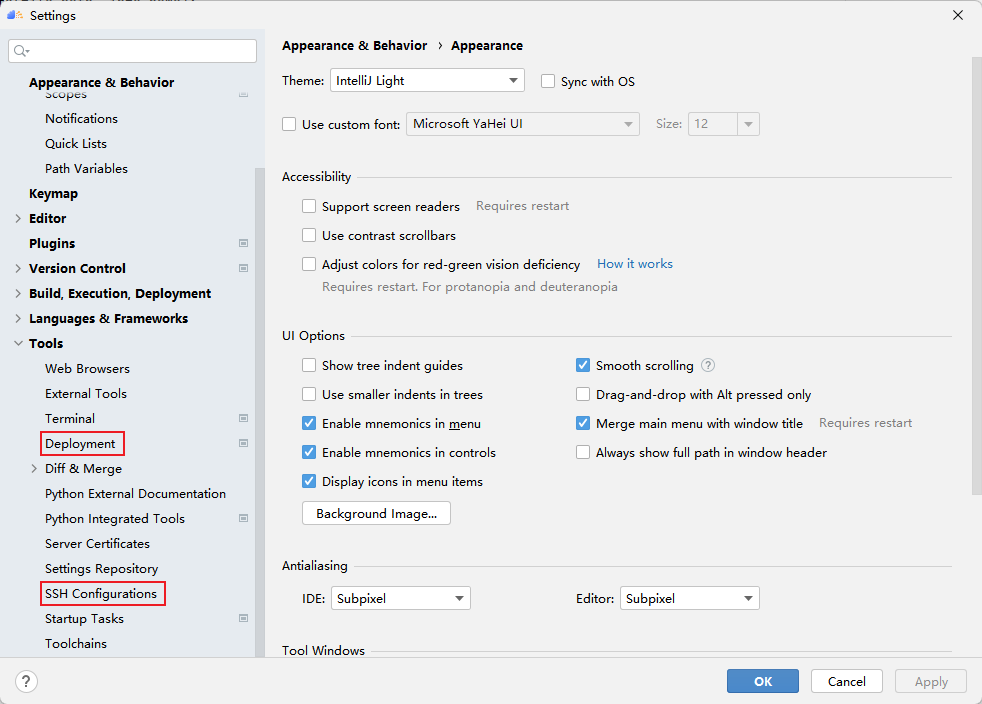
4.1 配置SSH
首先点击SSH Configurations,再点击 + 配置远程连接,然后根据选项填入自己服务器的ip地址、端口号、用户名和密码等。测试成功点击Apply即可保存配置,以后就可以一键连接啦!
4.2 配置Deployment
Deployment配置能够更精准地连接远程服务,它需要选择一个SSH连接定位远程主机,然后设置本地与远程项目目录的对应关系。如下图所示创建一个新的Deployment。
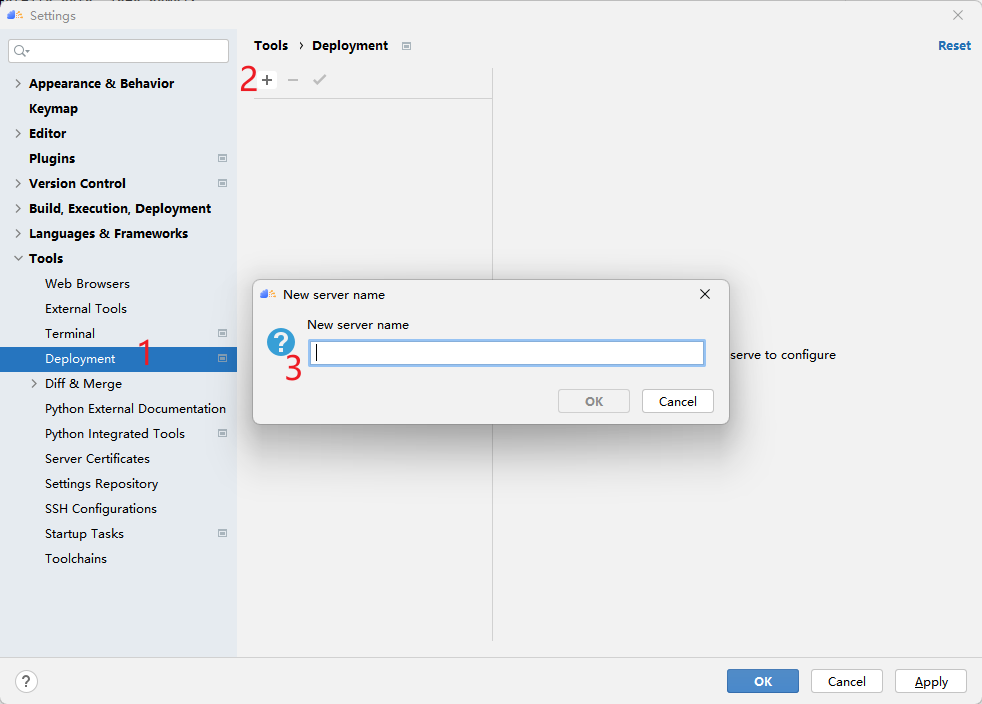
如图310是我创建的Deployment名字,首先选择连接哪一个SSH服务,然后测试连接是否可用。
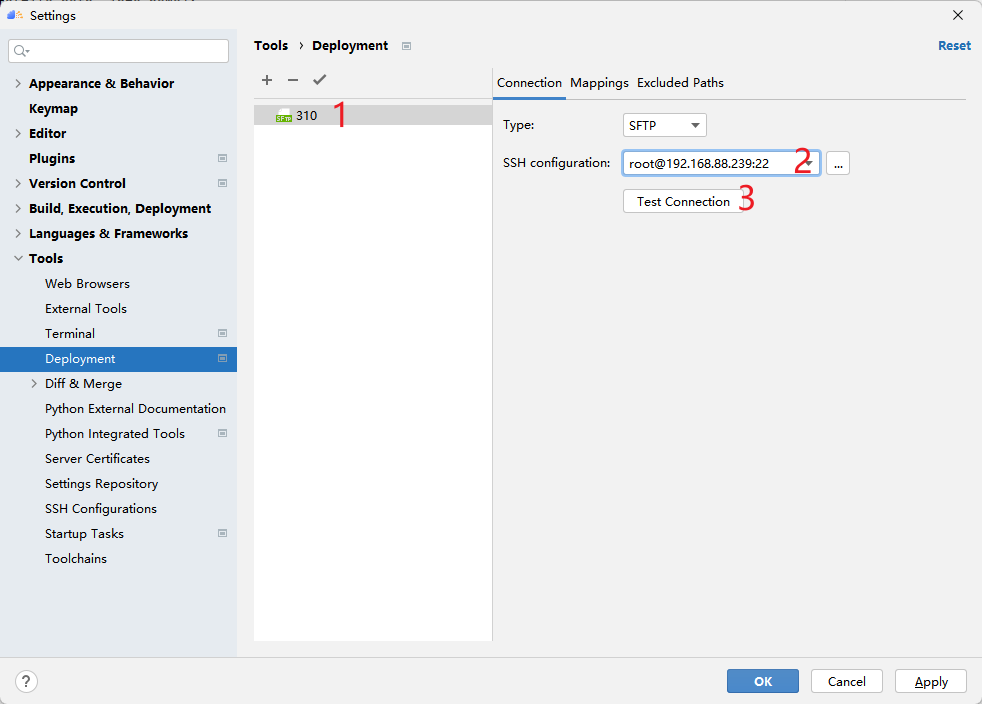
下一步,设置项目目录映射关系,点击Mappings,然后选择本地的项目目录和远程的项目目录(最好是提前创建好文件夹),接下来跑代码的时候MindStudio会保证这两个目录文件的同步。
