Kafka生成消息时的3种分区策略
摘要:KafkaProducer在发送消息的时候,需要指定发送到哪个分区, 那么这个分区策略都有哪些呢?
本文分享自华为云社区《Kafka生产者3中分区分配策略》,作者:石臻臻的杂货铺。
KafkaProducer在发送消息的时候,需要指定发送到哪个分区, 那么这个分区策略都有哪些呢?我们今天来看一下
使用分区策略的配置:

1. DefaultPartitioner 默认分区策略
全路径类名:org.apache.kafka.clients.producer.internals.DefaultPartitioner
- 如果消息中指定了分区,则使用它
- 如果未指定分区但存在key,则根据序列化key使用murmur2哈希算法对分区数取模。
- 如果不存在分区或key,则会使用粘性分区策略,关于粘性分区请参阅 KIP-480。
粘性分区Sticky Partitioner
为什么会有粘性分区的概念?
首先,我们指定,Producer在发送消息的时候,会将消息放到一个ProducerBatch中, 这个Batch可能包含多条消息,然后再将Batch打包发送。关于这一块可以看看我之前的文章 图解Kafka Producer 消息缓存模型。
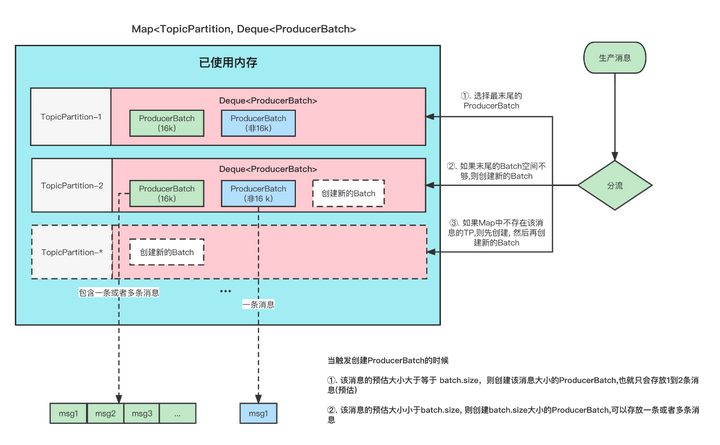
这样做的好处就是能够提高吞吐量,减少发起请求的次数。
但是有一个问题就是, 因为消息的发送它必须要你的一个Batch满了或者linger.ms时间到了,才会发送。如果生产的消息比较少的话,迟迟难以让Batch塞满,那么就意味着更高的延迟。
在之前的消息发送中,就将消息轮询到各个分区的, 本来消息就少,你还给所有分区遍历的分配,那么每个ProducerBatch都很难满足条件。
那么假如我先让一个ProducerBatch塞满了之后,再给其他的分区分配是不是可以降低这个延迟呢?
详细的可以看看下面这张图
这张图的前提是:
Topic1 有3分区, 此时给Topic1 发9条无key的消息, 这9条消息加起来都不超过batch.size .
