1.hadoop环境搭建以及配置
提前说明一下:由于环境的配置搞得我很头疼,所以记录下来。并不是零基础,像hadoop的由来、发展史、结构、各个组件,这里都没有介绍,只是为了自己能够在忘了的时候回忆起来,所以记录下来
如何在linux上安装hadoop
首先我这里使用的是Ubuntu18.04,64位系统
1.安装jdk
由于hadoop是由java编写的,所以需要安装jdk。我这里使用的是jdk1.8.0,安装路径为/usr/local/java/jdk1.8.0_191/
配置环境变量,在 ~/.bashrc尾部添加如下内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export PATH=$JAVA_HOME/bin:$PATH
然后source ~/.bashrc激活
最后在终端中输入java -version,显示如下,说明配置成功

2.安装Hadoop
在安装hadoop之前,我们先安装一下ssh和rsync
apt-get install ssh
apt-get install rsync
然后配置免密码登录,因为我们的datanode和namenode之间是要进行进程通信的。可以使用以下方式配置
ssh-keygen -t rsa,一路回车即可,然后文件自动会保存在当前用户下的.ssh文件下
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys,将id_rsa.pub文件里的内容拷贝到authorized_keys文件里
这样登陆过一次之后就可以免密码登录了
接下来下载hadoop
这里我们使用hadoop的发行版,cdh,下载链接在http://archive.cloudera.com/cdh5/cdh/5/,这个发行版的好处就在于可以避免jar包的冲突。

以上便是hadoop-cdh的文件结构,我们进入./etc/hadoop目录下看看
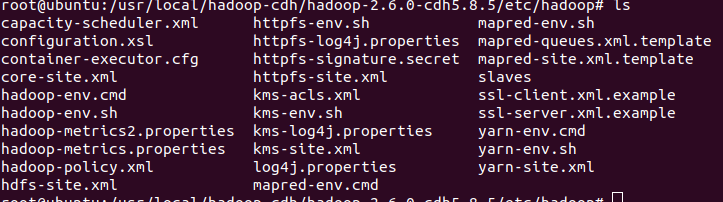
这里面有很多的配置文件,这些配置文件非常重要,hadoop的配置所以才说麻烦,我们慢慢介绍
再来看看sbin目录下的文件
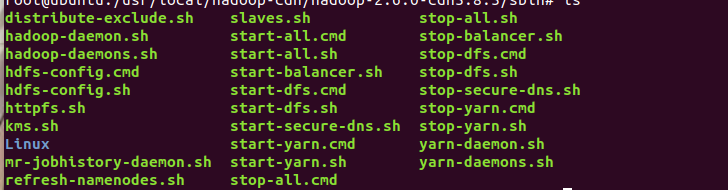
sbin目录下有很多的启动文件,启动dfs、yarn等等,当然有启动就有停止。
接下来便要修改配置文件了,进入./etc/hadoop下
首先修改hadoop-env.sh

然后修改core-site.xml

再次打开文件
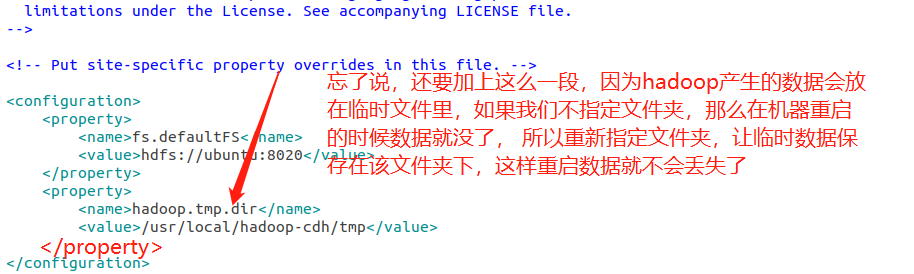
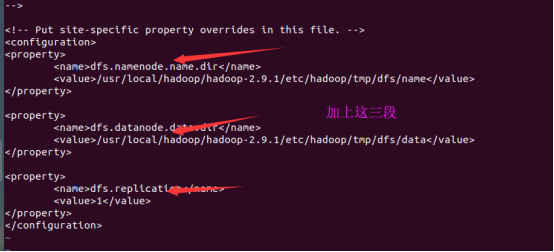
然后修改hdfs-site.xml

