python字符编码(二)
一.什么是字符编码
计算机要想工作必须通电,也就是说‘电’驱使计算机干活,而‘电’的特性,就是高低电压(高低压即二进制数1,低电压即二进制数0),也就是说计算机只认识数字
编程的目的是让计算机干活,而编程的结果说白了只是一堆字符,也就是说我们编程最终要实现的是:一堆字符驱动计算机干活
所以必须经过一个过程:
字符串--------(翻译过程)------->数字
这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之为字符编码
二.字符编码分类
计算机由美国人发明,最早的字符编码为ASCII,只规定了英文字母数字和一些特殊字符与数字的对应关系。最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号

当然我们编程语言都用英文没问题,ASCII够用,但是在处理数据时,不同的国家有不同的语言,日本人会在自己的程序中加入日文,中国人会加入中文。
而要表示中文,单拿一个字节表表示一个汉子,是不可能表达完的(连小学生都认识两千多个汉字),解决方法只有一个,就是一个字节用>8位2进制代表,位数越多,代表的变化就多,这样,就可以尽可能多的表达出不通的汉字
所以中国人规定了自己的标准gb2312编码,规定了包含中文在内的字符->数字的对应关系。
日本人规定了自己的Shift_JIS编码
韩国人规定了自己的Euc-kr编码(另外,韩国人说,计算机是他们发明的,要求世界统一用韩国编码)
这时候问题出现了,精通18国语言的小周同学谦虚的用8国语言写了一篇文档,那么这篇文档,按照哪国的标准,都会出现乱码(因为此刻的各种标准都只是规定了自己国家的文字在内的字符跟数字的对应关系,如果单纯采用一种国家的编码格式,那么其余国家语言的文字在解析时就会出现乱码)
所以迫切需要一个世界的标准(能包含全世界的语言)于是unicode应运而生(韩国人表示不服,然后没有什么卵用)
ascii用1个字节(8位二进制)代表一个字符
unicode常用2个字节(16位二进制)代表一个字符,生僻字需要用4个字节
例:
字母x,用ascii表示是十进制的120,二进制0111 1000
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
字母x,用unicode表示二进制0000 0000 0111 1000,所以unicode兼容ascii,也兼容万国,是世界的标准
这时候乱码问题消失了,所有的文档我们都使用但是新问题出现了,如果我们的文档通篇都是英文,你用unicode会比ascii耗费多一倍的空间,在存储和传输上十分的低效
本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
三.字符编码转换关系
3.1 程序运行原理
首先需明确,计算机各组件之间协同工作,数据传输都是二进制形式,在计算机看来,没有文字,一切都是二进制数,计算机运行主要依靠
cpu:从内存中取出二进制指令执行
内存:从硬盘取出二进制数据提供给cpu运行
硬盘:将人类认识的文字以二进制的形式存放到磁盘上
文件和程序文件都特么的是文件,文件内容的读取或者程序的运行都需要把
- 程序员开发程序,最终写了一堆人为定义的人类认为有意义的文字符号表示,以二进制形式保存到硬盘
- 程序运行,操作系统从硬盘上找到存放程序代码的位置,读取二进制到内存
- python解释器从内存里读二进制,解释执行
3.2 终极揭秘
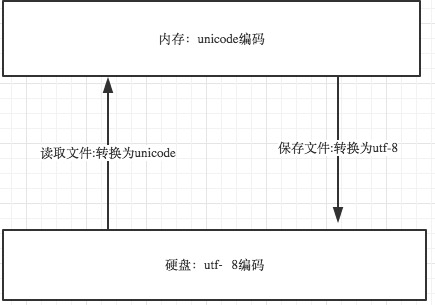
首先我们在终端定义一个内存变量:name='林海峰',那这个内存变量被存放到内存(必然是二进制),所以需要一个编码,就是unicode(内存中使用字符编码固定就是unicode)
但是如果我们写到文件中name='林海峰'保存到硬盘(必然是二进制),也需要一个编码,这就跟各个国家有关了,假设我们用gbk,那么文件就被以gbk形式保存到硬盘上了。
程序要运行:硬盘二进制(gbk)---> 内存二进制(unicode)
就是说,所有程序,最终都要加载到内存,程序保存到硬盘不同的国家用不同的编码格式,但是到内存中我们为了兼容万国(计算机可以运行任何国家的程序原因在于此),统一且固定使用unicode,这就是为何内存固定用unicode的原因,你可能会说兼容万国我可以用utf-8啊,可以,完全可以正常工作,之所以不用肯定是unicode比utf-8更高效啊(uicode固定用2个字节编码,utf-8则需要计算),但是unicode更浪费空间,没错,这就是用空间换时间的一种做法,而存放到硬盘,或者网络传输,都需要把unicode转成utf-8,因为数据的传输,追求的是稳定,高效,数据量越小数据传输就越靠谱,于是都转成utf-8格式的,而不是unicode。
gbk->unicode需要decode(),unicode->gbk需要encode()就是这个意思
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器

