使用加强堆结构解决topK问题
作者:Grey
原文地址: 使用加强堆结构解决topK问题
题目描述
LintCode 550 · Top K Frequent Words II
思路
由于要统计每个字符串的次数,以及字典序,所以,我们需要把用户每次add的字符串封装成一个对象,这个对象中包括了这个字符串和这个字符串出现的次数。
假设我们封装的对象如下:
public class Word {
public String value; // 对应的字符串
public int times; // 对应的字符串出现的次数
public Word(String v, int t) {
value = v;
times = t;
}
}
topk的要求是: 出现次数多的排前面,如果次数一样,字典序小的排前面
很容易想到用有序表+比较器来做。
比较器的规则定义成和topk的要求一样,然后把元素元素加入使用比较器的有序表中,如果要返回topk,直接从这个有序表弹出返回给用户即可。比较器的定义如下:
public class TopKComparator implements Comparator<Word> {
@Override
public int compare(Word o1, Word o2) {
// 次数大的排前面,次数一样字典序在小的排前面
return o1.times == o2.times ? o1.value.compareTo(o2.value) : (o2.times - o1.times);
}
}
有序表配置这个比较器即可
TreeSet<Word> topK = new TreeSet<>(new TopKComparator());
所以topk()方法很简单,只需要从有序表里面把元素拿出来返回给用户即可
public List<String> topk() {
List<String> result = new ArrayList<>();
for (Word word : topK) {
result.add(word.value);
}
return result;
}
时间复杂度 O(K)
以上步骤不复杂,接下来是add的逻辑,add的每次操作都有可能对前面我们设置的topK有序表造成影响,
所以在每次add操作的时候需要有一个机制可以告诉topK这个有序表,需要淘汰什么元素,需要新加哪个元素,让topK这个有序表时时刻刻只存topk个元素,
这样就可以确保topK()方法比较单纯,时间复杂度保持在O(K)
所以接下来的问题是:如何告诉topK这个有序表,需要淘汰什么元素,需要新加哪个元素?
我们可以通过堆来维持一个门槛,堆顶元素表示最先要淘汰的元素,所以堆中的比较策略定为:
次数从小到大,字典序从大到小,这样,堆顶元素永远是:次数相对更少或者字典序相对更大的那个元素。所以如果某个时刻要淘汰一个元素,从堆顶拿出来,然后再到topK这个有序表中查询是否有这个元素,有的话就从topK这个有序表中删除这个元素即可。
private class ThresholdComparator implements Comparator<Word> {
@Override
public int compare(Word o1, Word o2) {
// 设置堆门槛,堆顶元素最先被淘汰
return o1.times == o2.times ? o2.value.compareTo(o2.value) : (o1.times - o2.times);
}
}
如果使用Java自带的PriorityQueue做这个堆,无法实现动态调整堆的功能,因为我们需要把次数增加的字符串(Word)在堆上动态调整,自带的PriorityQueue无法实现这个功能,PriorityQueue只能支持每次新增或者删除一个节点的时候,动态调整堆(
O(logN),但是如果堆中的节点变化了,PriorityQueue无法自动调整成堆结构,所以我们需要实现一个增强堆,用于节点变化的时候可以动态调整堆结构(保持O(logN)复杂度)。
加强堆的核心是增加了一个哈希表,
private Map<Word, Integer> indexMap;
用于存放每个节点所在堆上的位置,在节点变化的时候,可以通过哈希表查出这个节点所在的位置,然后从所在位置进行heapify/heapInsert操作,且这两个操作只会走一个,
这样就动态调整好了这个堆结构,以下resign方法就是完成这个工作
public void resign(Word word) {
int i = indexMap.get(word);
heapify(i);
heapInsert(i);
}
除了这个resign方法,自定义堆中的其他方法和常规的堆没有区别,在每次进行heapify和heapInsert操作的时候,如果涉及到交换两个元素,需要将indexMap中的两个元素的位置也互换
private void swap(int i, int j) {
if (i != j) {
indexMap.put(words[i], j);
indexMap.put(words[j], i);