接下来修改slaves这个文件,对于我们目前的伪分布式目前是没有什么作用的,但是对于我们理解hadoop集群是有帮助的。我们知道一个namenode带多个datanode,那么datanode的hostname或者ip在哪,有多少个呢?就是配置在slaves文件里面。
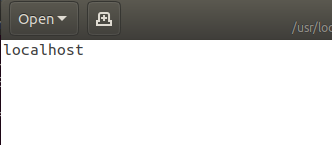
里面只有一个localhost,当然我们写成ubuntu也是可以的,因为我们的主机名就叫ubuntu
接下来启动hdfs
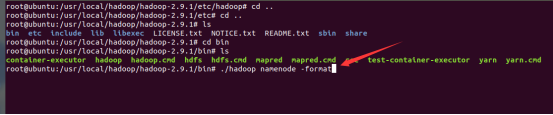
首先格式化文件系统(仅第一次执行即可,因为每执行一次,相当于格式化一次,hdfs上的数据也就被我们清空了),hdfs namenode -format
我们进入bin目录下执行格式化操作


执行成功,来看看有没有tmp目录

看看有没有内容
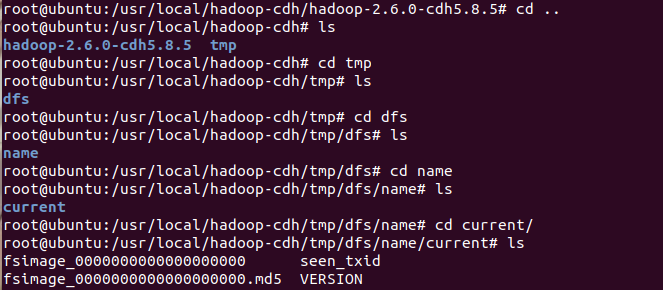
然后启动hadoop,直接执行sbin目录下的start-dfs.sh即可
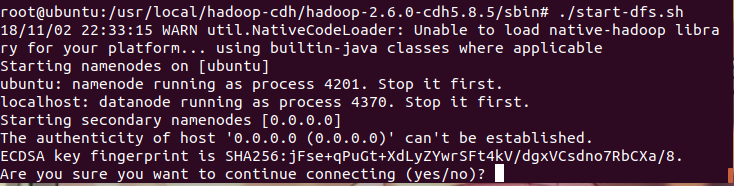
出现界面如下,直接输入yes即可

