GC plan_phase二叉树挂接的一个算法
楔子
在看GC垃圾回收plan_phase的时候,发现了一段特殊的代码,仔细研究下得知,获取当前数字bit位里面为1的个数。
通过这个bit位为1的个数(count),来确定挂接当前二叉树子节点的一个地方。
算法
size_t logcount (size_t word)
{
//counts the number of high bits in a 16 bit word.
assert (word < 0x10000);
size_t count;
count = (word & 0x5555) + ( (word >> 1 ) & 0x5555);
count = (count & 0x3333) + ( (count >> 2) & 0x3333);
count = (count & 0x0F0F) + ( (count >> 4) & 0x0F0F);
count = (count & 0x00FF) + ( (count >> 8) & 0x00FF);
return count;
}
counts the number of high bits in a 16 bit word.这一段英文注释很有误导性,它的意思翻一下大致是:获取当前16位字里面的高位bit数。
如果按照这个理解,基本上不知道这个logcount函数是干嘛的。
但实际上它做的事情非常简单。
举个例子:
5的二进制:0101,那么经过logcount函数计算之后,返回值为2。因为5的二进制里面有两个1。
以此类推,6返回2,7返回3,8返回1。
背景
GC垃圾回收的计划阶段,当plan_phase构建二叉树的时候,需要区分根节点,左子节点,和右子节点。新加入的新节点作为根节点,新节点的左子节点(G)就是上一个根节点(C)的右子节点。新节点本身又作为上一个根节点(C)的右子节点。
图:
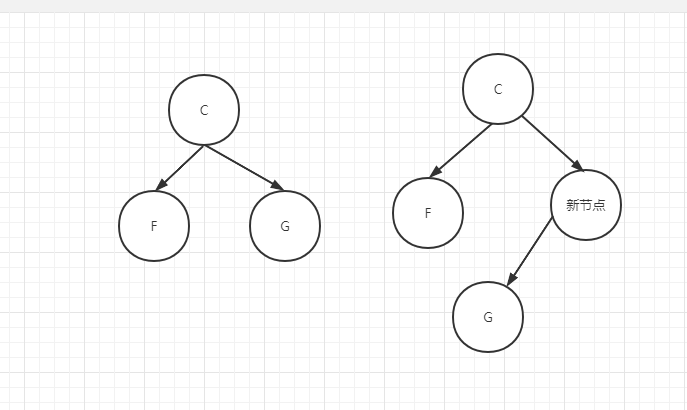
上面这个算法的作用就是,把新加入的新节点挂接到二叉树深度N(logcount返回值)的地方。
图两个二叉树,分别深度为2和3。logcount返回其参数bit位里面为1的个数,作为二叉树的深度。然后进行一个挂接。其行为逻辑是二叉树构建的核心。
整体
GC计划阶段(plan_phase)的二叉树构建主要是为后面的重定位,压缩和清扫做准备。
二叉树是其关键一步。
大致为:
1.区分固定对象和非固定对象,如果非固定对象后面跟着非固定对象就会形成一个堆段,如果后面继续有非固定对象,则继续加入这个小堆段。如果后面跟着固定对象则到小堆段到此为止。然后判断固定对象后面是否跟着固定对象,如果是则把这两个固定对象形成一个小堆段。后面继续判断,如果还是固定对象则加入到小堆段。如没有,则此小堆段到此为止。其逻辑跟非固定对象一样。如此一直遍历完这个堆,这样的话堆里面形成了一个个小堆段。
2.这些小堆段,会被plan_phase当成一个个的节点,然后把这些节点通过相关的逻辑构建成一颗二叉树。
3.如果二叉树过于庞大,则无论是在时间还是在空间上的复杂度都很高。为了避免性能问题,于是引入了brick_table来分割这颗庞大的二叉树
结尾
理解其行为,则需联系上下文,查看其整体构建,然后逐步推导。

GC plan_phase二叉树挂接的一个算法的更多相关文章
- .Net CLR GC plan_phase二叉树和Brick_table
楔子 别那么懒,勤快点.以下取自CLR PreView 7.0. 主题 GC计划阶段(plan_phase)主要就两个部分,一个是堆里面的对象构建一颗二叉树(这颗二叉树的每个节点包含了诸如对象移动信息 ...
- 对于一棵二叉树,请设计一个算法,创建含有某一深度上所有结点的链表。 给定二叉树的根结点指针TreeNode* root,以及链表上结点的深度,请返回一个链表ListNode,代表该深度上所有结点的值,请按树上从左往右的顺序链接,保证深度不超过树的高度,树上结点的值为非负整数且不超过100000。
/* struct TreeNode { int val; struct TreeNode *left; struct TreeNode *right; TreeNode(int x) : val(x ...
- GC 为什么要挂起用户线程? 什么愁什么怨?