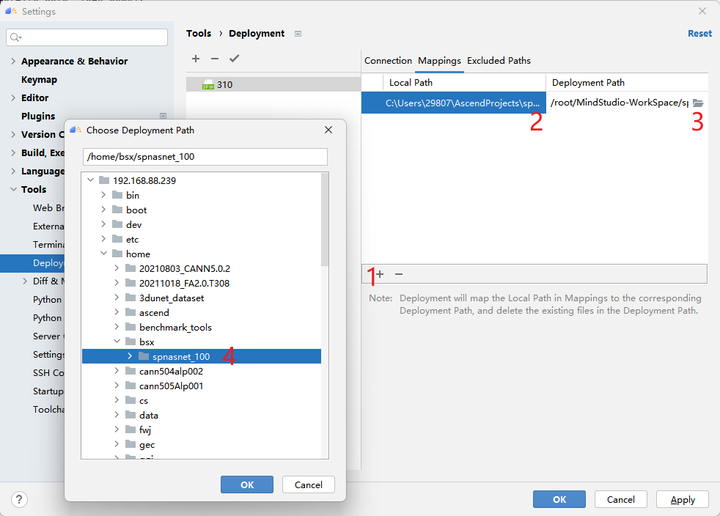
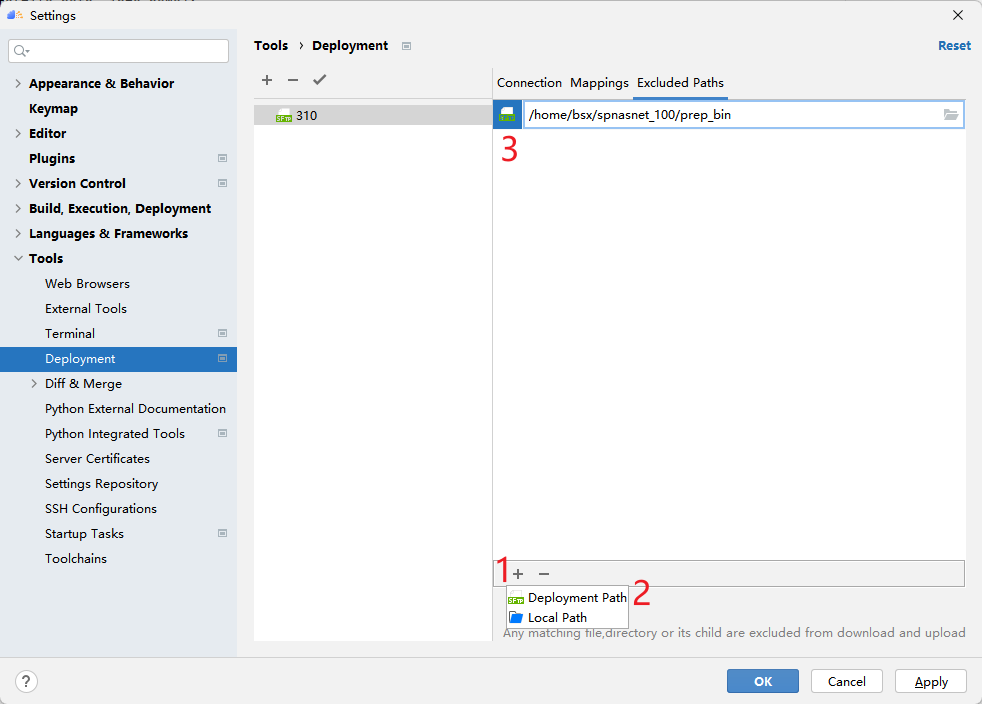
配置好Mappings后,建议配置Excluded Paths,因为MindStudio的默认同步行为会把Mappings对应目录的文件保持完全相同,这意味着只存在于远程的数据集文件夹会被删除(如果本地没有数据集)。在此我配置了几个需要排除的文件夹目录。
5 配置远程python解释器
现在,SSH和Deployment的映射关系已经配置好了,但是MindStudio还不知道python解释器的位置。因此,下面将介绍如何配置python解释器。
点击File -> Project Structure->SDKs可以看到如图所示的界面。点击+号,可以新增python SDK和JDK。这里只演示Python的添加方法。
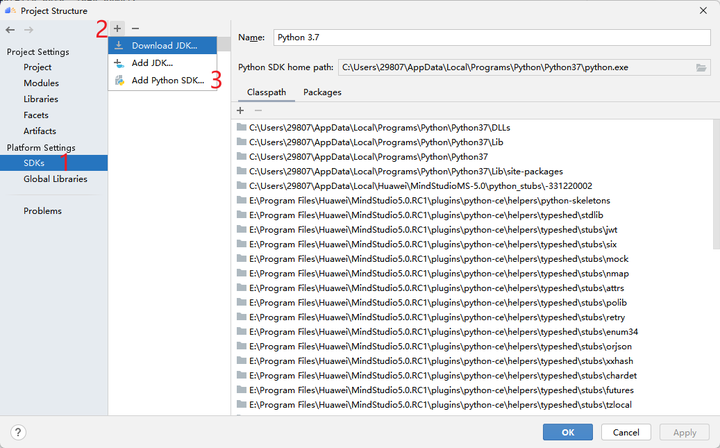
