数据挖掘系列(9)——BP神经网络算法与实践
神经网络曾经很火,有过一段低迷期,现在因为深度学习的原因继续火起来了。神经网络有很多种:前向传输网络、反向传输网络、递归神经网络、卷积神经网络等。本文介绍基本的反向传输神经网络(Backpropagation 简称BP),主要讲述算法的基本流程和自己在训练BP神经网络的一些经验。
BP神经网络的结构
神经网络就是模拟人的大脑的神经单元的工作方式,但进行了很大的简化,神经网络由很多神经网络层构成,而每一层又由许多单元组成,第一层叫输入层,最后一层叫输出层,中间的各层叫隐藏层,在BP神经网络中,只有相邻的神经层的各个单元之间有联系,除了输出层外,每一层都有一个偏置结点:
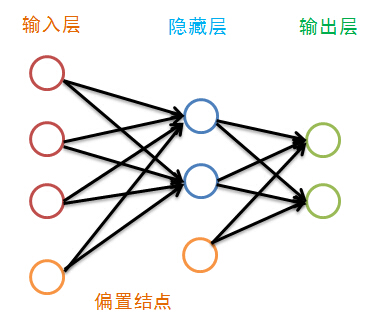
虽然图中隐藏层只画了一层,但其层数并没有限制,传统的神经网络学习经验认为一层就足够好,而最近的深度学习不这么认为。偏置结点是为了描述训练数据中没有的特征,偏置结点对于下一层的每一个结点的权重的不同而生产不同的偏置,于是可以认为偏置是每一个结点(除输入层外)的属性。我们偏置结点在图中省略掉:

在描述BP神经网络的训练之前,我们先来看看神经网络各层都有哪些属性:
- 每一个神经单元都有一定量的能量,我们定义其能量值为该结点j的输出值$O_j$;
- 相邻层之间结点的连接有一个权重$W_{ij}$,其值在[-1,1]之间;
- 除输入层外,每一层的各个结点都有一个输入值,其值为上一层所有结点按权重传递过来的能量之和加上偏置;
- 除输入层外,每一层都有一个偏置值,其值在[0,1]之间;
- 除输入层外,每个结点的输出值等该结点的输入值作非线性变换;
- 我们认为输入层没有输入值,其输出值即为训练数据的属性,比如一条记录$X=<(1,2,3),类别1>$,那么输入层的三个结点的输出值分别为1,2,3. 因此输入层的结点个数一般等于训练数据的属性个数。
训练一个BP神经网络,实际上就是调整网络的权重和偏置这两个参数,BP神经网络的训练过程分两部分:
- 前向传输,逐层波浪式的传递输出值;
- 逆向反馈,反向逐层调整权重和偏置;
我们先来看前向传输。
前向传输(Feed-Forward前向反馈)
在训练网络之前,我们需要随机初始化权重和偏置,对每一个权重取[-1,1]的一个随机实数,每一个偏置取[0,1]的一个随机实数,之后就开始进行前向传输。
神经网络的训练是由多趟迭代完成的,每一趟迭代都使用训练集的所有记录,而每一次训练网络只使用一条记录,抽象的描述如下:
while 终止条件未满足:
for record:dataset:
trainModel(record)
首先设置输入层的输出值,假设属性的个数为100,那我们就设置输入层的神经单元个数为100,输入层的结点$N_i$为记录第i维上的属性值$x_i$。对输入层的操作就这么简单,之后的每层就要复杂一些了,除输入层外,其他各层的输入值是上一层输入值按权重累加的结果值加上偏置,每个结点的输出值等该结点的输入值作变换
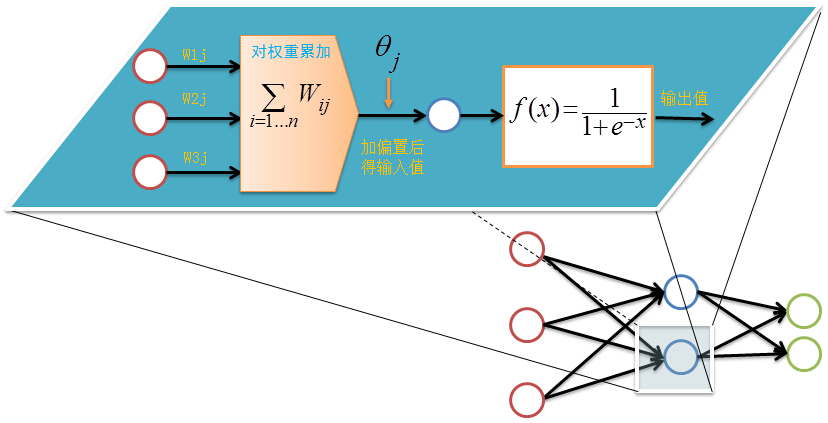
前向传输的输出层的计算过程公式如下:
$I_j=\sum_iW_{ij}O_i+\theta_j$
$O_j=\frac{1}{1+e^{-I_l}}$
对隐藏层和输出层的每一个结点都按照如上图的方式计算输出值,就完成前向传播的过程,紧接着是进行逆向反馈。
逆向反馈(Backpropagation)
逆向反馈从最后一层即输出层开始,我们训练神经网络作分类的目的往往是希望最后一层的输出能够描述数据记录的类别,比如对于一个二分类的问题,我们常常用两个神经单元作为输出层,如果输出层的第一个神经单元的输出值比第二个神经单元大,我们认为这个数据记录属于第一类,否则属于第二类。
还记得我们第一次前向反馈时,整个网络的权重和偏置都是我们随机取,因此网络的输出肯定还不能描述记录的类别,因此需要调整网络的参数,即权重值和偏置值,而调整的依据就是网络的输出层的输出值与类别之间的差异,通过调整参数来缩小这个差异,这就是神经网络的优化目标。对于输出层:
$E_j=O_j(1-O_j)(T_j-O_j)$
其中$E_j$表示第j个结点的误差值,$O_j$表示第j个结点的输出值,$T_j$记录输出值,比如对于2分类问题,我们用01表示类标1,10表示类别2,如果一个记录属于类别1,那么其$T_1=0$,$T_2=1$。
中间的隐藏层并不直接与数据记录的类别打交道,而是通过下一层的所有结点误差按权重累加,计算公式如下:
$E_j=O_j(1-O_j)\sum_kE_kW_{jk}$
其中$W_{jk}$表示当前层的结点j到下一层的结点k的权重值,$E_k$下一层的结点k的误差率。
计算完误差率后,就可以利用误差率对权重和偏置进行更新,首先看权重的更新:
$\Delta W_{ij}=\lambda E_jO_i$
$W_{ij}=W_{ij}+\Delta W_{ij}$
其中$\lambda$表示表示学习速率,取值为0到1,学习速率设置得大,训练收敛更快,但容易陷入局部最优解,学习速率设置得比较小的话,收敛速度较慢,但能一步步逼近全局最优解。
更新完权重后,还有最后一项参数需要更新,即偏置:
$\Delta \theta_j=\lambda E_j$
$\theta_j=\theta_j+\Delta \theta_j$
至此,我们完成了一次神经网络的训练过程,通过不断的使用所有数据记录进行训练,从而得到一个分类模型。不断地迭代,不可能无休止的下去,总归有个终止条件
训练终止条件
每一轮训练都使用数据集的所有记录,但什么时候停止,停止条件有下面两种:
- 设置最大迭代次数,比如使用数据集迭代100次后停止训练
- 计算训练集在网络上的预测准确率,达到一定门限值后停止训练
使用BP神经网络分类
我自己写了一个BP神经网络,在数字手写体识别数据集MINIST上测试了一下,MINIST数据集中训练图片有12000个,测试图片20000个,每张图片是28*28的灰度图像,我对图像进行了二值化处理,神经网络的参数设置如下:
- 输入层设置28*28=784个输入单元;
- 输出层设置10个,对应10个数字的类别;
- 学习速率设置为0.05;
训练经过约50次左右迭代,在训练集上已经能达到99%的正确率,在测试集上的正确率为90.03%,单纯的BP神经网络能够提升的空间不大了,但kaggle上已经有人有卷积神经网络在测试集达到了99.3%的准确率。代码是去年用C++写的,浓浓的JAVA的味道,代码价值不大,但注释比较详细,可以查看这里,最近写了一个Java多线程的BP神经网络,但现在还不方便拿出来,如果项目黄了,再放上来吧。
训练BP神经网络的一些经验
讲一下自己训练神经网络的一点经验:
- 学习速率不宜设置过大,一般小于0.1,开始我设置了0.85,准确率一直提不上去,很明显是陷入了局部最优解;
- 输入数据应该归一化,开始使用0-255的灰度值测试,效果不好,转成01二值后,效果提升显著;
- 尽量是数据记录随机分布,不要将数据集按记录排序,假设数据集有10个类别,我们把数据集按类别排序,一条一条记录地训练神经网络,训练到后面,模型将只记得最近训练的类别而忘记了之前训练的类别;
- 对于多分类问题,比如汉字识别问题,常用汉字就有7000多个,也就是说有7000个类别,如果我们将输出层设置为7000个结点,那计算量将非常大,并且参数过多而不容易收敛,这时候我们应该对类别进行编码,7000个汉字只需要13个二进制位即可表示,因此我们的输出成只需要设置13个结点即可。
参考文献:
Jiawei Han. 《Data Mning Concepts and Techniques》
转载请注明出处:http://www.cnblogs.com/fengfenggirl/
数据挖掘系列(9)——BP神经网络算法与实践的更多相关文章
- bp神经网络算法
对于BP神经网络算法,由于之前一直没有应用到项目中,今日偶然之时 进行了学习, 这个算法的基本思路是这样的:不断地迭代优化网络权值,使得输入与输出之间的映射关系与所期望的映射关系一致,利用梯度下降的方 ...