Word tmp = words[i];
words[i] = words[j];
words[j] = tmp;
}
}
由于自定义堆和有序表topk只存top k个数据,所以TopK结构中还需要一个哈希表来记录所有的字符串出现与否:
private Map<String, Word> map;
自此,TopK结构中的add方法需要的前置条件已经具备,整个add方法的流程如下:
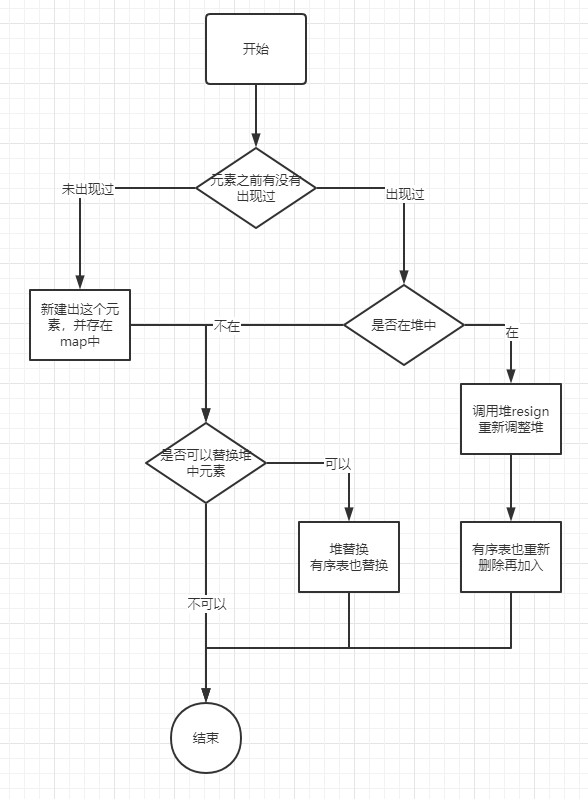
关于复杂度,add方法,时间复杂度O(log K), topk方法,时间复杂度O(K)。
完整代码
class TopK {
private TreeSet<Word> topK;
private Heap heap;
private Map<String, Word> map;
private int k;
public TopK(int k) {
this.k = k;
topK = new TreeSet<>(new TopKComparator());
heap = new Heap(k, new ThresholdComparator());
map = new HashMap<>();
}
public void add(String str) {
if (k == 0) {
return;
}
Word word = map.get(str);
if (word == null) {
// 新增元素
word = new Word(str, 1);
// 是否到达门槛可以替换堆中元素
if (heap.isReachThreshold(word)) {
if (heap.isFull()) {
Word toBeRemoved = heap.poll();
topK.remove(toBeRemoved);
}
heap.add(word);
topK.add(word);
}
} else {
if (heap.contains(word)) {
topK.remove(word);
word.times++;
topK.add(word);
heap.resign(word);
} else {
word.times++;
if (heap.isReachThreshold(word)) {
if (heap.isFull()) {
Word toBeRemoved = heap.poll();
topK.remove(toBeRemoved);
}
heap.add(word);
topK.add(word);
}
}
}
map.put(str, word);
}
public List<String> topk() {
if (k == 0) {
return new ArrayList<>();
}
List<String> result = new ArrayList<>();
for (Word word : topK) {
result.add(word.value);
}
return result;
}
private class Word {
public String value;
public int times;
public Word(String v, int t) {
value = v;
times = t;
}
}
private class TopKComparator implements Comparator<Word> {
@Override
public int compare(Word o1, Word o2) {
// 次数大的排前面,次数一样字典序在小的排前面
return o1.times == o2.times ? o1.value.compareTo(o2.value) : (o2.times - o1.times);
}
}
private class ThresholdComparator implements Comparator<Word> {
@Override
public int compare(Word o1, Word o2) {
// 设置堆门槛,堆顶元素最先被淘汰
return o1.times == o2.times ? o2.value.compareTo(o1.value) : (o1.times - o2.times);
}
}
private class Heap {
private Word[] words;
private Comparator<Word> comparator;
private Map<Word, Integer> indexMap;
public Heap(int k, Comparator<Word> comparator) {
words = new Word[k];
indexMap = new HashMap<>();
this.comparator = comparator;
}
public boolean isEmpty() {
return indexMap.isEmpty();
}