点击Add Python SDK后,将弹出下图所示的界面,点击左侧的SSH Interpreter,如下图所示,首先选择使用哪一个Deployment,这是刚刚我们配置过的。然后选择python解释器的路径。图中的路径是MindStudio自动检测出来的,但一般需要自己找自己的Python环境安装目录。如果是conda环境,可以使用which python找到python的安装路径。

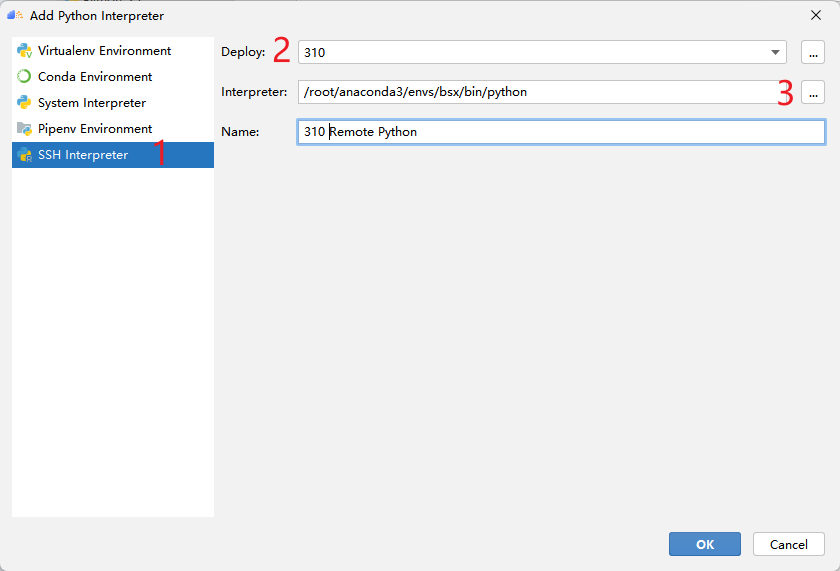
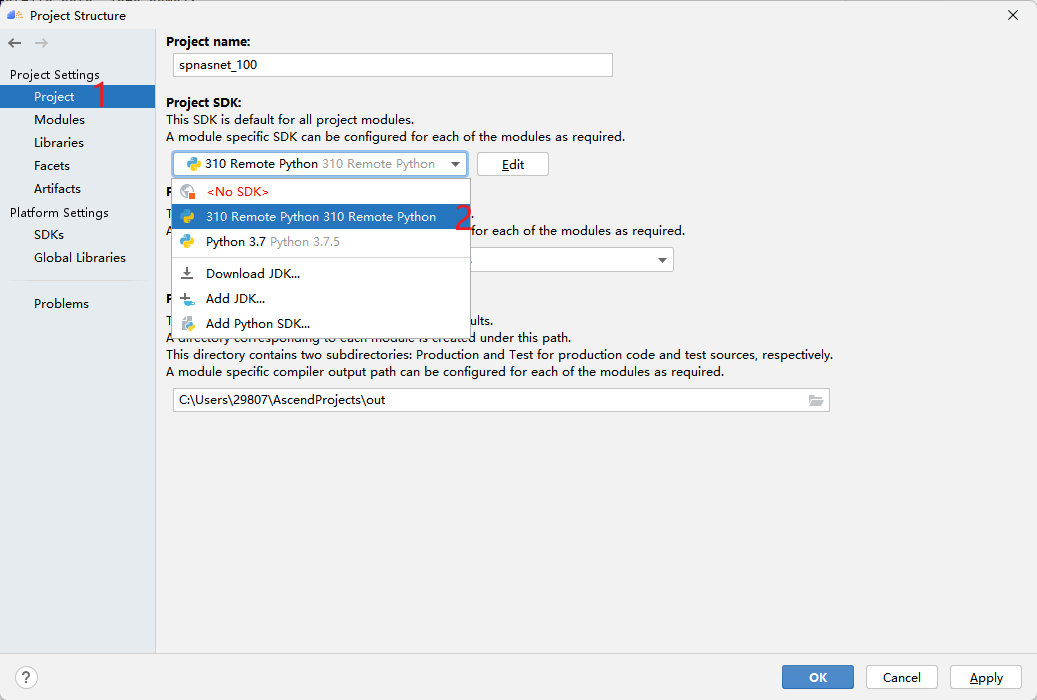
然后点击Project,选择刚才添加到MindStudio中的python解释器,将其作为本项目使用的解释器。
6 数据集准备
6.1 数据预处理
上传好数据集以后,执行 preprocess_spnasnet_100_pytorch.py脚本,生成数据集预处理后的bin文件。
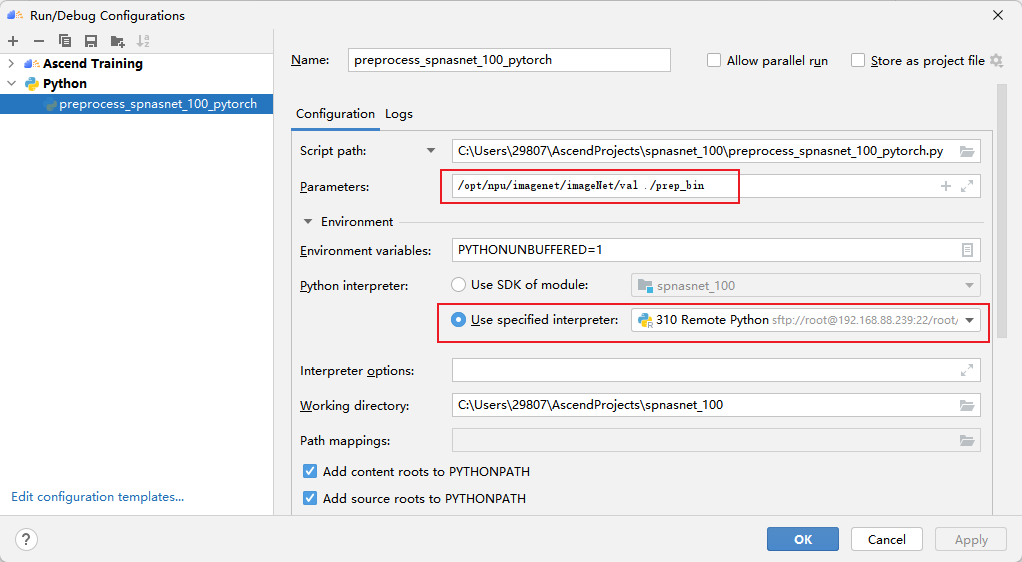