那么以前的分配方式和粘性分区的分配方式如下
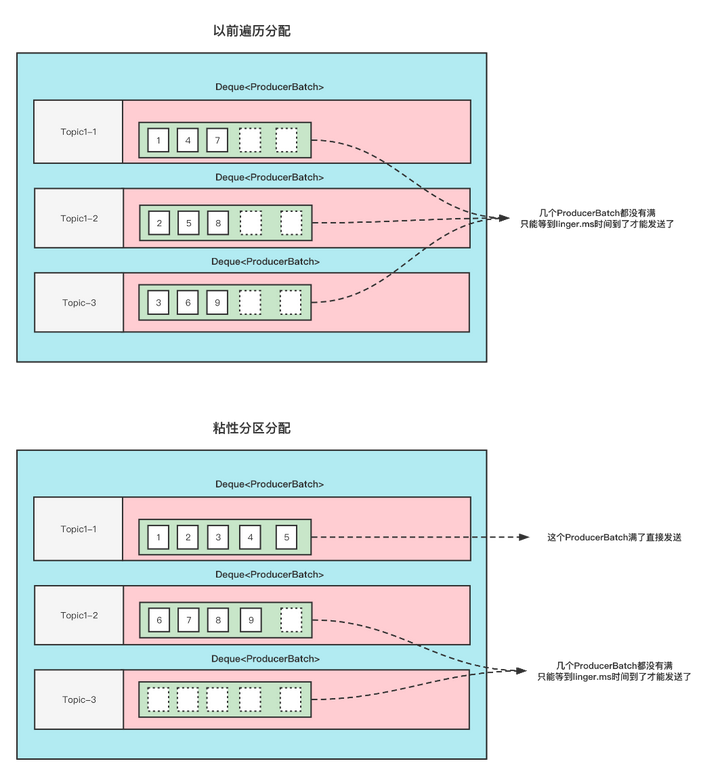
可以看到,使用粘性分区之后,至少是先把一个Batch填满了发送然后再去填充另一个Batch。不至于向之前那样,虽然平均分配了,但是导致一个Batch都没有放满,不能立即发送。这不就增大了延迟了吗(只能通过linger.ms时间到了才发送)
划重点:
- 当一个Batch发送之后,需要选择一个新的粘性分区的时候
①. 可用分区<1 ;那么选择分区的逻辑是在所有分区中随机选择。
②. 可用分区=1; 那么直接选择这个分区。
③. 可用分区>1 ; 那么在所有可用分区中随机选择。 - 当选择下一个粘性分区的时候,不是按照分区平均的原则来分配。而是随机原则(当然不能跟上一次的分区相同)
例如刚刚发送到的Batch是 1号分区,等Batch满了,发送之后,新的消息可能会发到2或者3, 如果选择的是2,等2的Batch满了之后,下一次选择的Batch仍旧可能是1,而不是说为了平均,选择3分区。
2.UniformStickyPartitioner 纯粹的粘性分区策略
全路径类名:org.apache.kafka.clients.producer.internals.UniformStickyPartitioner
他跟DefaultPartitioner 分区策略的唯一区别就是。
DefaultPartitionerd 如果有key的话,那么它是按照key来决定分区的,这个时候并不会使用粘性分区
UniformStickyPartitioner 是不管你有没有key, 统一都用粘性分区来分配。
3. RoundRobinPartitioner 分区策略
全路径类名:org.apache.kafka.clients.producer.internals.RoundRobinPartitioner
- 如果消息中指定了分区,则使用它
- 将消息平均的分配到每个分区中。
- 与key无关
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (!availablePartitions.isEmpty()) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
}
上面是具体代码。有个地方需要注意;
- 当可用分区是0的话,那么就是遍历的是所有分区中的。
- 当有可用分区的话,那么遍历的是所有可用分区的。
Kafka生成消息时的3种分区策略的更多相关文章
- Kafka分区策略
Kafka分区策略 所谓分区策略是决定生产者将消息发送到哪个分区的算法.Kafka 为我们提供了默认的分区策略,同时它也支持你自定义分区策略. 常见的分区策略包含以下几种:轮询策略.随机策略 .按消息 ...
- cassandra框架模型之一——Colum排序,分区策略 Token,Partitioner bloom-filter,HASH
转自:http://asyty.iteye.com/blog/1202072 一.Cassandra框架二.Cassandra数据模型 Colum / Colum Family, SuperColum ...
- kafka的topic和分区策略——log entry和消息id索引文件
Topic在逻辑上可以被认为是一个在的queue,每条消费都必须指定它的topic,可以简单理解为必须指明把这条消息放进哪个queue里. 为了使得Kafka的吞吐率可以水平扩展,物理上把topic分 ...
- 开发测试时给 Kafka 发消息的 UI 发送器――Mikasa
开发测试时给 Kafka 发消息的 UI 发送器――Mikasa 说来话长,自从入了花瓣,整个人就掉进连环坑了. 后端元数据采集是用 Storm 来走拓扑流程的,又因为 @Zola 不是很喜欢 Jav ...
- Kafka的消息格式
Commit Log Kafka储存消息的文件被它叫做log,按照Kafka文档的说法是: Each partition is an ordered, immutable sequence of me ...