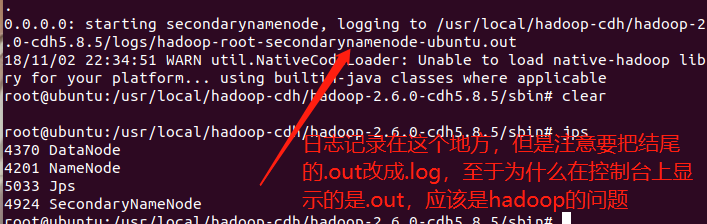
显示配置成功,我们查看当前的进程

显示如下
如果出现进程少了的情况,那么说明配置文件出了问题,那么可以去记录日志的文件里面查看,那么日志记录在哪呢?
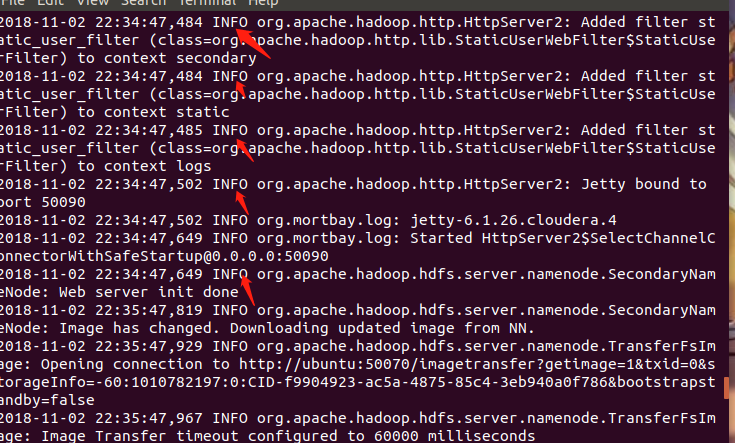
查看之后,显示的都是info,说明是正常输出,如果出错,会出现error
以上是通过查看日志文件,那么能不能通过浏览器查看呢?显然是可以的