第一个参数为原始数据验证集(.jpeg)所在路径,第二个参数为输出的二进制文件(.bin)所在路径。每个图像对应生成一个二进制文件。
MindStudio会首先上传本地文件到远程服务器,将本地的文件同步到远程这个过程可能很慢,同步完成后开始运行Python代码,MindStudio会实时地在控制台打印输出:
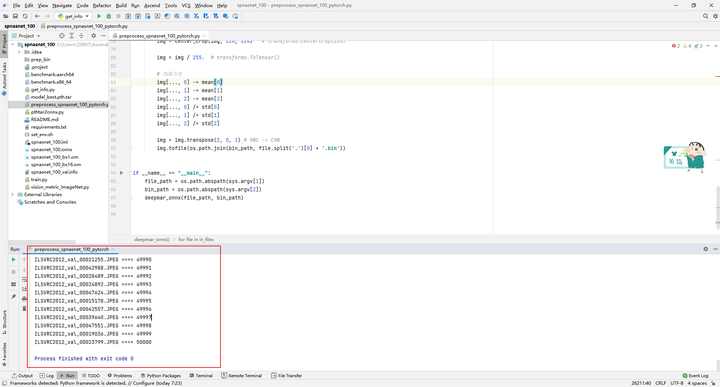
6.2 生成数据集info文件
执行get_info.py脚本,生成数据集信息文件。
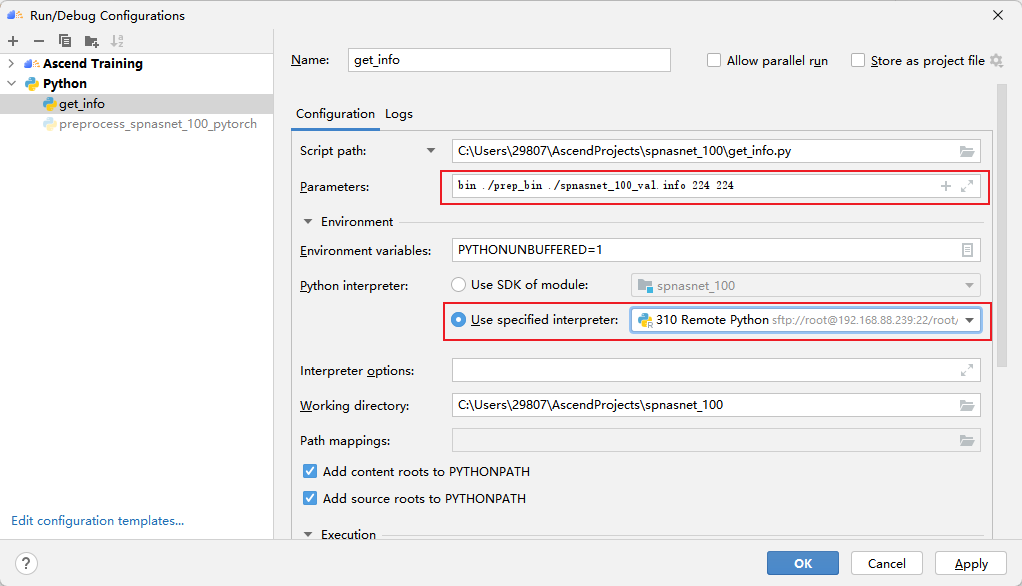
第一个参数为模型输入的类型,第二个参数为生成的bin文件路径,第三个为输出的info文件,第四、第五个为宽高信息。执行结果:

7 模型转换
本模型基于开源框架PyTorch训练的spnasnet_100进行模型转换。先使用PyTorch将模型权重文件.pth转换为.onnx文件,再使用ATC工具将.onnx文件转为离线推理模型文件.om文件。
