HDFS文件读写过程
参考自《Hadoop权威指南》 [http://www.cnblogs.com/swanspouse/p/5137308.html]
HDFS读文件过程:
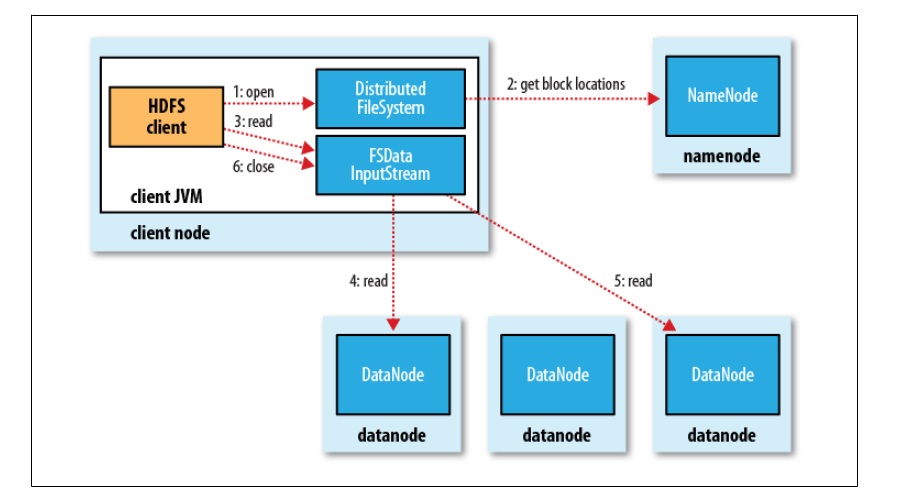
- 客户端通过调用FileSystem对象的open()来读取希望打开的文件。对于HDFS来说,这个对象是分布式文件系统的一个实例。
- DistributedFileSystem通过RPC来调用namenode,以确定文件的开头部分的块位置。对于每一块,namenode返回具有该块副本的datanode地址。此外,这些datanode根据他们与client的距离来排序(根据网络集群的拓扑)。如果该client本身就是一个datanode,便从本地datanode中读取。DistributedFileSystem 返回一个FSDataInputStream对象给client读取数据,FSDataInputStream转而包装了一个DFSInputStream对象。
- 接着client对这个输入流调用read()。存储着文件开头部分块的数据节点地址的DFSInputStream随即与这些块最近的datanode相连接。
- 通过在数据流中反复调用read(),数据会从datanode返回client。
- 到达块的末端时,DFSInputStream会关闭与datanode间的联系,然后为下一个块找到最佳的datanode。client端只需要读取一个连续的流,这些对于client来说都是透明的。
- 在读取的时候,如果client与datanode通信时遇到一个错误,那么它就会去尝试对这个块来说下一个最近的块。它也会记住那个故障节点的datanode,以保证不会再对之后的块进行徒劳无益的尝试。client也会确认datanode发来的数据的校验和。如果发现一个损坏的块,它就会在client试图从别的datanode中读取一个块的副本之前报告给namenode。
- 这个设计的一个重点是,client直接联系datanode去检索数据,并被namenode指引到块中最好的datanode。因为数据流在此集群中是在所有datanode分散进行的。所以这种设计能使HDFS可扩展到最大的并发client数量。同时,namenode只不过提供块的位置请求(存储在内存中,十分高效),不是提供数据。否则如果客户端数量增长,namenode就会快速成为一个“瓶颈”。
HDFS写文件过程

- 客户端通过在DistributedFileSystem中调用create()来创建文件。
- DistributedFileSystem 使用RPC去调用namenode,在文件系统的命名空间创一个新的文件,没有块与之相联系。namenode执行各种不同的检查以确保这个文件不会已经存在,并且在client有可以创建文件的适当的许可。如果检查通过,namenode就会生成一个新的文件记录;否则,文件创建失败并向client抛出一个IOException异常。分布式文件系统返回一个文件系统数据输出流,让client开始写入数据。就像读取事件一样,文件系统数据输出流控制一个DFSOutputStream,负责处理datanode和namenode之间的通信。
- 在client写入数据时,DFSOutputStream将它分成一个个的包,写入内部队列,称为数据队列。数据流处理数据队列,数据流的责任是根据适合的datanode的列表要求namenode分配适合的新块来存储数据副本。这一组datanode列表形成一个管线————假设副本数是3,所以有3个节点在管线中。