输入http://ubuntu:50070即可,再次强调这里的ubuntu是我的主机名,你在终端中输入hostname,显示的啥就输入啥。至于端口为什么不是8020,8020是我们启动的时候用的,使用浏览器要通过50070访问
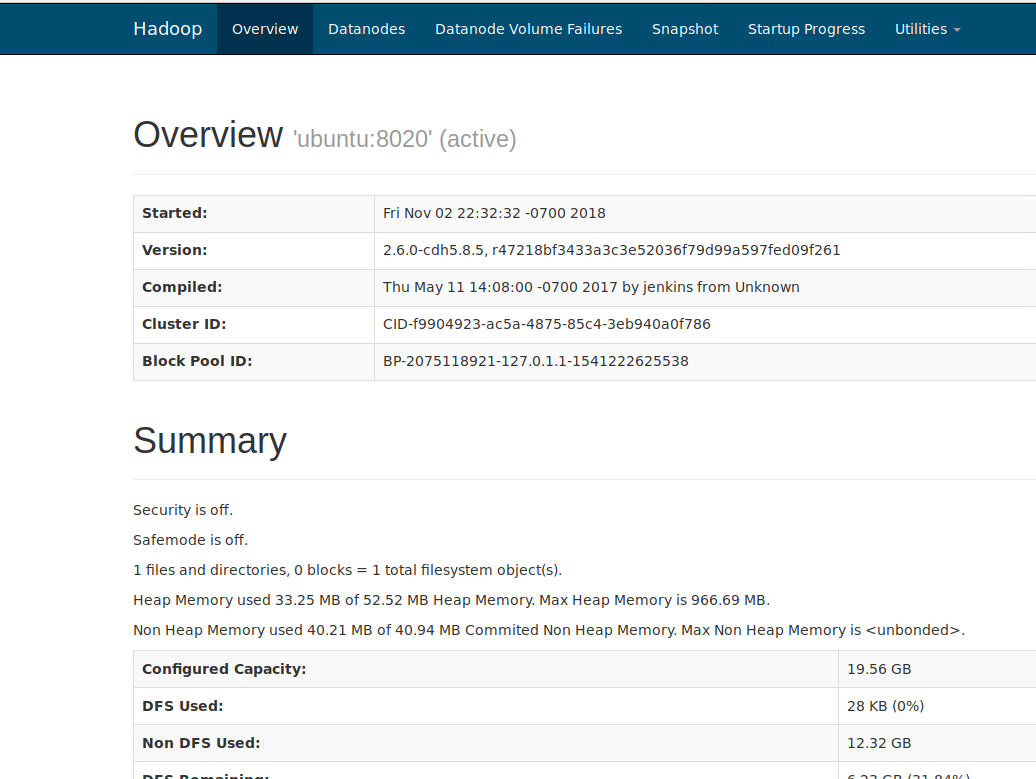
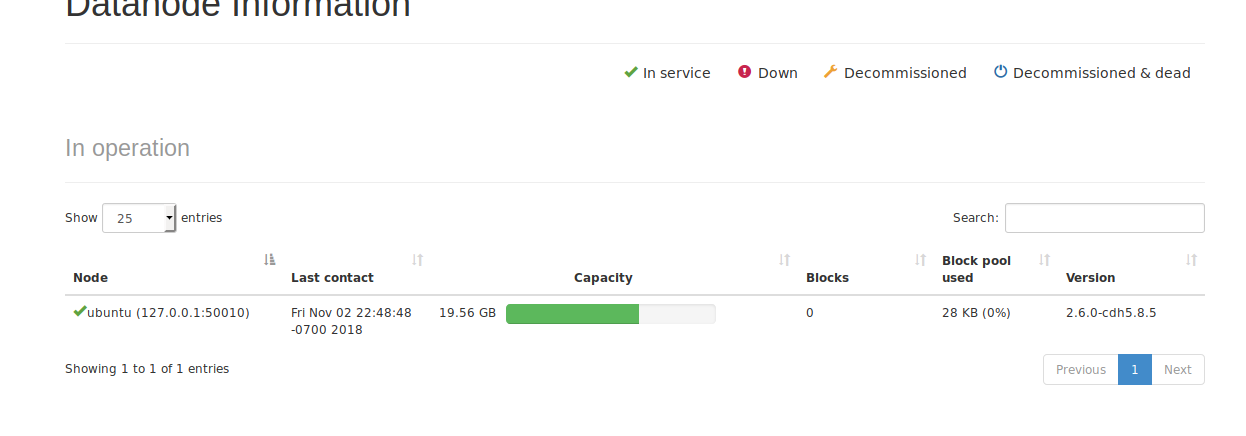
里面包含很多信息,包括你的节点,数量等等