首先获取权重文件。单击Link在PyTorch开源框架获中取经过训练的spnasnet_100权重文件model_best.pth.tar,源码中已提供下载权重文件。
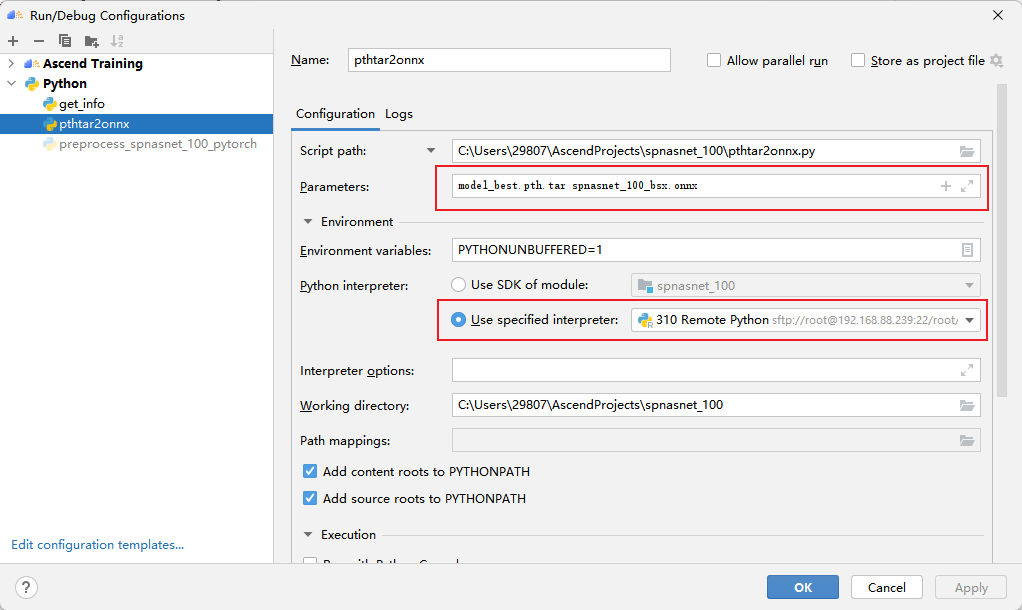
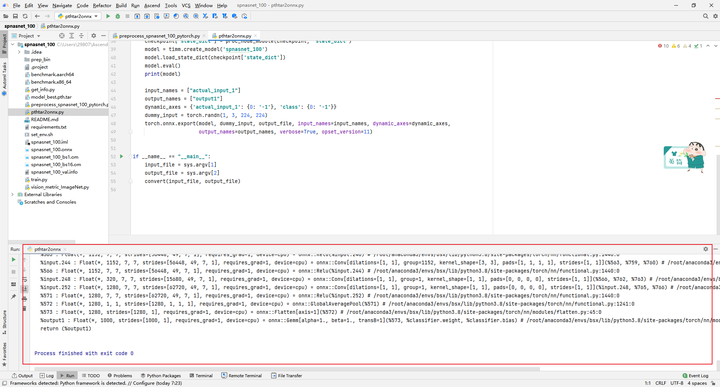
7.1 导出onnx文件
使用pthtar2onnx.py脚本将.pth文件转换为.onnx文件
7.2 导出om文件
从onnx转为om需要用atc工具,MindStudio提供了atc工具的窗口化应用,它会根据用户选择自动生成atc指令。Model Converter的入口如图所示:
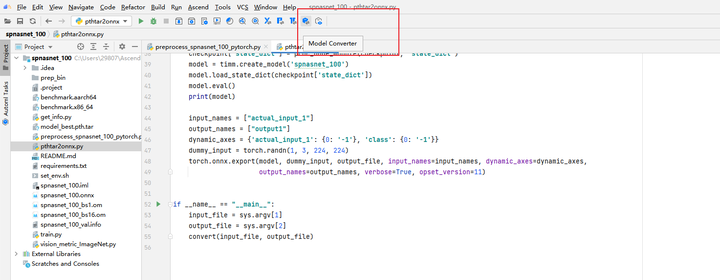
选择onnx模型路径,模型输出名称,目标设备,输入格式和batchsize等信息。
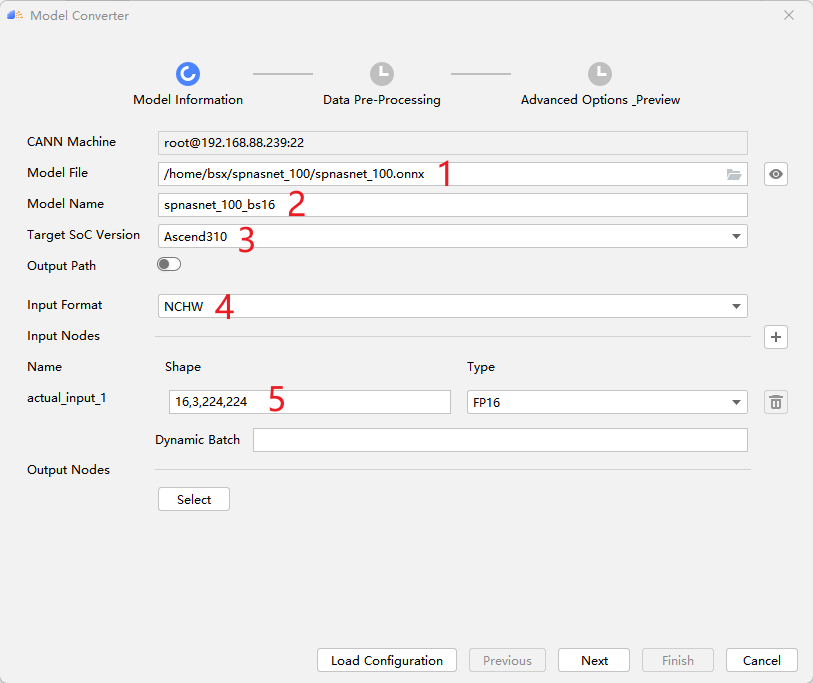