- 数据流将包分流给管线中第一个的datanode,这个节点会存储包并且发送给管线中的第二个datanode。同样地,第二个datanode存储包并且传给管线中的第三个数据节点。
- DFSOutputStream也有一个内部的数据包队列来等待datanode收到确认,称为确认队列。一个包只有在被管线中所有的节点确认后才会被移除出确认队列。如果在有数据写入期间,datanode发生故障, 则会执行下面的操作,当然这对写入数据的client而言是透明的。首先管线被关闭,确认队列中的任何包都会被添加回数据队列的前面,以确保故障节点下游的datanode不会漏掉任意一个包。为存储在另一正常datanode的当前数据块制定一个新的标识,并将该标识传给namenode,以便故障节点datanode在恢复后可以删除存储的部分数据块。从管线中删除故障数据节点并且把余下的数据块写入管线中的两个正常的datanode。namenode注意到块复本量不足时,会在另一个节点上创建一个新的复本。后续的数据块继续正常接收处理。只要dfs.replication.min的副本(默认是1)被写入,写操作就是成功的,并且这个块会在集群中被异步复制,直到其满足目标副本数(dfs.replication 默认值为3)。
- client完成数据的写入后,就会在流中调用close()。
- 在向namenode节点发送完消息之前,此方法会将余下的所有包放入datanode管线并等待确认。namenode节点已经知道文件由哪些块组成(通过Data streamer 询问块分配),所以它只需在返回成功前等待块进行最小量的复制。
- 复本的布局:需要对可靠性、写入带宽和读取带宽进行权衡。Hadoop的默认布局策略是在运行客户端的节点上放第1个复本(如果客户端运行在集群之外,就随机选择一个节点,不过系统会避免挑选那些存储太满或太忙的节点。)第2个复本放在与第1个复本不同且随机另外选择的机架的节点上(离架)。第3个复本与第2个复本放在相同的机架,且随机选择另一个节点。其他复本放在集群中随机的节点上,不过系统会尽量避免相同的机架放太多复本。
- 总的来说,这一方法不仅提供了很好的稳定性(数据块存储在两个机架中)并实现很好的负载均衡,包括写入带宽(写入操作只需要遍历一个交换机)、读取性能(可以从两个机架中选择读取)和集群中块的均匀分布(客户端只在本地机架上写入一个块)。
HDFS文件读写过程的更多相关文章
- HDFS 文件读写过程
HDFS 文件读写过程 HDFS 文件读取剖析 客户端通过调用FileSystem对象的open()来读取希望打开的文件.对于HDFS来说,这个对象是分布式文件系统的一个实例. Distributed ...
- Hadoop之HDFS文件读写过程
一.HDFS读过程 1.1 HDFS API 读文件 Configuration conf = new Configuration(); FileSystem fs = FileSystem.get( ...
- 【Hadoop】二、HDFS文件读写流程
(二)HDFS数据流 作为一个文件系统,文件的读和写是最基本的需求,这一部分我们来了解客户端是如何与HDFS进行交互的,也就是客户端与HDFS,以及构成HDFS的两类节点(namenode和dat ...
- f2fs源码分析之文件读写过程
本篇包括三个部分:1)f2fs 文件表示方法: 2)NAT详细介绍:3)f2fs文件读写过程:4) 下面详细阐述f2fs读写的过程. 管理数据位置关键的数据结构是node,node包括三种:inode ...