- 二、单层感知器和BP神经网络算法
一.单层感知器 1958年[仅仅60年前]美国心理学家FrankRosenblant剔除一种具有单层计算单元的神经网络,称为Perceptron,即感知器.感知器研究中首次提出了自组织.自学习的思想, ...
- BP神经网络算法预测销量高低
理论以前写过:https://www.cnblogs.com/fangxiaoqi/p/11306545.html,这里根据天气.是否周末.有无促销的情况,来预测销量情况. function [ ma ...
- BP神经网络算法学习
BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是眼下应用最广泛的神经网络模型之中的一个 ...
- BP神经网络算法推导及代码实现笔记zz
一. 前言: 作为AI入门小白,参考了一些文章,想记点笔记加深印象,发出来是给有需求的童鞋学习共勉,大神轻拍! [毒鸡汤]:算法这东西,读完之后的状态多半是 --> “我是谁,我在哪?” 没事的 ...
- R_Studio(神经网络)BP神经网络算法预测销量的高低
BP神经网络 百度百科:传送门 BP(back propagation)神经网络:一种按照误差逆向传播算法训练的多层前馈神经网络,是目前应用最广泛的神经网络 #设置文件工作区间 setwd('D:\\ ...
- JAVA实现BP神经网络算法
工作中需要预测一个过程的时间,就想到了使用BP神经网络来进行预测. 简介 BP神经网络(Back Propagation Neural Network)是一种基于BP算法的人工神经网络,其使用BP算法 ...
- BP神经网络算法改进
周志华机器学习BP改进 试设计一个算法,能通过动态调整学习率显著提升收敛速度,编程实现该算法,并选择两个UCI数据集与标准的BP算法进行实验比较. 1.方法设计 传统的BP算法改进主要有两类: - 启 ...
- BP神经网络算法推导
目录 前置知识 梯度下降法 激活函数 多元复合函数求偏导的相关知识 正向计算 符号定义 输入层 隐含层 输出层 误差函数 反向传播 输出层与隐含层之间的权值调整 隐含层与输入层之间权值的调整 计算步骤 ...
随机推荐
- servlet 学习(二)
一.ServletConfig讲解 1.1.配置Servlet初始化参数 在Servlet的配置文件web.xml中,可以使用一个或多个<init-param>标签为servlet配置一些 ...
- BIEE11G常用函数及使用说明
BIEE常用函数使用手册 1.AGGREGATE AT 此函数根据指定的级别聚合列.使用AGGREGATE AT 可确保始终在关键字AT 之后指定的级别执行度量聚合,而无论WHERE 子句如何. 语法 ...
- mysql锁机制总结
1.隔离级别 (1)读不提交(Read Uncommited,RU) 这种隔离级别下,事务间完全不隔离,会产生脏读,可以读取未提交的记录,实际情况下不会使用. (2)读提交(Read commited ...
- PHP非阻塞模式 (转自 尘缘)
让PHP不再阻塞当PHP作为后端处理需要完成一些长时间处理,为了快速响应页面请求,不作结果返回判断的情况下,可以有如下措施: 一.若你使用的是FastCGI模式,使用fastcgi_finish_re ...
- IntelliJ IDEA Cannot find declaration to go to
最近在用IntelliJ IDEA开发一个微服务的项目的时候,从git clone了代码, 再用IntelliJ IDEA导入项目以后.项目里好多方法,类和属性都无法转到定义或者声明处,无论是Ctrl ...
- 基于RMI服务传输大文件的完整解决方案
基于RMI服务传输大文件,分为上传和下载两种操作,需要注意的技术点主要有三方面,第一,RMI服务中传输的数据必须是可序列化的.第二,在传输大文件的过程中应该有进度提醒机制,对于大文件传输来说,这点很重 ...
- 为什么没有MMU的处理器无法安装操作系统?
所谓的处理器就是计算机的核心运算硬件,现在使用windows操作系统的用户使用的机器之中的处理器多数都是X86内核,而实际之上很多时候我们用户都是会在心目之中把一个处理器和其运行的特定操作系统挂钩,之 ...
- 百度CDN 网站SSL 配置
百度CDN SSL配置步骤 一般从SSL提供商购买到的证书是CRT二进制格式的. 1. 将 CRT 导入到IIS中, 然后从IIS中导出为PFX格式 2. 下载openssl,执行下面命令 提取用户证 ...
- plain framework 1 参考手册 入门指引之 模块
模块 总述 基础 数据库 引擎 事件 文件 网络 性能 脚本 系统 工具 总述 上图为plain framework(简称简约框架)所有的模块,包括基础.数据库.引擎.事件.文件.网络.性能.脚本.系 ...
- hdu3065 病毒侵袭持续中
题目地址:http://acm.split.hdu.edu.cn/showproblem.php?pid=3065 题目: 病毒侵袭持续中 Time Limit: 2000/1000 MS (Java ...