MindStudio自动生成如下atc指令,用户可以在此做最后的校验,点击Finish即可开始进行模型转换。
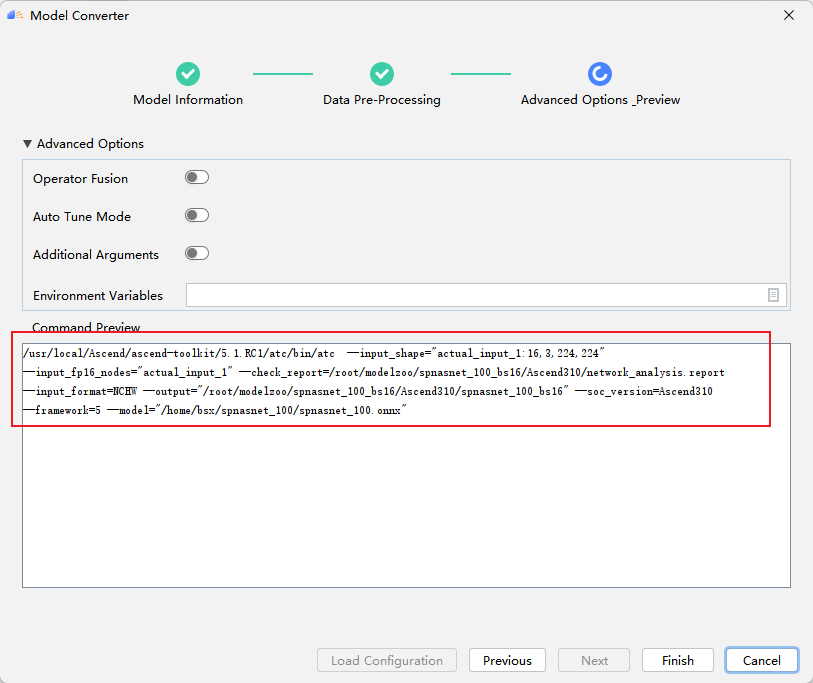
模型转换成功:
8 模型推理
使用benchmark工具进行推理。这个和前面的python脚本不同,它在MindStudio中属于ACL应用,可以如图所示创建应用:
点击 + 号,再点击Ascend App:
然后进行如下配置:
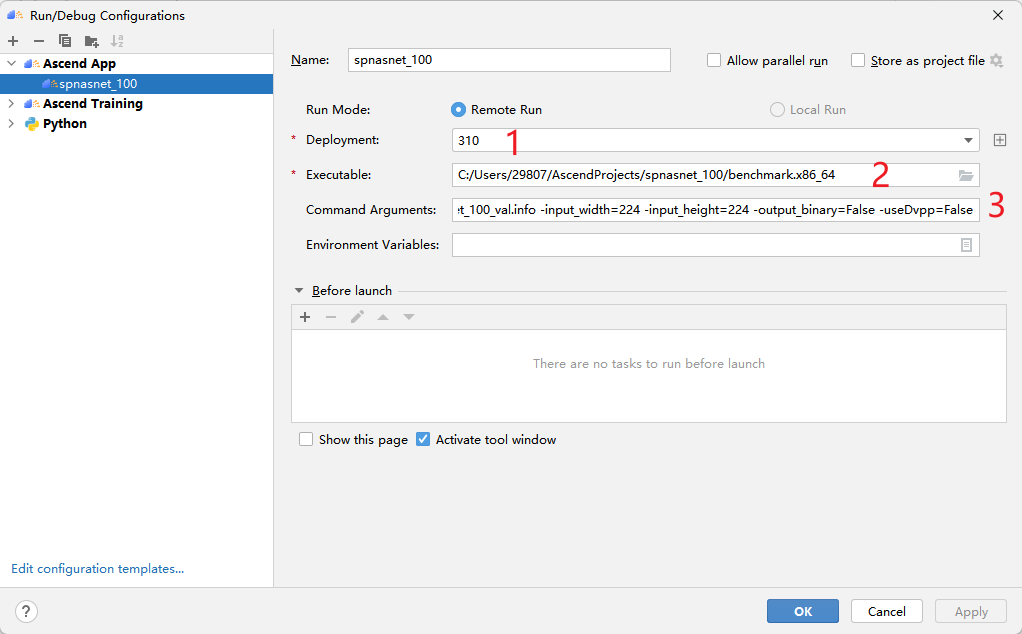
参数详情请参见《CANN推理benchmark工具用户指南》。推理后的输出默认在当前目录result下。
执行结果:
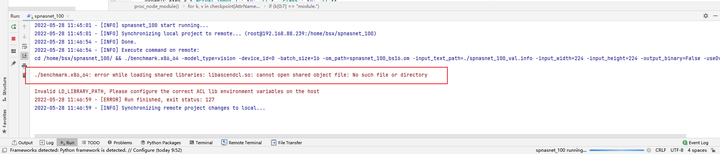
运行出错:error while loading shared libraries: libascendcl.so: cannot open shared object file: No such file or directory.
