后向传播算法“backpropragation”详解
为什么要使用backpropagation?

梯度下降不用多说,如果不清楚的可以参考梯度下降算法。
神经网络的参数集合theta,包括超级多组weight和bais。
要使用梯度下降,就需要计算每一个参数的梯度,但是神经网络常常有数以万计,甚至百万的参数,所以需要使用backpropagation来高效地计算梯度。
backpropagation的推导
backpropagation背后的原理其实很简单,就是求导的链式法则。

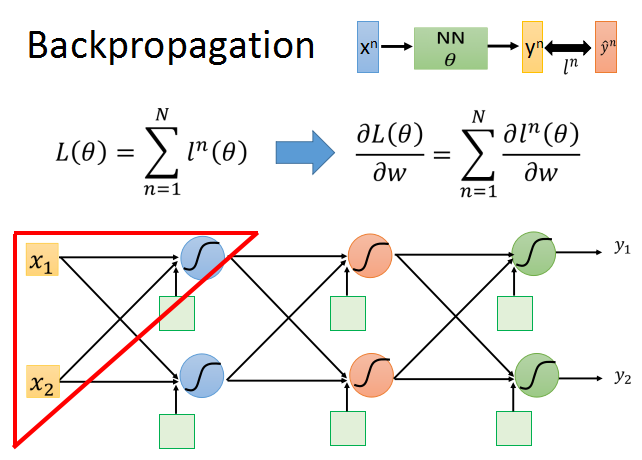
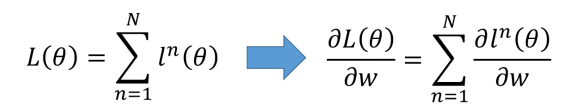
我们从上面的公式开始推导。以其中一个神经元为例。
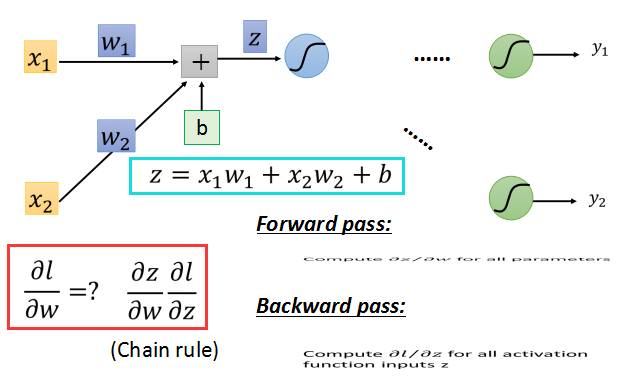
如上面的红框中所示,根据链式法则,l对w的偏导数,等于z对w的偏导数乘以l对z的偏导数。
l对w的梯度可以分为两部分:
前向传播:对所有参数求梯度;
后向传播:对所有激活函数的输入z求梯度;
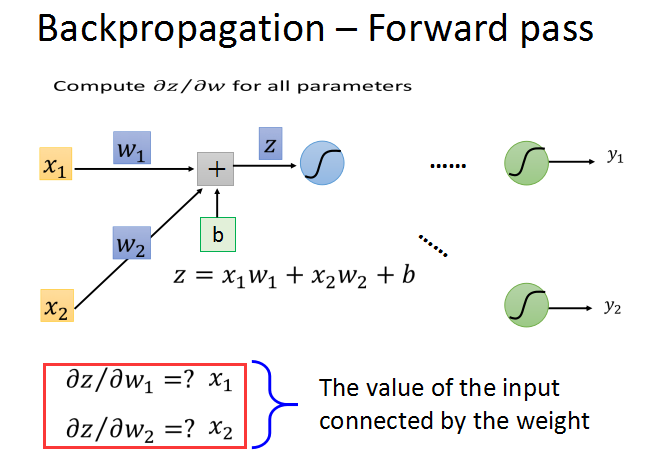
前向传播的梯度求法简单,就前一层的输入z对w求偏导数,直接求出就是对应的输入xi。
