如何解决TOP-K问题
前言:最近在开发一个功能:动态展示的订单数量排名前10的城市,这是一个典型的Top-k问题,其中k=10,也就是说找到一个集合中的前10名。实际生活中Top-K的问题非常广泛,比如:微博热搜的前100名、抖音直播的小时榜前50名、百度热搜的前10条、博客园点赞最多的blog前10名,等等如何解决这类问题呢?初步的想法是将这个数据集合排序,然后直接取前K个返回。这样解法可以,但是会存在一个问题:排序了很多不需要去排序的数据,时间复杂度过高.假设有数据100万,对这个集合进行排序需要很长的时间,即便使用快速排序,时间复杂度也是O(nlogn),那么这个问题如何解决呢?解决方法就是以空间换时间,使用优先级队列
目录
一: 认识PriorityQueue
二:利用PriorityQueue解决topk问题
三:总结
一:认识PriorityQueue
1.1:PriorityQueue位于java.util包下,继承自Collection,因此它具有集合的属性,并且继承自Queue队列,拥有add/offer/poll/peek等一系列操作元素的能力,它的默认大小是11,底层使用Object[] 来保存元素,数组的话肯定会有扩容,当添加元素的时候大小超过数组的容量,就会扩容,扩容的大小为原数组的大小加上,如果元素的数量小于64,则每次加2,如果大于64,则每次增加一半的容量。
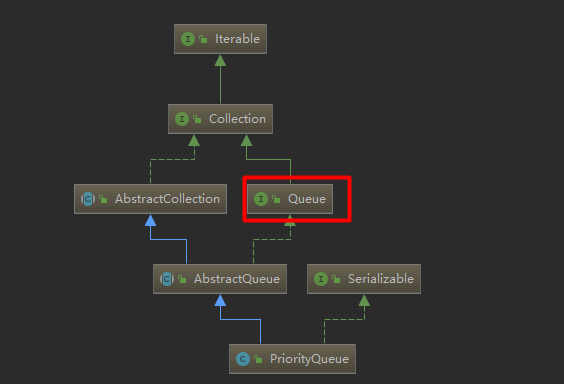
1.2:PriorityQueue的构造方法
public PriorityQueue(Comparator<? super E> comparator) {
this(DEFAULT_INITIAL_CAPACITY, comparator);
}
public PriorityQueue(int initialCapacity,
Comparator<? super E> comparator) {
// Note: This restriction of at least one is not actually needed,
// but continues for 1.5 compatibility
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}
比较常用的就是这两个构造方法,其中第一个构造方法中需要构造一个比较器,第二个构造方法添加初始容量和比较器,比较器可以自定义任何元素的优先级,按照需要增加元素的优先级展示
1.3:PriorityQueue的常用API
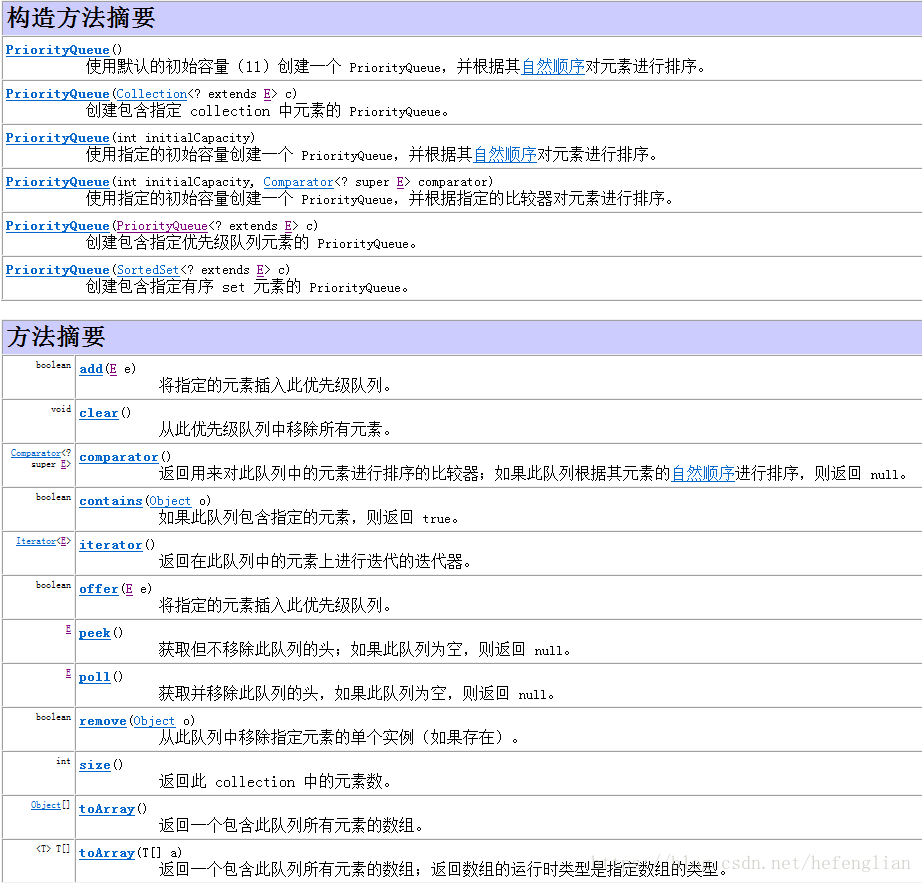
1.3.1:offer方法和add方法用于添加元素,本质上offer方法和add方法是相同的:
public boolean add(E e) {
return offer(e);
}