这个错误是因为没有配置好环境变量。因为我们在终端运行它时,一般要先执行一下:source /usr/local/Ascend/ascend-toolkit/set_env.sh,这一步操作在MindStudio中可以通过如图所示的方法配置环境变量解决:
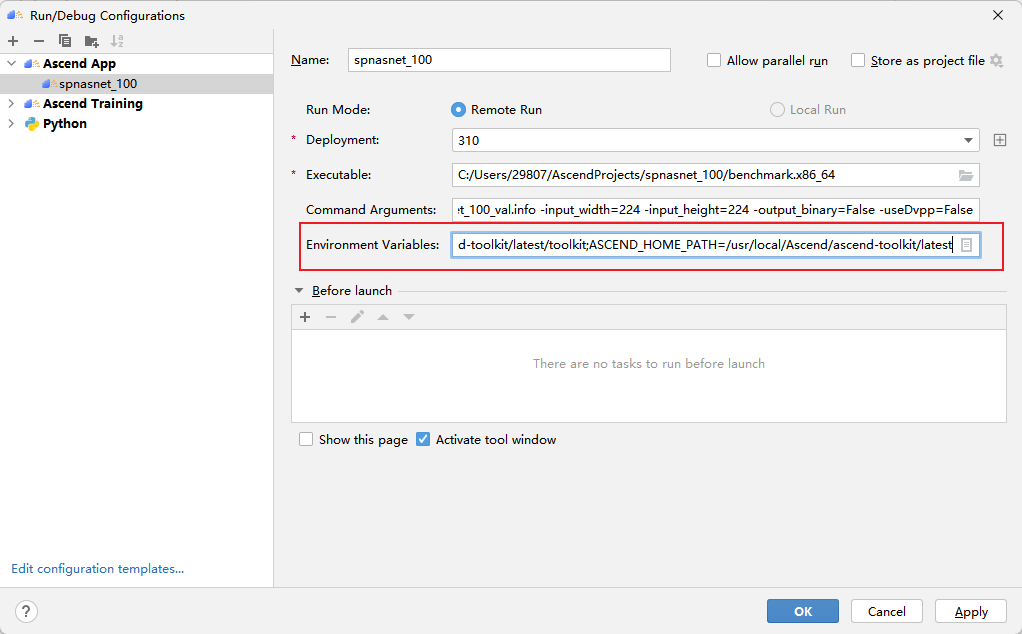
变量内容就是/usr/local/Ascend/ascend-toolkit/set_env.sh的内容,读者可以直接复制使用。
LD_LIBRARY_PATH=/usr/local/Ascend/ascend-toolkit/latest/lib64:/usr/local/Ascend/ascend-toolkit/latest/lib64/plugin/opskernel:/usr/local/Ascend/ascend-toolkit/latest/lib64/plugin/nnengine:$LD_LIBRARY_PATH;PYTHONPATH=/usr/local/Ascend/ascend-toolkit/latest/python/site-packages:/usr/local/Ascend/ascend-toolkit/latest/opp/op_impl/built-in/ai_core/tbe:$PYTHONPATH;PATH=/usr/local/Ascend/ascend-toolkit/latest/bin:/usr/local/Ascend/ascend-toolkit/latest/compiler/ccec_compiler/bin:$PATH;ASCEND_AICPU_PATH=/usr/local/Ascend/ascend-toolkit/latest;ASCEND_OPP_PATH=/usr/local/Ascend/ascend-toolkit/latest/opp;TOOLCHAIN_HOME=/usr/local/Ascend/ascend-toolkit/latest/toolkit;ASCEND_HOME_PATH=/usr/local/Ascend/ascend-toolkit/latest
设置变量后,再次启动运行,可以在控制台看到,在执行benchmark前,会首先export环境变量。
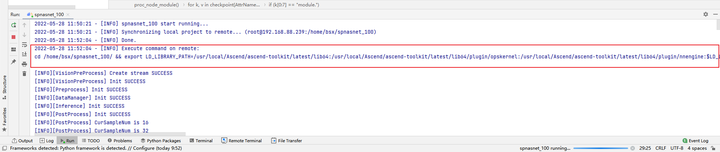
修改后代码运行成功:
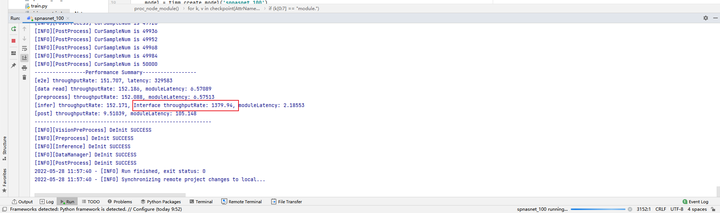
可以获得batch16 310单卡吞吐率为1379.94×4 = 5519.76 fps
9 精度验证
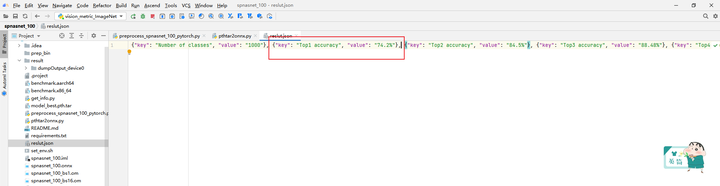
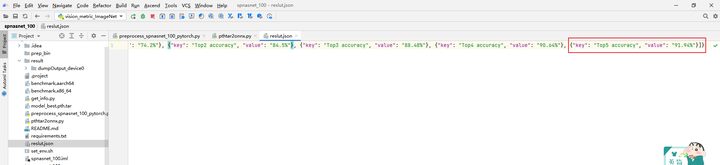
调用vision_metric_ImageNet.py脚本与数据集标签val_label.txt比对,可以获得Accuracy Top5数据,结果保存在result.json中。
第一个参数为生成推理结果所在路径,第二个参数为标签数据,第三个参数为生成结果文件路径,第四个参数为生成结果文件名称。
获得精度数据如下:310 Top1 accuracy为74.2%,Top5 accuracy为91.94%。
从零教你使用MindStudio进行Pytorch离线推理全流程的更多相关文章
- 从零教你如何获取hadoop2.4源码并使用eclipse关联hadoop2.4源码
从零教你如何获取hadoop2.4源码并使用eclipse关联hadoop2.4源码http://www.aboutyun.com/thread-8211-1-1.html(出处: about云开发) ...