GC 为什么要挂起用户线程? 什么愁什么怨? 前言 JVM 系列文章的第一篇.敬请期待后续. 故障描述 某年某月某日 上午,线上发生故障,经过排查,发现某核心服务 Dubbo 接口超时. 故障根源 查 ...
- 介绍对称加密的另一个算法——PBE
除了DES,我们还知道有DESede(TripleDES,就是3DES).AES.Blowfish.RC2.RC4(ARCFOUR)等多种对称加密方式,其实现方式大同小异,这里介绍对称加密的另一个算法 ...
- [每天默写一个算法]KMP
[每天默写一个算法]KMP 作业要求:默写String的KMP算法. KMP是经典的字符串匹配算法.复杂度为O(n+m) public static class StringKMP { /// < ...
- 推荐一个算法编程学习中文社区-51NOD【算法分级,支持多语言,可在线编译】
最近偶尔发现一个算法编程学习的论坛,刚开始有点好奇,也只是注册了一下.最近有时间好好研究了一下,的确非常赞,所以推荐给大家.功能和介绍看下面介绍吧.首页的标题很给劲,很纯粹的Coding社区....虽 ...
- cc150:实现一个算法来删除单链表中间的一个结点,仅仅给出指向那个结点的指针
实现一个算法来删除单链表中间的一个结点,仅仅给出指向那个结点的指针. 样例: 输入:指向链表a->b->c->d->e中结点c的指针 结果:不须要返回什么,得到一个新链表:a- ...
- 设单链表中存放n个字符,试设计一个算法,使用栈推断该字符串是否中心对称
转载请注明出处:http://blog.csdn.net/u012860063 问题:设单链表中存放n个字符.试设计一个算法,使用栈推断该字符串是否中心对称,如xyzzyx即为中心对称字符串. 代码例 ...
- python学习:设计一个算法将缺失的数字找出来。
算法题 已知整型数值 a[99], 包含的所有99个元素都是从1-100中随机取值,并且这99个数两两互不相等,也就是说从1到100这100个数字有99个在数值内,有一个缺失.请设计一个算法将缺失 ...
随机推荐
- Class对象共嫩
需求:写一个"框架",不能改变该类的任何代码的前提下,可以帮我们创建任意类的对象,并且执行其中任意方法 实现: 1.配置文件 2.反射 步骤: 1.将需要创建的对象的全类名和需要执 ...
- .NET性能优化-使用SourceGenerator-Logger记录日志
前言 在现在许许多多的应用系统中,日志非常关键,它即是排查问题的强力工具,也是程序员居家旅行工作甩锅必备良品. 在团队中编码中,我们都要求对于那些会变更数据的接口.调用第三方的接口记录请求和响应参数, ...
- 「Python实用秘技10」深度比较Python对象间差异
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第10 ...
- 【沥血整理】灰度(二值)图像重构算法及其应用(morphological reconstruction)。
不记得是怎么接触并最终研究这个课题的了,认识我的人都知道我是没有固定的研究对象的,一切看运气和当时的兴趣.本来研究完了就放在那里了,一直比较懒的去做总结,但是想一想似乎在网络上就没有看到关于这个方面的 ...
- LuoguP2575 高手过招(博弈论)
空格数变吗?不变呀 阶梯博弈阶梯数变吗?不变呀 那这不就阶梯博弈,每行一栋楼,爬完\(mex\)就可以了吗? #include <iostream> #include <cstdio ...
- poi生成表格自动合并单元格
直接复制这个工具类即可使用: /** * 合并单元格 * @author tongyao * @param sheet sheet页 * @param titleColumn 标题占用行 * @par ...
- 【Java】学习路径54-使用UDP协议开发发送、接收端
UDP协议,简单的说就是,发信息. 不管对方有没有收到. 发送端: import java.net.*; public class UDP_Send { public static void main ...
- 基于开源方案构建统一的文件在线预览与office协同编辑平台的架构与实现历程
大家好,又见面了. 在构建业务系统的时候,经常会涉及到对附件的支持,继而又会引申出对附件在线预览.在线编辑.多人协同编辑等种种能力的诉求. 对于人力不是特别充裕.或者项目投入预期规划不是特别大的公司或 ...
- bat-MD文件转CSV文件
目录 1. bat文件里面写死文件名 2. 拖入文件 注意:每个单元格不能出现字符[|.$.;] 1. bat文件里面写死文件名 @echo off && setlocal enabl ...
- .Net+Vue3实现数据简易导入功能
在开发的过程中,上传文件或者导入数据是一件很常见的事情,导入数据可以有两种方式: 前端上传文件到后台,后台读取文件内容,进行验证再进行存储 前端读取数据,进行数据验证,然后发送数据到后台进行存储 这两 ...