offer方法主要步骤就是判空、扩容、添加元素,添加元素的话,siftup方法里会根据构造方法,如果有比较器就进行比较,没有比较器的话就给元素赋予比较能力,并且根据构造的大小,也就是
initialCapacity进行比较,如果比较器的compare方法不符合定义的规则,直接break;符合的话会给数组的元素进行赋值
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);
size = i + 1;
if (i == 0)
queue[0] = e;
else
siftUp(i, e);
return true;
}
1.3.2:poll方法和peek方法都是返回头元素,不同之处在于poll方法会返回头顶元素并且移除元素,peek方法不会移除头顶元素:
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
E result = (E) queue[0];
E x = (E) queue[s];
queue[s] = null;
if (s != 0)
siftDown(0, x);
return result;
}
public E peek() {
return (size == 0) ? null : (E) queue[0];
}
二:PriorityQueue解决问题
2.1:数组的前K大值

代码:
import java.util.PriorityQueue;
public class TopK {
//找出前k个最大数,采用小顶堆实现
public static int[] findKMax(int[] nums, int k) {
PriorityQueue<Integer> pq = new PriorityQueue<>(k);//队列默认自然顺序排列,小顶堆,不必重写compare
for (int num : nums) {
if (pq.size() < k) {
pq.offer(num);
//如果堆顶元素 < 新数,则删除堆顶,加入新数入堆,保持堆中存储着大值
} else if (pq.peek() < num) {
pq.poll();
pq.offer(num);
}
}
int[] result = new int[k];
for (int i = 0; i < k && !pq.isEmpty(); i++) {
result[i] = pq.poll();
}
return result;
}
}
测试:
public static void main(String[] args) {
int[] arr = new int[]{1, 6, 2, 3, 5, 4, 8, 7, 9};
System.out.println(Arrays.toString(findKMax(arr, 3)));
}
//输出:

优先级队列是如何解决这个问题的呢?