public boolean isFull() {
return indexMap.size() == words.length;
}
public boolean isReachThreshold(Word word) {
if (isEmpty() || indexMap.size() < words.length) {
return true;
} else {
if (comparator.compare(words[0], word) < 0) {
return true;
}
return false;
}
}
public void add(Word word) {
int size = indexMap.size();
words[size] = word;
indexMap.put(word, size);
heapInsert(size);
}
private void heapify(int i) {
int size = indexMap.size();
int leftChildIndex = 2 * i + 1;
while (leftChildIndex < size) {
Word weakest = leftChildIndex + 1 < size
? (comparator.compare(words[leftChildIndex], words[leftChildIndex + 1]) < 0
? words[leftChildIndex]
: words[leftChildIndex + 1])
: words[leftChildIndex];
if (comparator.compare(words[i], weakest) < 0) {
break;
}
int weakestIndex = weakest == words[leftChildIndex] ? leftChildIndex : leftChildIndex + 1;
swap(weakestIndex, i);
i = weakestIndex;
leftChildIndex = 2 * i + 1;
}
}
public void resign(Word word) {
int i = indexMap.get(word);
heapify(i);
heapInsert(i);
}
private void heapInsert(int i) {
while (comparator.compare(words[i], words[(i - 1) / 2]) < 0) {
swap(i, (i - 1) / 2);
i = (i - 1) / 2;
}
}
public boolean contains(Word word) {
return indexMap.containsKey(word);
}
public Word poll() {
Word result = words[0];
swap(0, indexMap.size() - 1);
indexMap.remove(result);
heapify(0);
return result;
}
private void swap(int i, int j) {
if (i != j) {
indexMap.put(words[i], j);
indexMap.put(words[j], i);
Word tmp = words[i];
words[i] = words[j];
words[j] = tmp;
}
}
}
}
更多
参考资料
使用加强堆结构解决topK问题的更多相关文章
- 基于PriorityQueue(优先队列)解决TOP-K问题
TOP-K问题是面试高频题目,即在海量数据中找出最大(或最小的前k个数据),隐含条件就是内存不够容纳所有数据,所以把数据一次性读入内存,排序,再取前k条结果是不现实的. 下面我们用简单的Java8代码 ...
- Java最小堆解决TopK问题
TopK问题是指从大量数据(源数据)中获取最大(或最小)的K个数据. TopK问题是个很常见的问题:例如学校要从全校学生中找到成绩最高的500名学生,再例如某搜索引擎要统计每天的100条搜索次数最多的 ...
- Java解决TopK问题(使用集合和直接实现)
在处理大量数据的时候,有时候往往需要找出Top前几的数据,这时候如果直接对数据进行排序,在处理海量数据的时候往往就是不可行的了,而且在排序最好的时间复杂度为nlogn,当n远大于需要获取到的数据的时候 ...
- 堆结构的优秀实现类----PriorityQueue优先队列
之前的文章中,我们有介绍过动态数组ArrayList,双向队列LinkedList,键值对集合HashMap,树集TreeMap.他们都各自有各自的优点,ArrayList动态扩容,数组实现查询非常快 ...
- 如何解决TOP-K问题
前言:最近在开发一个功能:动态展示的订单数量排名前10的城市,这是一个典型的Top-k问题,其中k=10,也就是说找到一个集合中的前10名.实际生活中Top-K的问题非常广泛,比如:微博热搜的前100 ...