- MindStudio模型训练场景精度比对全流程和结果分析
摘要:MindStudio是一套基于华为昇腾AI处理器开发的AI全栈开发平台 本文分享自华为云社区<MindStudio模型训练场景精度比对全流程和结果分析>,作者:yd_24730208 ...
- Git从零教你入门(4):Git服务之 gogs部署安装
Git从零入门系列4: 先看上一篇文章: http://www.51testing.com/index.php?uid-497177-action-viewspace-itemid-3706817 今 ...
- 从零教你在Linux环境下(ubuntu)如何编译hadoop2.4
问题导读: 1.如果获取hadoop src maven包?2.编译hadoop需要装哪些软件?3.如何编译hadoop2.4?扩展:编译hadoop为何安装这些软件? 本文链接 http://ww ...
- 💒 es6 + canvas 开源 盖楼小游戏 完整代码注释 从零教你做游戏(一)
盖楼游戏 一个基于 Canvas 的盖楼游戏 Demo 预览 在线预览地址 (Demo Link) 手机设备可以扫描下方二维码 github https://github.com/bmqb/tower ...
- JAVA RPC (七) 手把手从零教你写一个生产级RPC之client请求
上节说了关于通用请求代理,实际上对spring的bean引用都是通过koalasClientProxy来实现的,那么在代理方法中才是我们实际的发送逻辑,咱们先看一下原生的thrift请求是什么样的. ...
- JAVA RPC (六) 之手把手从零教你写一个生产级RPC之client的代理
首先对于RPC来讲,最主要的无非三点[SERVER IO模型].[序列化协议].[client连接池复用],之前的博客大家应该对thrift有一个大致的了解了,那么我们现在来说一说如何将thrift的 ...
- 使用pytorch构建神经网络的流程以及一些问题
使用PyTorch构建神经网络十分的简单,下面是我总结的PyTorch构建神经网络的一般过程以及我在学习当中遇到的一些问题,期望对你有所帮助. PyTorch构建神经网络的一般过程 下面的程序是PyT ...
- 零基础java的福音!史上最全最精简的学习路线图!
这是一个java系统学习路线,从零基础到项目框架开发,每一个阶段里面内容都标记的很清楚,如果你现在也在学习java,你可以跟着这个系统学习路线学,学完自己可以独立的完成项目框架开发,二线城市拿个7k+ ...
随机推荐
- 29.MySQL高级SQL语句
MySQL高级SQL语句 目录 MySQL高级SQL语句 创建两个表 SELECT DISTINCT WHERE AND OR IN BETWEEN 通配符 LIKE ORDER BY 函数 数学函数 ...
- Python爬虫-正则
介绍: 是 一门全新的语言,一种使用表达式的方式对字符串进行匹配的语法规则 我们抓取到的网页源代码本质上就是一个超长的字符串,想从里面提取内容,用正则再适合不过 优点:速度快.效率高.准确性高 缺点: ...
- Vue回炉重造之router路由(更新中)
安装vue-router npm i vue-router -S 配置1.创建文件夹与文件 创建一个router文件夹,在文件夹中创建两个文件,分别是router.js和routes.js文件.2.编 ...
- CPI教程-异步接口创建及使用
CPI教程-异步接口创建及使用 create by yi 转载请注明出处 先简单介绍一下同步接口和异步接口 什么是同步接口 同步接口的意思就是发送方发送Message后,接口方处理完成后会立刻返回执行 ...
- Tapdata 肖贝贝:实时数据引擎系列(六)-从 PostgreSQL 实时数据集成看增量数据缓存层的必要性
摘要:对于 PostgreSQL 的实时数据采集, 业界经常遇到了包括:对源库性能/存储影响较大, 采集性能受限, 时间回退重新同步不支持, 数据类型较复杂等等问题.Tapdata 在解决 Pos ...
- SLSA 框架与软件供应链安全防护
随着软件供应链攻击浪潮愈演愈烈,Google 发布了一系列指南来确保软件包的完整性,旨在防止影响软件供应链的未经授权的代码修改.新的 Google SLSA 框架(Supply-chain Level ...
- GFS分布式文件系统
一.文件系统简介1.文件系统的组成接口:文件系统接口功能模块(管理.存储的工具):对对象管理里的软件集合对象及属性:(使用此文件系统的消费者)2.文件系统的作用从系统角度来看,文件系统时对文件存储设备 ...
- 如何在CentOS上找出逐渐耗尽磁盘空间的目录和文件
起因 随着系统运行,CentOS空间不断减少,对此非常焦虑,到底磁盘空间被哪些新增文件占用了呢? 分析过程,主要使用du命令,逐层找出消耗空间的目录 1.在根目录下检索一下文件的占用情况,执行du命令 ...
- 自建docker仓库
一.仓库安装 1.系统:CentOS7.9,采用yum安装方式 [root@master ~]# yum install docker-distribution -y ... ... [root@ma ...
- Docker默认桥接网络是如何工作的
1. 启动一个Docker容器 一般来说,我们起一个容器比如一个简单的nginx服务会向这样 docker run -d --rm nginx:XXX OK容器起来了,但是并不能通过宿主机被外面的机器 ...