PriorityQueue默认是小顶堆,那么什么是小顶堆?什么是大顶堆?假设有3、6、8三个数,需要存储在优先级队列里,画个图大家理解下:
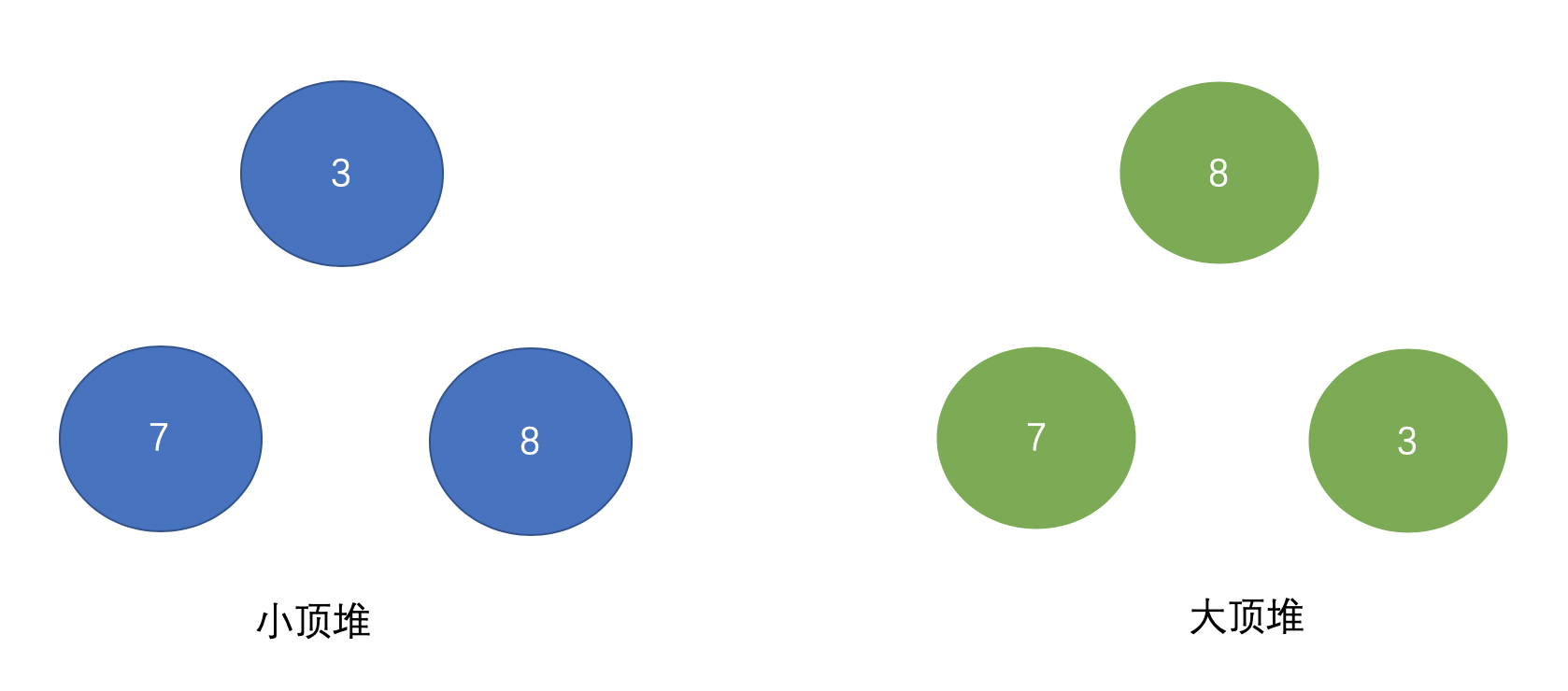
可以看出小顶堆的头顶元素存储着整个数据集合中数字最小的元素,而大顶堆存储着整个数据集合中数字最大的元素,也就是一个按照升序排列,一个按照降序排列:
//小顶堆的构建方法:
PriorityQueue<Integer> queue = new PriorityQueue<>(k);
//这种写法等价于:
PriorityQueue<Integer> queue = new PriorityQueue<>(k, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1-o2;
}
});
//同时等价于(lamda表达式的写法)
PriorityQueue<Integer> queue = new PriorityQueue<>(k, (o1, o2) -> o1-o2); //大顶堆的构建方法:
PriorityQueue<Integer> queue = new PriorityQueue<>(k, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
拿测试用例这个例子来说:
构建的是指定容量的小顶堆,因此每次queue.peek()返回的是最小的数字,在遍历数组的过程中,如果遇到比该数字大的元素就将最小的数字poll(移除掉),然后将较大的元素添加到堆中,在添加进去堆中的时候,堆同时会按照优先级比较,将最小的元素再次放到堆顶,这样的做法就是会一直保持堆中的元素是相对较大的,同时堆顶元素是堆中最小的。
按照测试用例给出的例子,{1, 6, 2, 3, 5, 4, 8, 7, 9} 优先级队列将会是这样转变的:(注意:本质上优先级队列的实现方式是数组,这里只是用二叉树的方式表现出来)
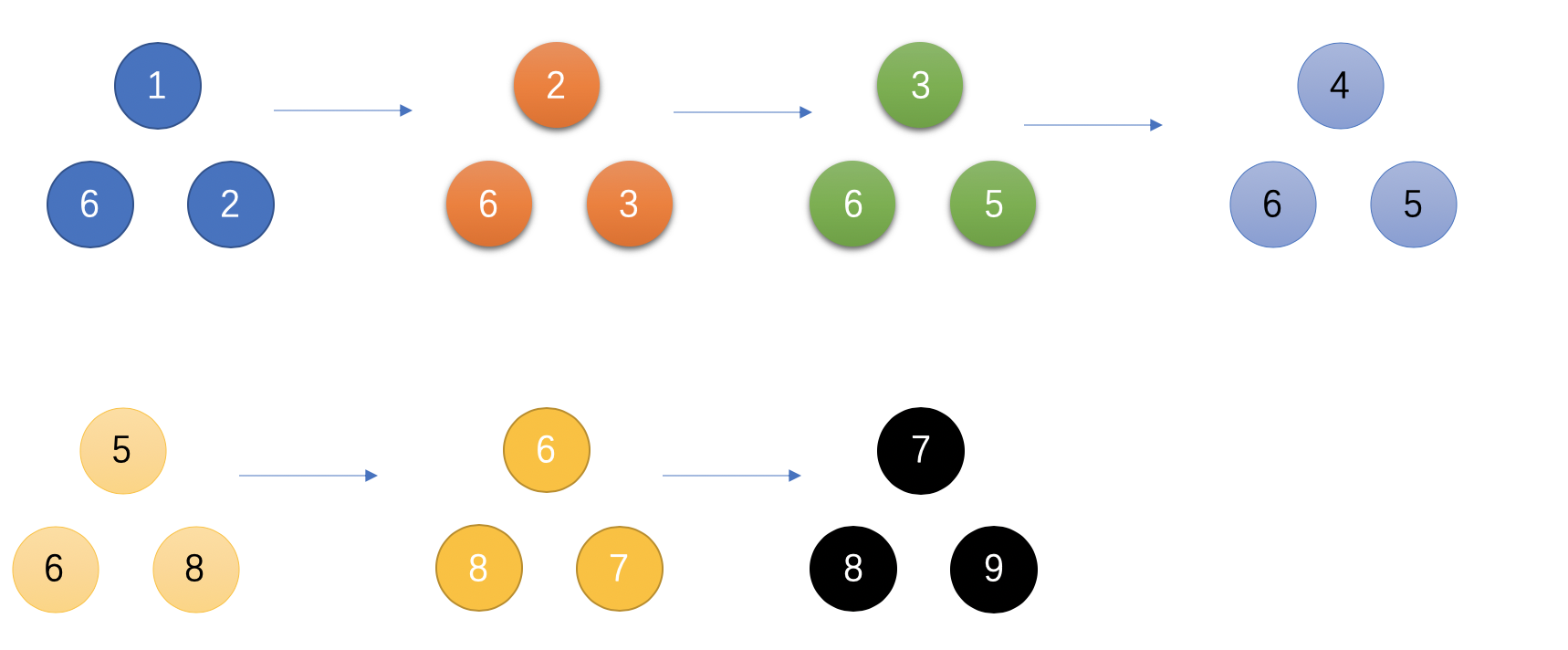
假如该题换个角度,求出现频率最低的元素怎么做呢?