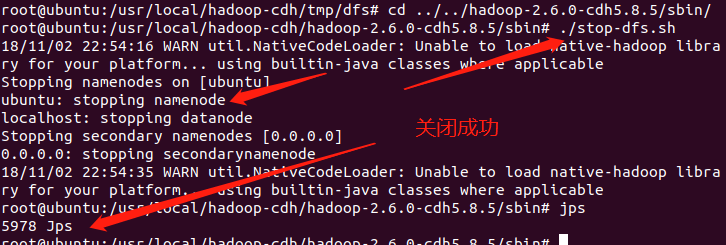
那么启动既然成功了,停止该怎么办呢?直接进入sbin目录下,执行./stop-dfs.sh即可
hdfs shell常用命令的使用
主要命令有:ls mkdir put get rm,和linux shell非常相似
前面忘记说了,建议把hadoop的bin目录配置到环境变量里面去,我这里已经配置好了
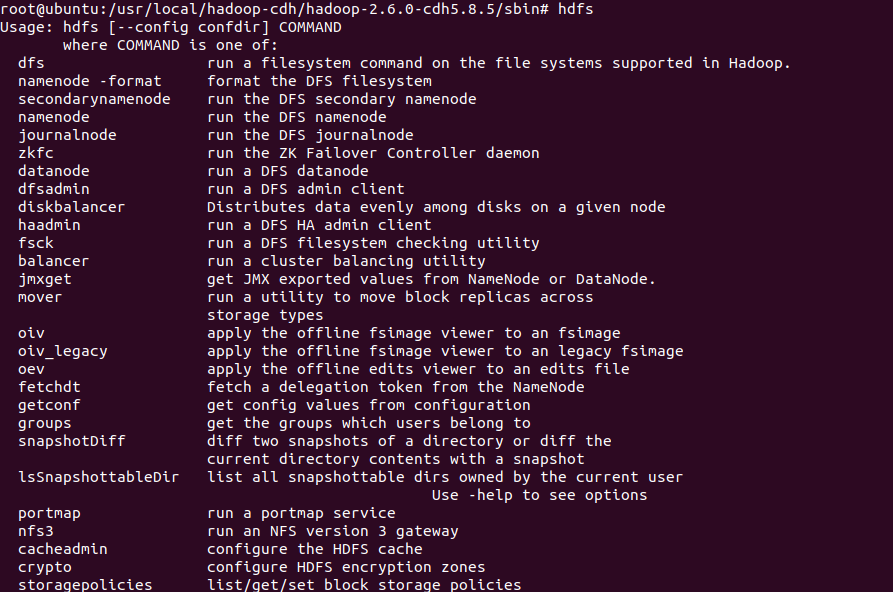
这便是hadoop shell的常用命令,比方说第二个namenode -format是不是很熟悉,我们之前用来格式化hadoop文件系统的
再来看看第一个命令dfs,可以在支持hadoop的文件系统上运行文件系统命令,我们执行hdfs dfs看一下
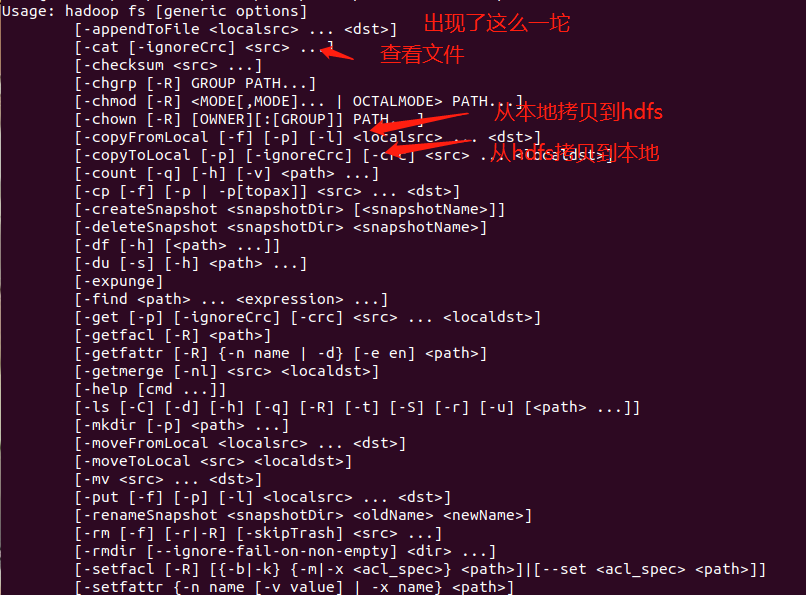
里面的命令很多和linux是相似的,而且从参数名也能看出来作用
下面我们就来试一试吧,我在桌面上创建了一个hello.txt文件
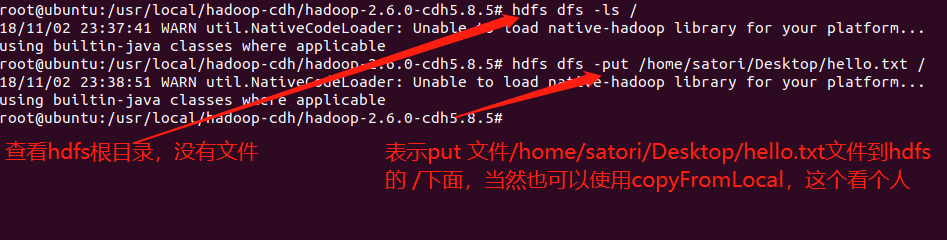

