LeNet5
Lecun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11):2278-2324.(Ⅰ.induction ⅡConvolutional Neural Networks For Isolated Character Recognition)
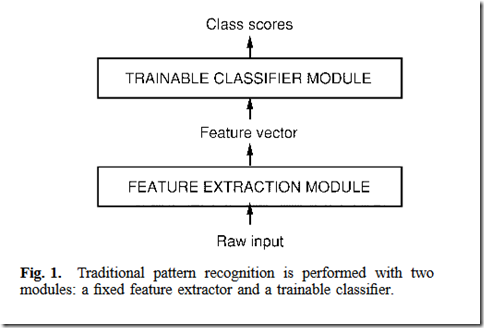
传统的模式识别方法
1.人工设计的特征提取方法+分类器(可以是全连接神经网络)
1.1. 图像–特征提取–>特征–分类器–>数字类别
1.2. 缺点:需要手动设计特征提取方法,通常对于不同的问题需要不同的特征提取方法。而且效果与特征提取方法关系很大。
2.直接处理图像的全连接神经网络(raw input)
2.1. 图像–全连接神经网络–>数字类别
2.2. 缺点:
a. 参数数量爆炸(起码与图像像素数目成正比):需要大数据集,难以收敛,容易过拟合,会超内存。
b. 不保证对旋转以及局部扭曲的无关性,需要数字图像居中才可以得到较好的准确度(通常难以满足)。理论上全连接可以得到旋转以及局部扭曲不变性,即在不同位置都有一个相似的权值单元,但是需要大量的局部移动的训练样本)。
c. 忽略了图像的拓扑结构,任意打乱图像的像素顺序不会影响训练结果
为什么Convolution
1.位移不变性:论文中不单单指图像,还指出语音,在这些应用中,它们的input的数据不可能在输入到网络前,进行预处理将这些数据完美地摆在输入的正中央,因此需要模型具有一种位移不变性,即 即使在训练集中没有图片的某个位置都没有出现过目标物,在测试时仍能将在这个位置上的目标物识别出来,语音处理也同理。
2.保持拓扑结构:空间相邻的像素具有高度相关性,需要保持图像中的拓扑结构。
3.稀疏性:避免像全连接网络那样那么多参数,降低模型复杂度,从而减少variance
据此产生了卷积的三个性质:
1.权值共享:对于同一卷积核,图片上不同位置处的参数(权重)是一样的
2.局部感受野:每个感受野里的像素点都是有空间结构的
3.空间或时间上的下采样:“因为对于不同的手写体字符,位置会经常变动。在特征图中降低特征位置的精度的方式是降低特征图的空间分辨率,这个可以通过下采样层达到,下采样层通过求局部平均降低特征图的分辨率,并且降低了输出对平移和形变的敏感度。”(原文)
总结:总之,卷积+下采样目的就是保证空间和时间结构,并且尽可能保证位移,缩放,和形变的不变性(shift,scale,distortion invariance)。如果对图像做平移,那么对应于高层特征的平移(因为权值共享);如果对图像做局部旋转,小范围旋转/扭曲会被局部感受野消除,大范围扭曲会因为降采样而模糊掉其影响。
但是事实上,在有些实验中,会对训练图像进行一定程度上地空间变换,以提高数据的健壮性。这从侧面也说明,上面提到的位移,缩放和形变只能尽可能保证不变。
:

第1层 卷积层
输入图片尺寸:32x32x1;
输出图片尺寸:28x28x6;(filter=5*5, strides=1, padding='VALID')
卷积层参数:5x5x1x6+6=156个参数,其中6个为偏置参数;
卷积层连接:(5x5+1)x28x28x6=122304个连接。
第2层 池化层
输入图片尺寸:28x28x6;
输出图片尺寸:14x14x6;(filter=2*2, strides=2, padding='SAME')
池化层参数:2x6=12个参数;
池化层连接:(4+1)x14x14x6=5880个连接。
第3层 卷积层
输入图片尺寸:14x14x6;
输出图片尺寸:10x10x16;(filter=5*5, strides=1, padding='VALID')
卷积层参数:(5x5x3+1)x6 + (5x5x4 + 1) x 3 + (5x5x4 +1)x6 + (5x5x6+1)x1 = 1516个参数;
卷积层连接:1516x10x10=151600个连接。
Note: C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。这样C3层有1516个可训练参数和151600个连接。
第4层 池化层
输入图片尺寸:10x10x16;
输出图片尺寸:5x5x16;(filter=2*2, strides=2, padding='SAME')
池化层参数:2x16=32个参数;
池化层连接:(4+1)x5x5x16=2000个连接。
第5层 卷积层(实质上因为滤波器大小为5x5,等价于全连接层)
输入图片尺寸:5x5x16;
输出图片尺寸:1x1x120;
卷积层参数:(5x5x16+1)x120=48120个参数;
卷积层连接:(5x5x16+1)x120=48120个连接,与参数大小一致。
第6层 全连接层
输入图片尺寸:1x1x120;
输出图片尺寸:1x1x84;
全连接层参数:(120+1)x84=10164个参数;
全连接层连接:(120+1)x84=10164个连接,与参数大小一致。
第7层 全连接层
输入图片尺寸:1x1x84;
输出图片尺寸:1x1x10;
全连接层参数:(84+1)x10=850个参数;
全连接层连接:(84+1)x10=850个连接,与参数大小一致。
LeNet5的更多相关文章
- 卷积神经网络的初步理解LeNet-5(转)
深度神经网路已经在语音识别,图像识别等领域取得前所未有的成功.本人在多年之前也曾接触过神经网络.本系列文章主要记录自己对深度神经网络的一些学习心得. 第二篇,讲讲经典的卷积神经网络.我不打算详细描述卷 ...