python程序比较特殊,要想运行需要python解释器去调用,也就相当于python解释器去读内存的程序的unicode代码
因而python解释器也有个解释器默认编码可以用sys.getdefaultencoding()查看,如果不在python文件指定头信息#-*-coding:utf-8-*-,那就使用默认的
注意了,这个编码,是python解释器这个软件的编码
3.3 补充
抛开编程,我们单独写一个文件,保存到硬盘上,也需要有字符编码啊,过程如下
首先,我们要编辑文档,你总不能自己控制高低电压往硬盘写入二进制吧,总得又一个软件吧,软件就是一个运行的程序啊,你所写的内容都是由运行在内存中的软件去操作的,所以像下面这样的数据你不点保存,都还是在内存中(有些软件会隔几秒自动执行保存),此刻如果断电呢,数据当然全都没了啊,也就是说下面的这些数据其实都被保存到内存中,是unicode格式。

pycharm本质也跟word一样啊?都是处理文件的软件

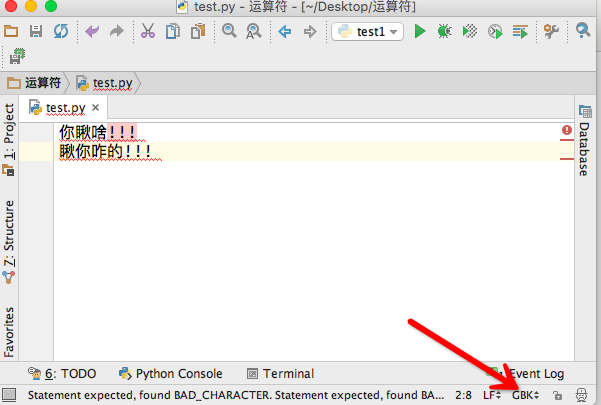
但是如果修改文件保存的编码,即硬盘编码使用gbk,提交操作后,保存上面的文件,那么文件就被以gbk格式保存到了硬盘上

然后关闭pycharm,我们重新打开,文件默认编码打开编码如果是utf-8,那么必然就乱了啊,因为硬盘(gbk)--->内存(unicode)<---pycharm(使用utf-8去读)