- java实现堆结构
一.前言 之前用java实现堆结构,一直用的优先队列,但是在实际的面试中,可能会要求用数组实现,所以还是用java老老实实的实现一遍堆结构吧. 二.概念 堆,有两种形式,一种是大根堆,另一种是小根堆. ...
- Libheap:一款用于分析Glibc堆结构的GDB调试工具
Libheap是一个用于在Linux平台上分析glibc堆结构的GDB调试脚本,使用Python语言编写. 安装 Glibc安装 尽管Libheap不要求glibc使用GDB调试支持和 ...
- 分治思想--快速排序解决TopK问题
----前言 最近一直研究算法,上个星期刷leetcode遇到从两个数组中找TopK问题,因此写下此篇,在一个数组中如何利用快速排序解决TopK问题. 先理清一个逻辑解决TopK问题→快速排序→递 ...
- 【pwn】学pwn日记(堆结构学习)
[pwn]学pwn日记(堆结构学习) 1.什么是堆? 堆是下图中绿色的部分,而它上面的橙色部分则是堆管理器 我们都知道栈的从高内存向低内存扩展的,而堆是相反的,它是由低内存向高内存扩展的 堆管理器的作 ...
随机推荐
- Java将彩色PDF转为灰度
本文以Java代码为例介绍如何实现将彩色PDF文件转为灰度(黑白)的PDF文件,即:将PDF文档里面的彩色图片或者文字等通过调用PdfGrayConverter.toGrayPdf()方法转为文档页面 ...
- 记录一次SQL函数和优化的问题
一.前言 上次在年前快要放假的时候记录的一篇安装SSL证书的内容,因为当时公司开始居家办公了,我也打算回个家 毕竟自己在苏州这半年一个人也是很想家的,所以就打算年过完来重新写博客.不巧的是,当时我2月 ...
- Termux镜像在阿里云镜像站首发上线
镜像下载.域名解析.时间同步请点击阿里云开源镜像站 简介 Termux 是 Android 平台上的一个终端模拟器,它将众多 Linux 上运行的软件和工具近乎完美的移植到了手机端. 无需任何复杂的安 ...
- ansible 四常用模块
常用模块 Ansible默认提供了很多模块来供我们使用.在Linux中,我们可以通过 ansible-doc -l 命令查看到当前Ansible支持哪些模块,通过 ansible-doc -s [模块 ...
- 深度优先算法--对DFS的一些小小的总结(一)
提到DFS,我们首先想到的是对树的DFS,例如下面的例子:求二叉树的深度 int TreeDepth(BinaryTreeNode* root){ if(root==nullptr)return 0; ...
- 简单面试前算法一览java
1.排序 冒泡,快速排序 2.查找 二分查找 3.链表 翻转链表 合并链表 是否有环 b. 快慢指针 public class QuickSort { public static void qui ...
- 什么是Hystrix?
防雪崩利器,具备服务降级,服务熔断,依赖隔离,监控(Hystrix Dashboard)服务降级:双十一 提示 哎哟喂,被挤爆了. app秒杀 网络开小差了,请稍后再试.优先核心服务,非核心服务不可用 ...
- volatile 有什么用?能否用一句话说明下 volatile 的应用场景?
volatile 保证内存可见性和禁止指令重排. volatile 用于多线程环境下的单次操作(单次读或者单次写).
- Linux如何查看某个端口是否被占用
1.netstat -anp |grep 端口号 2.netstat -nultp(此处不用加端口号) 3.netstat -anp |grep 82 查看82端口的使用情况
- Python学习--21天Python基础学习之旅(Day01、Day02)
21天的python基础学习,使用<Python从入门到实践>,并且需要手敲书中的code,以下为整个学习过程的记录. Day01: 安装python时要选择复选框 Add Python ...