相信你根据上面的讲述应该也明白了:直接构建一个大顶堆,这样元素最大的值在堆顶,每次去和数组的元素的值去做比较,只要堆顶元素比数组的值小,就将堆顶元素poll出来,然后将数组的值添加进去,这样就可以一直保持集合数组中一直是最小的k个数字。
2.2:前k个高频元素

当k = 1 时问题很简单,线性时间内就可以解决,只需要用哈希表维护元素出现频率,每一步更新最高频元素即可。当 k > 1 就需要一个能够根据出现频率快速获取元素的数据结构,这里就需要用到优先队列
首先建立一个元素值对应出现频率的哈希表,使用 HashMap来统计,然后构建优先级队列,这里依旧是构建小顶堆,不过因为该题是计算元素出现的频率,因此我们需要将每个元素的频率值做对比,
需要重写优先级队列的comparator,需要手工填值:这个步骤需要 O(N)O(N) 时间其中 NN 是列表中元素个数。
第二步建立堆,堆中添加一个元素的复杂度是 O(\log(k))O(log(k)),要进行 NN 次复杂度是 O(N)O(N)。
最后一步是输出结果,复杂度为 O(k\log(k))O(klog(k)):
public int[] topK(int[] nums, int k) {
//统计字符出现的频率的map
Map<Integer, Integer> count = new HashMap();
for (int num : nums) {
count.put(num, count.getOrDefault(num, 0) + 1);
}
//根据出现频率的map来构建k个元素的优先级队列
PriorityQueue<Integer> heap =
new PriorityQueue<>(k, (o1, o2) -> count.get(o1) - count.get(o2));
for (int n : count.keySet()) {
heap.add(n);
if (heap.size() > k)
heap.poll();
}
int[] result = new int[heap.size()];
for (int i = 0; i < result.length; i++) {
result[i] = heap.poll();
}
return result;
}
测试:
public static void main(String[] args) {
int[] nums = {1, 1, 1, 3, 5, 6, 5, 6, 5, 4, 7, 8};
int[] res = new TOPK().topK(nums, 3);
System.out.println(Arrays.toString(res));
}
//输出

对于这样的问题需要先对原数组进行处理,比如在计算前3频率这个问题上,我们需要先计算数组中数字出现的频率,然后维护一个哈希表用来存储元素的频率。对于类似问题:微博热搜的前10名,那么肯定需要统计搜索频次,抖音小时榜前10名,那么肯定要统计要计算时段的观看人数,优先队列只不过是一个存储K元素的一个容器,它不负责统计,只负责维护一个K元素的最大或者最小堆顶,对于数据采用什么样的优先级顺序需要自定义。
三:总结
本篇博客主要介绍了我们在实际中遇见的TOP-K问题有哪些,以及优先级队列PriorityQueue的基本原理介绍,接着由易到难的讲解了如何通过优先级队列PriorityQueue来解决TOP-k问题,这两个问题都比较经典。对于理解优先级队列的含义、以及为什么它能解决该问题,想明白这点很重要。希望大家能够做到举一反三,下次面对同等问题的时候,能顺序解决。起码棘手的topk问题对于我们来说,有个PriorityQueue这个神兵利器,就显得很简单easy咯
最后: 如果对学习java有兴趣可以加入群:618626589,本群旨在打造无培训广告、无闲聊扯皮、无注水斗图的纯技术交流群,群里每天会分享有价值的问题和学习资料,欢迎各位随时加入~
如何解决TOP-K问题的更多相关文章
- 优先队列PriorityQueue实现 大小根堆 解决top k 问题
转载:https://www.cnblogs.com/lifegoesonitself/p/3391741.html PriorityQueue是从JDK1.5开始提供的新的数据结构接口,它是一种基于 ...
- 优先队列实现 大小根堆 解决top k 问题
摘于:http://my.oschina.net/leejun2005/blog/135085 目录:[ - ] 1.认识 PriorityQueue 2.应用:求 Top K 大/小 的元素 3 ...
- Top K问题的两种解决思路
Top K问题在数据分析中非常普遍的一个问题(在面试中也经常被问到),比如: 从20亿个数字的文本中,找出最大的前100个. 解决Top K问题有两种思路, 最直观:小顶堆(大顶堆 -> 最小1 ...
- Top k问题(线性时间选择算法)
问题描述:给定n个整数,求其中第k小的数. 分析:显然,对所有的数据进行排序,即很容易找到第k小的数.但是排序的时间复杂度较高,很难达到线性时间,哈希排序可以实现,但是需要另外的辅助空间. 这里我提供 ...
- 如何解决海量数据的Top K问题
1. 问题描述 在大规模数据处理中,常遇到的一类问题是,在海量数据中找出出现频率最高的前K个数,或者从海量数据中找出最大的前K个数,这类问题通常称为“top K”问题,如:在搜索引擎中,统计搜索最热门 ...