修改成gbk方式读取
总结
其实无论是word也好pycharm也好,python解释器也好,我们都可当她们是处理文件的软件
注意:
- python2.7解释器默认编码为ascii
- python3.5解释器默认编码为utf-8
- 不管是python解释器也好还是其他与文本相关的软件也好,它们只能指定存取文件到硬盘的字符编码,而内存中固定使用uniccode
- test.py文件的头#-*-coding:utf-8-*-就是在修改python解释器的编码
流程:
- 从硬盘读区test.py的二进制bytes类型数据加载到内存,此刻python解释器就是一个类word软件啊,python解释器用自己的编码,将文件的二进制解码成unicode放到内存中
- python解释器从内存中读取unicode代码解释执行,执行时的代码中函数指定的编码与python解释器再无半点关系
python字符编码(二)的更多相关文章
- python --- 字符编码学习小结(二)
距离上一篇的python --- 字符编码学习小结(一)已经过去2年了,2年的时间里,确实也遇到了各种各样的字符编码问题,也能解决,但是每次都是把所有的方法都试一遍,然后终于正常.这种方法显然是不科学 ...
- python 字符编码练习
通过下面的练习,加深对python字符编码的认识 # \x00 - \xff 256个字符 >>> a = range(256)>>> b = bytes(a) # ...
- 转1:Python字符编码详解
Python27字符编码详解 声明 一 字符编码基础 1 抽象字符清单ACR 2 已编码字符集CCS 3 字符编码格式CEF 31 ASCII初创 311 ASCII 312 EASCII 32 MB ...
- Python字符编码讲解
声明:本文参考 Python字符编码详解 在计算机中我们不管用什么语言和程序,最终数据在计算机中的都是字节码(也就是01形式)的形式存在的,如果 计算机直接把字节码显示在屏幕上,很明显一般人看不懂字节 ...
- 深入理解Python字符编码--转
http://blog.51cto.com/9478652/2057896 不论你是有着多年经验的 Python 老司机还是刚入门 Python 不久,你一定遇到过UnicodeEncodeError ...
- 深入理解Python字符编码
不论你是有着多年经验的 Python 老司机还是刚入门 Python 不久,你一定遇到过UnicodeEncodeError.UnicodeDecodeError 错误,每当遇到错误我们就拿着 enc ...
- Python字符编码详解,str,bytes
什么是明文 “明文”是可以是文本,音乐,可以编码成mp3文件.明文可以是图像的,可以编码为gif.png或jpg文件.明文是电影的,可以编码成wmv文件.不一而足. 什么是编码?把明文变成计算机语言 ...
- Python字符编码补充
字符编码: Python字符编码贯穿Python学习的始终,现在应用的是Python2中字符编码的问题是很多的. 这次是要彻底解决Python字符编码的问题!!! 1 字符编码的发展过程: 1 .AS ...
- 转2:Python字符编码详解
1. 字符编码简介 1.1. ASCII ASCII(American Standard Code for Information Interchange),是一种单字节的编码.计算机世界里一开始只有 ...
随机推荐
- 基于Laravel+Swoole开发智能家居后端
基于Laravel+Swoole开发智能家居后端 在上一篇<Laravel如何优雅的使用Swoole>中我已经大概谈到了Laravel结合Swoole的用法. 今天,我参与的智能家居项目基 ...
- 从C++研发到前端工程师
前言 伴随着今天收到了网易的前端offer,我的转行面试告一段落.能拿到网易的offer很意外,也弥补了去年网易校招被刷的遗憾.虽然从c++转行到前端不是一件很困难的事,但是也说不上轻松,反正我用了整 ...
- Javascript DOM操作实例
最近在学DOM,但是还是没有办法很好的记住API,想找些例子来练习,网上的例子将一个个DOM对象方法挨个举例,并没有集合在一起用,效果不尽人意.所以自己写一份实例,顺便巩固下学到的知识. ...
- C# 调用一个按钮的Click事件(利用反射)
最基本的调用方法 (1)button1.PerformClick();(2)button1_Click(null,null);(3)button_Click(null,new EventArgs()) ...
- jquery渐渐的显示、隐藏效果
<!DOCTYPE html> <html> <head> <meta charset="gb2312" /> <title& ...
- zabbix监控网络的出入口流量
首先我们登录到zabbix 点击配置---->模板-->Template OS Linux 下的监控项 点击右上角的添加监控项目 我们的服务器是在Ucloud上的,我们的网卡名称为eth0 ...
- python 批量更改文件名
工作中遇到一种情况,就是市场部那边经常发过来一些apk的包 但是要求更改名字,文件太多了,没办法,只有想办法了,还好命名都是有规则的 比如说 YZLoan-gdtyyb-V2.23.apk------ ...
- iPad开发--UIPopoverController简单使用iOS7之前和iOS7之后的使用方法
一.iOS7之前的Popover的使用 对Popover进行懒加载处理 内容控制器中设置Popover弹出后的尺寸 设置显示的位置,两种情况.1 -- 给BarButtonItem设置Popover的 ...
- C#查看各种变量的指针地址
将项目的“可编译不安全代码”属性设置为true就可以了,方法如下:项目属性对话框->配置属性->生成->允许不安全代码块 namespace Pointer { struct XYZ ...
- 状态压缩 poj 3254
n * m 个玉米 n*m个数字 0 或者1 1可以种玉米 0 不能 种玉米不能相邻 计算有几种 种的方法 #include<stdio.h> #include<algorithm ...