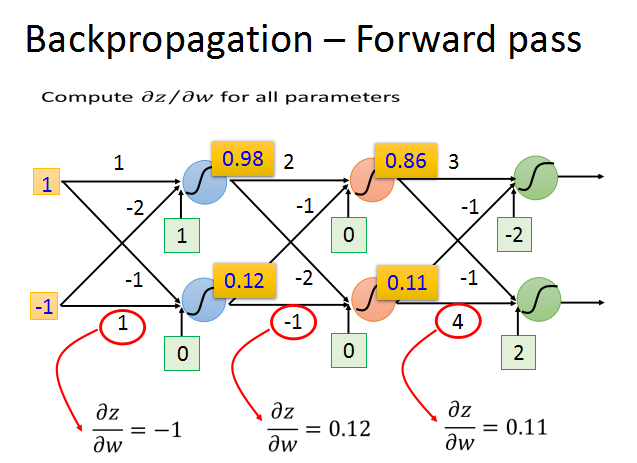
只要知道了激活函数的输出值,就可以轻易算出z/w的梯度,这个过程就是前向传播。
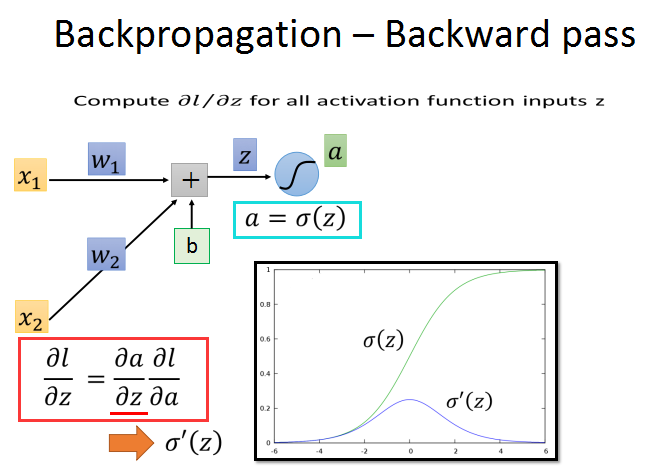
后向传播比较复杂,需要再使用链式法则,如红框中所示。l/z的梯度分解为a/z和l/a的梯度。
z对应当前节点的输入,a对应当前节点的输出。
a对z的导数图像如上所示,现在关键就是求l对a的偏导数。

为了求出l对a的偏导数,继续使用链式法则,关联上后面的两个神经元。
a通过z’和z''间接影响l,l/a的梯度应该是它所连接的所有神经元的梯度之和,不止是上面说的两项。
z'/a和z''/a的偏导数根据前向传播计算,分别是w3和w4.
现在问题就转化成了,求红框中的两个问号的梯度/

现在假设两个问号梯度已知,就可以求出之前l对z的梯度了。
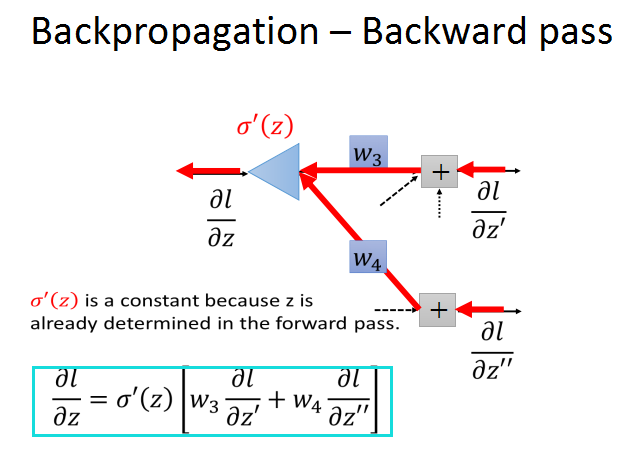
这样看上去有形成了一个新的网络,一个新的neural,输入是l/z'和l/z''的梯度,分别乘上对应权重w3,w4,
经过激活函数(乘以sigma(z)的导数)的作用,输出l/z的梯度。
现在来看看怎么可以求出l对z的梯度。

第一种情况:当z‘和z’‘为输出层时。根据链式法则,y/z的梯度可以根据对应的激活函数算出了,l/y的梯度是根据Cost function算出来的,这样问题就解决了。