- 深度学习——卷积神经网络 的经典网络(LeNet-5、AlexNet、ZFNet、VGG-16、GoogLeNet、ResNet)
一.CNN卷积神经网络的经典网络综述 下面图片参照博客:http://blog.csdn.net/cyh_24/article/details/51440344 二.LeNet-5网络 输入尺寸:32 ...
- LeNet-5识别MINIST数据集
LeNet-5 LeNet于90年代被提出,鉴于当时的计算能力和内存容量,直到2010年才能真正的实施这样的大规模计算.LeNet-5是LeCun于1998年提出的深度神经网络结构,总共包含7层网络( ...
- 经典卷积神经网络结构——LeNet-5、AlexNet、VGG-16
经典卷积神经网络的结构一般满足如下表达式: 输出层 -> (卷积层+ -> 池化层?)+ -> 全连接层+ 上述公式中,“+”表示一个或者多个,“?”表示一个或者零个,如“卷积层+ ...
- tensorFlow入门实践(三)实现lenet5(代码结构优化)
这两周我学习了北京大学曹建老师的TensorFlow笔记课程,认为老师讲的很不错的,很适合于想要在短期内上手完成一个相关项目的同学,课程在b站和MOOC平台都可以找到. 在卷积神经网络一节,课程以le ...
- 第十三节,卷积神经网络之经典网络LeNet-5、AlexNet、VGG-16、ResNet(三)(后面附有一些网络英文翻译文章链接)
一 实例探索 上一节我们介绍了卷积神经网络的基本构建,比如卷积层.池化层以及全连接层这些组件.事实上,过去几年计算机视觉研究中的大量研究都集中在如何把这些基本构件组合起来,形成有效的卷积神经网络.最直 ...
- lenet-5
https://blog.csdn.net/happyorg/article/details/78274066 深度学习 CNN卷积神经网络 LeNet-5详解 2017年10月18日 16:04:3 ...
- Tensorflow实现LeNet-5、Saver保存与读取
一. LeNet-5 LeNet-5是一种用于手写体字符识别的非常高效的卷积神经网络. 卷积神经网络能够很好的利用图像的结构信息. 卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定 ...
- 卷积神经网络入门:LeNet5(手写体数字识别)详解
第一张图包括8层LeNet5卷积神经网络的结构图,以及其中最复杂的一层S2到C3的结构处理示意图. 第二张图及第三张图是用tensorflow重写LeNet5网络及其注释. 这是原始的LeNet5网络 ...
- [Model] LeNet-5 by Keras
典型的卷积神经网络. 数据的预处理 Keras傻瓜式读取数据:自动下载,自动解压,自动加载. # X_train: array([[[[ 0., 0., 0., ..., 0., 0., 0.], [ ...
随机推荐
- ace admin 下拉选择Multiple-select组件
一.组件说明以及API 1.第一个组件是写bootstrap table的主人公 wenzhixin 封装的一个组件—— multiple-select.这个组件风格简单.文档全.功能强大.但是觉得它 ...
- MVC 的八个扩展点
Asp.net MVC中常用的八个扩展点并举例说明. 一.ActionResult ActionResult代表了每个Action的返回结果.asp.net mvc提供了众多内置的ActionResu ...
- zendstdio的智能提示功能
在项目的include的那个地方邮寄,在addsource file 然后指向TP类库的文件夹,刷新项目即可有智能提示
- Django学习之项目结构优化
其实就是采用包结构,比如: 目录models,包含__init__.py,a.py,b.py 然后将model class写在a和b中,但是这样的话,导入时就要改变了! from models imp ...
- 基于OAuth2.0的统一身份认证中心设计
1. 引言 公司经历多年发展后,在内部存在多套信息系统,每套信息系统的作用各不相同,每套系统也都拥有自己独立的账号密码权限体系,这时,每个人员都需要记住不同系统的账号密码,人员入职和离职时,人事部门都 ...
- js基础系列框架图 (转载)
- PCB焊接工艺
1. 有铅焊接工艺 240~260℃. 2. BGA焊盘直径为球径80%.
- linux 个人测试用例
1. 我想在某个目录下, 找到某个文件中有某个字符(leon)的文件, 并列出来? (如果是在windows下, 可能需要一个文件一个文件的看, 但是在 linux 下可以实现) find . –ma ...
- Python 爬虫实战2 百度贴吧帖子
爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖内容 将抓取到的内容分析并保存到文件 1.URL格式的确定 首先, ...
- ActiveMQ部署步骤和后台管理网站Service Unavailable问题解决笔记
最近部署ActiveMQ的时候,发现有的服务器可以打开后台管理网址,有的服务器无法打开,Jetty报503 Service Unavailable. 搞了很久终于发现了问题,现将部署和解决过程做笔记如 ...