Add All&shuffle-sort(List)
Add All&shuffle
Collections常用功能
- java.utils.collections是集合工具类,用来对集合进行操作。部分方法如下︰
- public static <T> boolean addAll(Collection<T〉c,T... elements) :往集合中添加一些元素。public static void shuffle(List<?> list)打乱顺序`:打乱集合顺序。
代码演示:
package A_Lian_one.demo15Collections; import java.util.ArrayList;
import java.util.Collections; public class Demo01Collections {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>(); Collections.addAll(list,"a","b","c","d","e"); System.out.println(list); Collections.shuffle(list); System.out.println(list);
}
}
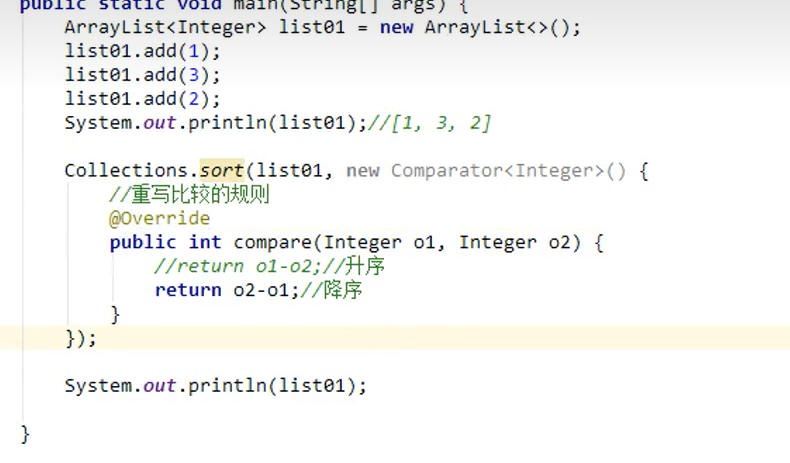
sort(List)
- public static <T> void sort(List<T> list):将集合中元素按照默认规则排序。
- public static〈T> void sort(List<T> list , Comparator<? super T>):将集合中元素按照指定规则排序。
代码演示:
Add All&shuffle-sort(List)的更多相关文章
- Add, remove, shuffle and sort
To deal cards, we would like a method that removes a card from the deck and returns it. The list met ...
- 2.1 shuffle sort(洗牌)
1.目的:将数组以随机的顺序重新排序,类似洗牌的过程 2.用途用于快速排序或者任何以划分为基础的排序中,目的是减少最坏可能性发生的概率. 3.想法1:给数组的每一个元素产生一个随机的数字作为键,然后使 ...
- Spark-1.6.0中的Sort Based Shuffle源码解读
从Spark-1.2.0开始,Spark的Shuffle由Hash Based Shuffle升级成了Sort Based Shuffle.即Spark.shuffle.manager从Hash换成了 ...
- Hadoop-2.2.0中文文档—— MapReduce下一代- 可插入的 Shuffle 和 Sort
简单介绍 可插入的 shuffle 和 sort 功能,同意在shuffle 和 sort 逻辑中用可选择的实现类替换.这个情况的样例是:用一个不是HTTP的应用协议,如RDMA来 shuffle 从 ...
- Spark技术内幕:Sort Based Shuffle实现解析
在Spark 1.2.0中,Spark Core的一个重要的升级就是将默认的Hash Based Shuffle换成了Sort Based Shuffle,即spark.shuffle.manager ...
- Spark Sort Based Shuffle内存分析
分布式系统里的Shuffle 阶段往往是非常复杂的,而且分支条件也多,我只能按着我关注的线去描述.肯定会有不少谬误之处,我会根据自己理解的深入,不断更新这篇文章. 前言 借用和董神的一段对话说下背景: ...
- Spark Shuffle之Sort Shuffle
源文件放在github,随着理解的深入,不断更新,如有谬误之处,欢迎指正.原文链接https://github.com/jacksu/utils4s/blob/master/spark-knowled ...
- Spark技术内幕: Shuffle详解(一)
通过上面一系列文章,我们知道在集群启动时,在Standalone模式下,Worker会向Master注册,使得Master可以感知进而管理整个集群:Master通过借助ZK,可以简单的实现HA:而应用 ...
- Spark记录-Spark性能优化(开发、资源、数据、shuffle)
开发调优篇 原则一:避免创建重复的RDD 通常来说,我们在开发一个Spark作业时,首先是基于某个数据源(比如Hive表或HDFS文件)创建一个初始的RDD:接着对这个RDD执行某个算子操作,然后得到 ...
- Spark源码分析之Sort-Based Shuffle读写流程
一 .概述 我们知道Spark Shuffle机制总共有三种: 1.未优化的Hash Shuffle:每一个ShuffleMapTask都会为每一个ReducerTask创建一个单独的文件,总的文件数 ...
随机推荐
- iptables综合实验: 两个私有网络的互相通迅
环境准备: 主机A IP:192.168.0.6/24 网关改为192.168.0.8 firewallA IP:eth1 192.168.0.8/24 eth0 10.0.0.8/24 删除默认路由 ...
- .NET性能优化-复用StringBuilder
在之前的文章中,我们介绍了dotnet在字符串拼接时可以使用的一些性能优化技巧.比如: 为StringBuilder设置Buffer初始大小 使用ValueStringBuilder等等 不过这些都多 ...
- Go语言核心36讲32
你好,我是郝林,今天我们继续分享原子操作的内容. 我们接着上一篇文章的内容继续聊,上一篇我们提到了,sync/atomic包中的函数可以做的原子操作有:加法(add).比较并交换(compare an ...
- 【云原生 · Kubernetes】Kubernetes容器云平台部署与运维
[题目1]Deployment管理 在master节点/root目录下编写yaml文件nginx-deployment.yaml,具体要求如下: (1)Deployment名称:nginx-deplo ...
- FluentFTP能连接却报未将对象引用设置到对象的实例。
本来项目中用的好好的FTP下载传输,不知道从什么时候开始读取不到了,也上传不了.实际读取的是本地缓存的.因为同事上传不了文件和图片才发现.上源码! #region 下载文件 static byte[] ...
- 【GUI开发案例】用python爬百度搜索结果,并开发成exe桌面软件!
一.背景介绍 你好,我是 @马哥python说 ,一名10年程序猿. 1.1 老版本 之前我开发过一个百度搜索的python爬虫代码,具体如下: [python爬虫案例]用python爬取百度的搜索结 ...
- 春秋云境 CVE-2022-24663复现
靶标介绍: 远程代码执行漏洞,任何订阅者都可以利用该漏洞发送带有"短代码"参数设置为 PHP Everywhere 的请求,并在站点上执行任意 PHP 代码.P.S. 存在常见用户 ...
- sublime text设置build system automatic提示no build system
解决办法: 将: "selector": "source.asm" 改为: "selector": ["source.asm&qu ...
- 数电第三周周结_by_yc
主要内容:Modelsim和Quartus的使用坑点 Modelsim: 新建Project: 在每新建一个verilog文件时,均需要添加一project的独立路径,否则不同文件之间会相互影响! ...
- Linux 基础-文件权限与属性
一,文件类型 1.1,概述 1.2,正规文件(regular file) 1.3,目录(directory) 1.4,链接文件(link) 1.5,设备与装置文件(device) 1.6,资料接口文件 ...