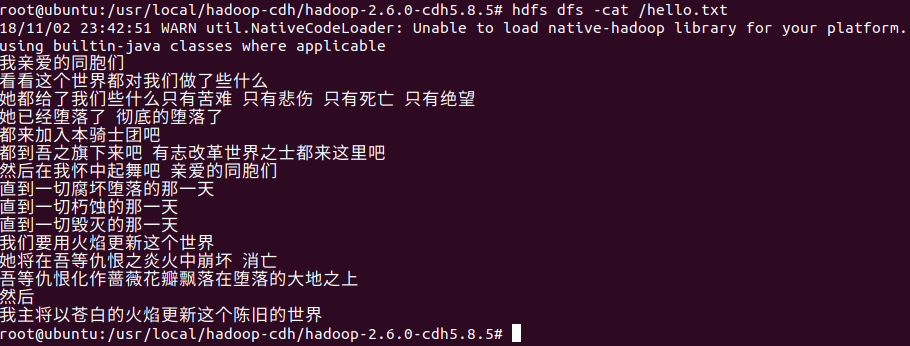
我们打开看一看,既然文件已经上传到了hdfs,那么我们就可以直接使用hdfs shell命令打开它,使用hdfs dfs -cat xxx,可以发现和linux基本命令是保持一致的,只不过在hdfs shell中命令要加上一个-。
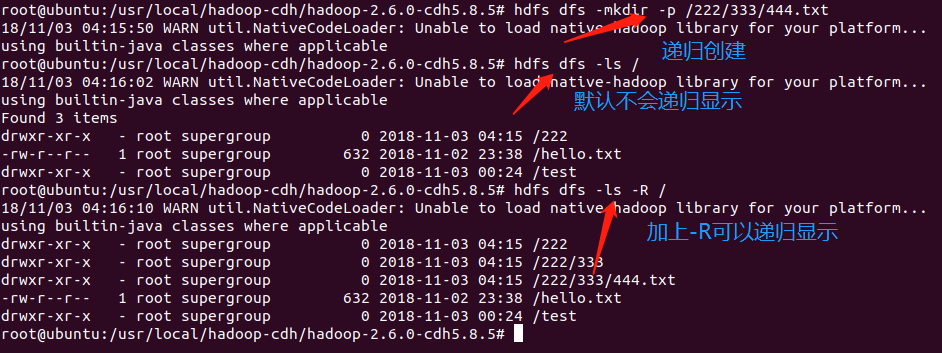
如果我们想创建一个目录呢?在linux上是mkdir,那么同理在hadoop上是hdfs dfs -mkdir,如果想递归创建,那么使用hdfs dfs -mkdir -p即可