- golang实现kafka的消息推送
Kafka的安装与启动 kafka中涉及的名词 消息记录:由一个key,一个value和一个时间戳构成,消息最终存储在主题下的分区中,记录在生产中称为生产者记录,在消费者中称为消费记录.Kafka集群 ...
- Apache Kafka 企业级消息队列
1.大纲 了解 Apache Kafka是什么 掌握Apache Kafka的基本架构 搭建Kafka集群 掌握操作集群的两种方式 了解Apache Kafka高级部分的内容 2.消息系统的作用是什么 ...
- RabbitMQ 和 Kafka 的消息可靠性对比
RabbitMQ和Kafka都提供持久的消息保证.两者都提供至少一次和至多一次的保证,另外,Kafka在某些限定情况下可以提供精确的一次(exactly-once)保证. 让我们首先理解一下上述术语的 ...
- Kafka——分布式消息系统
Kafka——分布式消息系统 架构 Apache Kafka是2010年12月份开源的项目,采用scala语言编写,使用了多种效率优化机制,整体架构比较新颖(push/pull),更适合异构集群. 设 ...
随机推荐
- bzoj4241/AT1219 历史研究(回滚莫队)
bzoj4241/AT1219 历史研究(回滚莫队) bzoj它爆炸了. luogu 题解时间 我怎么又在做水题. 就是区间带乘数权众数. 经典回滚莫队,一般对于延长区间简单而缩短区间难的莫队题可以考 ...
- Golang中常用的代码优化点
Golang中常用的代码优化点 大家好,我是轩脉刃. 这篇想和大家聊一聊golang的常用代码写法.在golang中,如果大家不断在一线写代码,一定多多少少会有一些些代码的套路和经验.这些经验是代表你 ...
- 『忘了再学』Shell基础 — 5、Bash基本功能(命令的别名和常用快捷键)
目录 1.给命令设置别名 (1)设置别名的命令格式 (2)命令别名永久生效 (3)别名的优先级 2.Bash常用快捷键 1.给命令设置别名 Linux系统的命令别名我们之前已经说过了,这里再过一边. ...
- @Autowired 注解?
@Autowired 注解提供了更细粒度的控制,包括在何处以及如何完成自动装配.它的用法和@Required一样,修饰setter方法.构造器.属性或者具有任意名称和/或多个参数的PN方法.
- Vue部署到云服务器时,访问Nginx代理出现We're sorry but books doesn't work properly without JavaScript enabled. Please enable it to continue.
出现这个的原因,我这边的是Nginx的问题,因为没有匹配到静态文件的原因 第一个location是始终将访问的url请求定向到 index.html这个主页面 第二个location块是将index. ...
- 一个 Redis 实例最多能存放多少的 keys?List、Set、 Sorted Set 他们最多能存放多少元素?
理论上 Redis 可以处理多达 232 的 keys,并且在实际中进行了测试,每个实 例至少存放了 2 亿 5 千万的 keys.我们正在测试一些较大的值.任何 list.set. 和 sorted ...
- 学习Redis(一)
一.NoSQL 1.NoSql介绍 1.not only SQL,非关系型数据库,它能解决常规数据库的并发.IO与性能的瓶颈 2.解决以下问题: ① 对数据库的高并发读写需求 ② 大数据的高效存储和访 ...
- VMware ESXi安装NVIDIA GPU显卡硬件驱动和配置vGPU
一.驱动软件准备:从nvidia网站下载驱动,注意,和普通显卡下载驱动地址不同. 按照ESXi对应版本不同下载不同的安装包.安装包内含ESXi主机驱动和虚拟机驱动. GPU显卡和物理服务器兼容查询:( ...
- RESTful API/Web API
Microsoft REST API Guidelines Are Not RESTful White House Web API Standards Microsoft REST API Guide ...
- 自己给idea下载Scala插件
场景:有时候在idea上直接下载的scala可能因为太新所以有bug,需要手动下载插件 经验:自己下载完之后发现比较老的版本idea根本不让你装,只能装一些跟idea上推荐的scala相近的版本,感觉 ...