- HDFS文件读写流程
一.HDFS HDFS全称是Hadoop Distributed System.HDFS是为以流的方式存取大文件而设计的.适用于几百MB,GB以及TB,并写一次读多次的场合.而对于低延时数据访问.大量 ...
- HBase 文件读写过程描述
HBase 数据读写过程描述 我们熟悉的在 Hadoop 使用的文件格式有许多种,例如: Avro:用于 HDFS 数据序序列化与 Parquet:常见于 Hive 数据文件保存在 HDFS中 HFi ...
- HDFS文件读写流程 (转)
文件读取的过程如下: 使用HDFS提供的客户端开发库Client,向远程的Namenode发起RPC请求: Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namen ...
- HDFS文件读写操作(基础基础超基础)
环境 OS: Ubuntu 16.04 64-Bit JDK: 1.7.0_80 64-Bit Hadoop: 2.6.5 原理 <权威指南>有两张图,下次po上来好好聊一下 实测 读操作 ...
- hadoop笔记-hdfs文件读写
概念 文件系统 磁盘进行读写的最小单位:数据块,文件系统构建于磁盘之上,文件系统的块大小是磁盘块的整数倍. 文件系统块一般为几千字节,磁盘块一般512字节. hdfs的block.pocket.chu ...
随机推荐
- xcode7 打开工程错误 This Document requires xcode8.0 or later.
xcode7 打开工程错误 This Document requires xcode8.0 or later. 场景: xcode7创建的工程,后来安装了xcode8.0,用8打开7的工程跑了一下: ...
- sqlplus无密码登录TNS协议适配器错误
登录到sqlplus使用无密码登录用户时出现:TNS协议适配器错误 检查自己是否有多个数据库,可能默认登录的数据库服务没有启动,启动即可. 查看当前数据库名 select name from v$d ...
- Source Insight简介及下载破解
对于长期混迹于.net平台的开发人员来说,研究C源码不是很常见,但是有时候我们不得不涉及c的研究,因为许多优秀的开源软件是用C/C++写就.查看C源码的利器除了VS外,还有另一个,那就是Source ...
- 并发编程 04——闭锁CountDownLatch 与 栅栏CyclicBarrier
Java并发编程实践 目录 并发编程 01—— ThreadLocal 并发编程 02—— ConcurrentHashMap 并发编程 03—— 阻塞队列和生产者-消费者模式 并发编程 04—— 闭 ...
- SSM框架学习之高并发秒杀业务--笔记2-- DAO层
上节中利用Maven创建了项目,并导入了所有的依赖,这节来进行DAO层的设计与开发 第一步,创建数据库和表. 首先分析业务,这个SSM匡济整合案例是做一个商品的秒杀系统,要存储的有:1.待秒杀的商品的 ...
- C#测试web服务是否可用
winform客户端经常需要调用webservice或者WCF进行数据交互,但是远程服务有可能不存在或者服务器不可用,客户端只能通过超时或者捕获到异常感知服务不可用.其实有一个COM借口可用快速的检测 ...
- 使用Dottrace跟踪代码执行时间
当自己程序遇到性能问题,比如IIs请求反应缓慢,客户端程序执行缓慢,怎么分析是哪里出了问题呢?dottrace可以帮助.net程序跟踪出代码里每个方法的执行时间,这样让我们更清晰的看出是哪里执行时间过 ...
- eclipse 闪退
在eclipse.ini文件中加入 -Dorg.eclipse.swt.browser.DefaultType=mozilla
- [vijos P1180] 选课
这一周竟然都没好好码题目,不过至少把这题的树形DP给摸了个大概.吐槽一下自己,递归已经基本不会用了…QAQ!按老师的话来说“太危险了!” 此题用到多叉树转二叉树,左孩子是真正意义的孩子(先修完自己才能 ...
- 用maven搭建 testNG+PowerMock+Mockito测试框架
单元测试是开发中必不可少的一部分,是产品代码的重要保证. Junit和testNG是当前最流行的测试框架,Junit是使用最广泛的测试框架,有兴趣的话自己baidu一下. testNG基于Junit和 ...