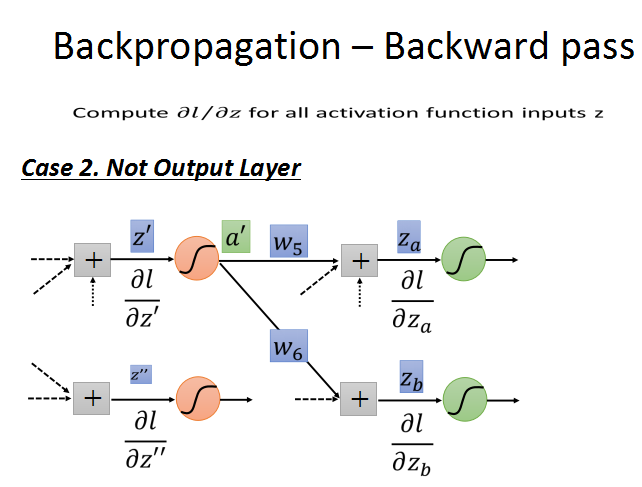
第二种情况:不是输出层。就是说还有后续的神经元节点连接,往后继续使用链式法则求导,直至输出层。
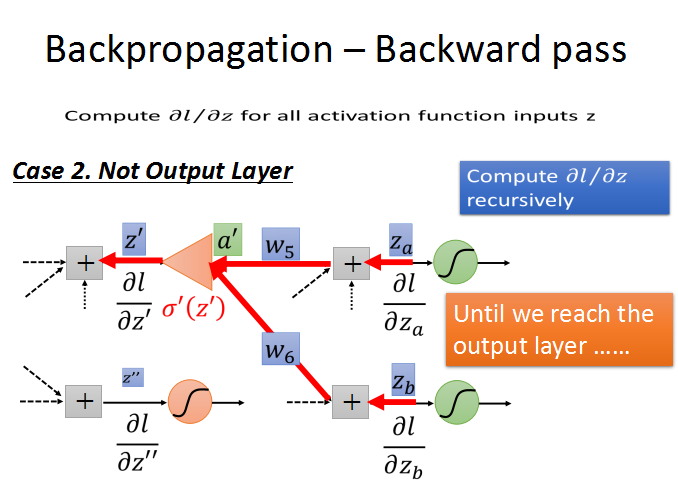
循环计算l对z的梯度,直到输出层,出现case1的情况,问题也就解决了。
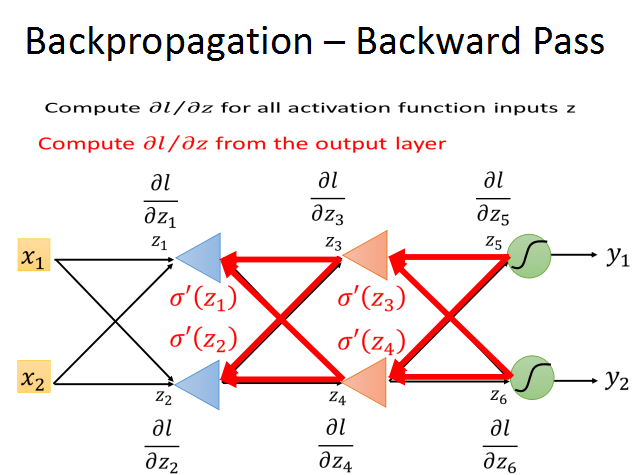
所以,我们就可以从输出层开始,反向计算l对每层z的梯度,在结合前向传播得到的梯度,就可以计算出梯度下降所需的梯度了。
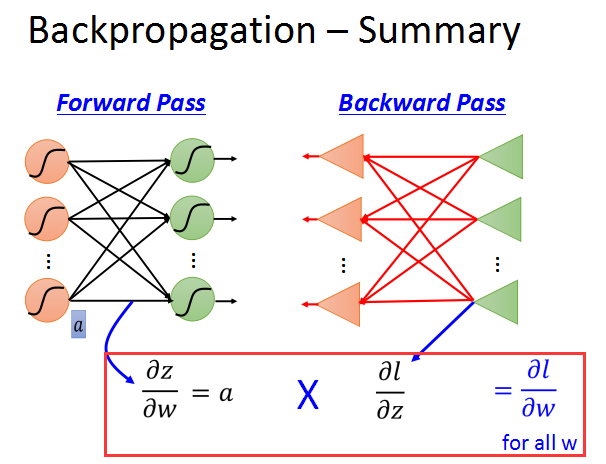
而且,反向传播的复杂度和前向传播是一样的,这样就大大提升了梯度计算的效率。后一层的梯度,乘以相应的w,相加再乘上σ‘(z),就得到了当前层的l/z的梯度。
最后结果就是这样的:
后向传播算法“backpropragation”详解的更多相关文章
- 一致性算法RAFT详解
原帖地址:http://www.solinx.co/archives/415?utm_source=tuicool&utm_medium=referral一致性算法Raft详解背景 熟悉或了解 ...