- 大数据热点问题TOP K
1单节点上的topK (1)批量数据 数据结构:HashMap, PriorityQueue 步骤:(1)数据预处理:遍历整个数据集,hash表记录词频 (2)构建最小堆:最小堆只存k个数据. 时间复 ...
- 经典面试问题: Top K 之 ---- 海量数据找出现次数最多或,不重复的。
作者:林冠宏 / 指尖下的幽灵 掘金:https://juejin.im/user/587f0dfe128fe100570ce2d8 博客:http://www.cnblogs.com/linguan ...
- 程序员编程艺术:第三章续、Top K算法问题的实现
程序员编程艺术:第三章续.Top K算法问题的实现 作者:July,zhouzhenren,yansha. 致谢:微软100题实现组,狂想曲创作组. 时间:2011年05月08日 ...
- 海量数据处理 - 10亿个数中找出最大的10000个数(top K问题)
前两天面试3面学长问我的这个问题(想说TEG的3个面试学长都是好和蔼,希望能完成最后一面,各方面原因造成我无比想去鹅场的心已经按捺不住了),这个问题还是建立最小堆比较好一些. 先拿10000个数建堆, ...
- top k问题
1.top k问题 在海量数据处理中,经常会遇到的一类问题:在海量数据中找出出现频率最高的前k个数,或者从海量数据中找出最大的前k个数,这类问题通常被称为top K问题.例如,在搜索引擎中,统计搜索最 ...
随机推荐
- C# winform 学习(二)
目标: 1.ADONET简介 2.Connection对象 3.Command对象 4.DataReader对象 准备工作:创建mhys数据库及员工表 代码如下: create database mh ...
- Java实现 LeetCode 650 只有两个键的键盘(递归 || 数学)
650. 只有两个键的键盘 最初在一个记事本上只有一个字符 'A'.你每次可以对这个记事本进行两种操作: Copy All (复制全部) : 你可以复制这个记事本中的所有字符(部分的复制是不允许的). ...
- Java实现 LeetCode 336 回文对
336. 回文对 给定一组唯一的单词, 找出所有不同 的索引对(i, j),使得列表中的两个单词, words[i] + words[j] ,可拼接成回文串. 示例 1: 输入: ["abc ...
- Java实现 LeetCode 94 二叉树的中序遍历
94. 二叉树的中序遍历 给定一个二叉树,返回它的中序 遍历. 示例: 输入: [1,null,2,3] 1 2 / 3 输出: [1,3,2] 进阶: 递归算法很简单,你可以通过迭代算法完成吗? / ...
- Java实现字符串转换成整数
1 问题描述 输入一个由数字组成的字符串,请把它转换成整数并输出.例如,输入字符串"123",输出整数123. 请写出一个函数实现该功能,不能使用库函数. 2 解决方案 解答本问题 ...
- java代码(10) ---Java8 Map中的computeIfAbsent方法
Map中的computeIfAbsent方法 一.案例说明 1.概述 在JAVA8的Map接口中,增加了一个computeIfAbsent,此方法签名如下: public V computeIfAbs ...
- mac下使用VMVARE安装win10虚拟机的一些坑
最近Mac上安装windows踩到了几个坑: 坑一:启动虚拟机后,提示找不到CD-ROM中找不到对应的ISO文件 硬盘格式请选择 在虚拟机->设置中选择启动磁盘为CD_ROM,然后重新启动. 坑 ...
- InstallShield 2015 Limited Edition 打包教程
InstallShield 2015 Limited Edition 打包教程 右键解决方案,新增项目,选择其他项目类型,安装和部署. InstallShield2015可以免费使用,但需要下载.安装 ...
- 程序员实用JDK小工具归纳,工作用得到
在JDK的安用装目录bin下,有一些有非常实用的小工具,可用于分析JVM初始配置.内存溢出异常等问题,我们接下来将对些常用的工具进行一些说明. JDK小工具简介 在JDK的bin目录下面有一些小工具, ...
- 深度学习在高德ETA应用的探索与实践
1.导读 驾车导航是数字地图的核心用户场景,用户在进行导航规划时,高德地图会提供给用户3条路线选择,由用户根据自身情况来决定按照哪条路线行驶. 同时各路线的ETA(estimated time of ...