- 各大公司广泛使用的在线学习算法FTRL详解
各大公司广泛使用的在线学习算法FTRL详解 现在做在线学习和CTR常常会用到逻辑回归( Logistic Regression),而传统的批量(batch)算法无法有效地处理超大规模的数据集和在线数据 ...
- 转】Mahout推荐算法API详解
原博文出自于: http://blog.fens.me/mahout-recommendation-api/ 感谢! Posted: Oct 21, 2013 Tags: itemCFknnMahou ...
- MD5算法步骤详解
转自MD5算法步骤详解 之前要写一个MD5程序,但是从网络上看到的资料基本上一样,只是讲了一个大概.经过我自己的实践,我决定写一个心得,给需要实现MD5,但又不要求很高深的编程知识的童鞋参考.不多说了 ...
- [转]Mahout推荐算法API详解
Mahout推荐算法API详解 Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeepe ...
- 2. EM算法-原理详解
1. EM算法-数学基础 2. EM算法-原理详解 3. EM算法-高斯混合模型GMM 4. EM算法-高斯混合模型GMM详细代码实现 5. EM算法-高斯混合模型GMM+Lasso 1. 前言 概率 ...
- [置顶]
Isolation Forest算法实现详解
本文算法完整实现源码已开源至本人的GitHub(如果对你有帮助,请给一个 star ),参看其中的 iforest 包下的 IForest 和 ITree 两个类: https://github.co ...
- [置顶]
Isolation Forest算法原理详解
本文只介绍原论文中的 Isolation Forest 孤立点检测算法的原理,实际的代码实现详解请参照我的另一篇博客:Isolation Forest算法实现详解. 或者读者可以到我的GitHub上去 ...
- javascript常用经典算法实例详解
javascript常用经典算法实例详解 这篇文章主要介绍了javascript常用算法,结合实例形式较为详细的分析总结了JavaScript中常见的各种排序算法以及堆.栈.链表等数据结构的相关实现与 ...
随机推荐
- 使用shell脚本守护node进程
现在开源的守护node进程的包有不少,比如forever,pm2,这里我就不再赘述了. 但是有的公司生产服务器是不能联网的,而这些包都需要全局安装,必须要网络环境.难道你nohup node app. ...
- 《从零开始学Swift》学习笔记(Day 38)——构造函数与存储属性初始化
原创文章,欢迎转载.转载请注明:关东升的博客 构造函数的主要作用是初始化实例,其中包括:初始化存储属性和其它的初始化.在Rectangle类或结构体中,如果在构造函数中初始化存储属性width和hei ...
- jquery lazyload延迟加载技术的实现原理分析_jquery
前言 懒加载技术(简称lazyload)并不是新技术,它是js程序员对网页性能优化的一种方案.lazyload的核心是按需加载.在大型网站中都有lazyload的身影,例如谷歌的图片搜索页,迅雷首页, ...
- Neighbor Discovery Protocol Address Resolution Protocol
https://en.wikipedia.org/wiki/Address_Resolution_Protocol The Address Resolution Protocol (ARP) is a ...
- HashMap 扩容机制
引用于: http://www.cnblogs.com/hongdada/p/6024832.html HashMap: public HashMap(int initialCapacity, flo ...
- 什么是 C++ 11 原始字符串?
std::string path = "C:\\VulkanSDK";//需要转义 std::string path = R"(C:\VulkanSDK)";/ ...
- 兼容ie的background-size: cover;
.bg{ background: url() no-repeat; background-size:cover; filter: progid:DXImageTransform.Microsoft.A ...
- fecha的使用
项目中时间的处理是无法避免的,时间的处理方式有很多,这里介绍一下fecha的使用 fecha是一个日期格式化和解析的js库,它提供了强大的日期处理功能,功能强大且只有2k大小.安装方式简单,只需要 n ...
- MySQL中myisam和innodb的主键索引有什么区别?
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址.下图是MyISAM索引的原理图: 这里设表一共有三列,假设我们以Col1为主键,则上图是一个MyISAM表的主索 ...
- linux下查看cpu,内存,硬盘等硬件信息的方法
说明:Linux下可以在/proc/cpuinfo中看到每个cpu的详细信息.但是对于双核的cpu,在cpuinfo中会看到两个cpu.常常会让人误以为是两个单核的cpu. 一.linux CPU大小 ...