如果递归显示文件目录,使用hdfs dfs -ls -R
之前展示了把本地文件复制到hdfs上面来,那么我要把hdfs的文件放到本地上面去怎么办呢?使用get

 虽然是mmp.txt,但mkdir只能创建目录,所以这里还是一个目录
虽然是mmp.txt,但mkdir只能创建目录,所以这里还是一个目录
那么删除一个文件怎么办呢?显然熟悉linux应该能猜到,hdfs dfs -rm xxx,但是这个只能删除文件,如果想删除文件夹,hdfs dfs -rm -R XXX
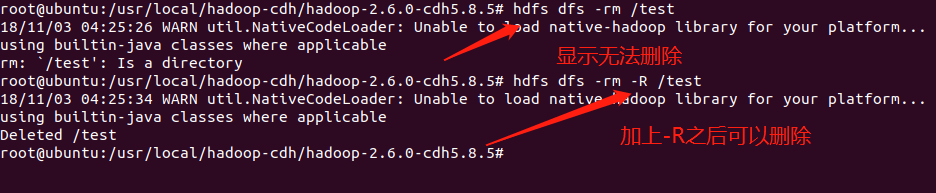
我们进入浏览器页面
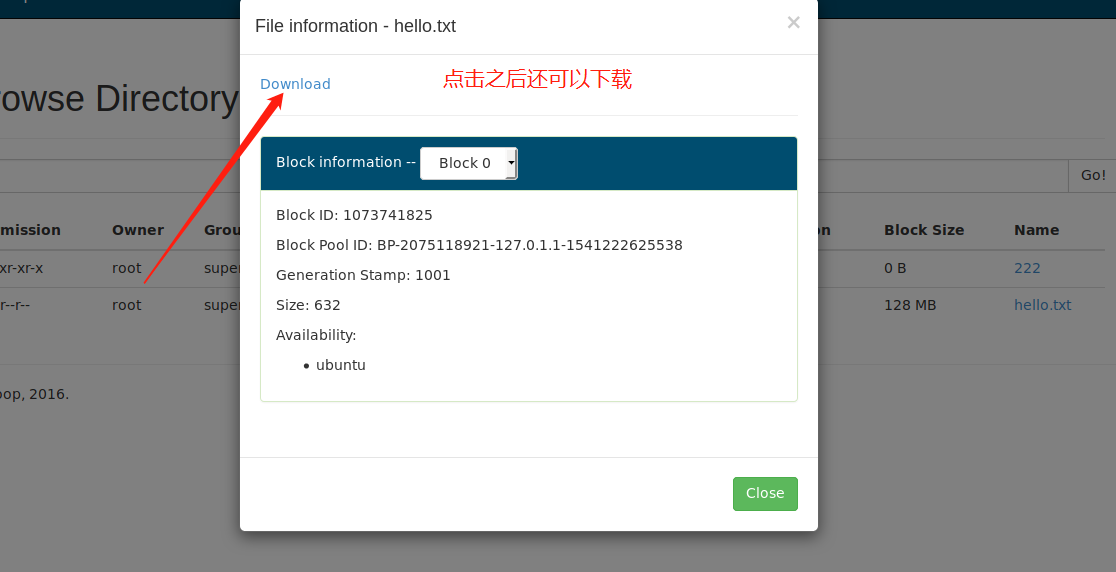
这里的block0表示只有一个block,为什么呢?因为文件没有分块,默认是128M,我们这里的文件就几百字节,所以无需分块
基本命令就讲到这里,至于其他的需要时可以直接输入hdfs dfs查找即可
3.安装maven
然后配置环境变量,
export MAVEN_HOME=/usr/local/maven/apache-maven-3.6.0
export PATH=$MAVEN_HOME/bin:$PATH
-------------------------------pass------------------------------
显示版本2.9.1
这里还需要修改一些其他的配置文件,进入到$HADOOP_HOME/etc/hadoop中。

首先修改hadoop-env.sh
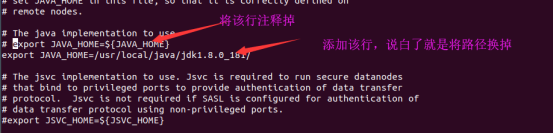
然后修改core-site.xml
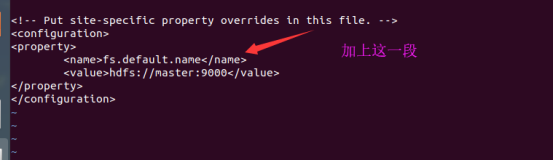
然后修改hdfs-site.xml
然后修改mapred-site.xml,由于没有这个文件,但有mapred-site.xml.template这个文件,所以我们拷贝一份。

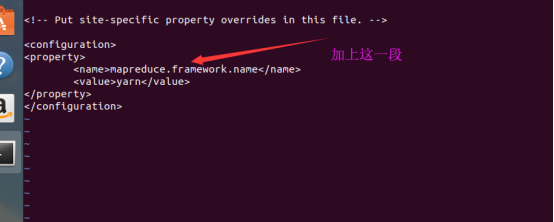
然后配置yarn-site.xml
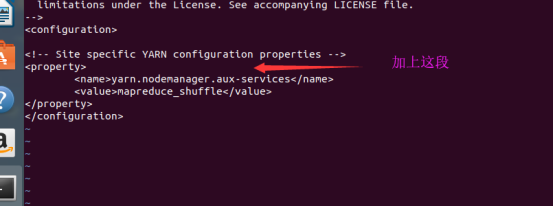
配置完成
接下来格式化一下
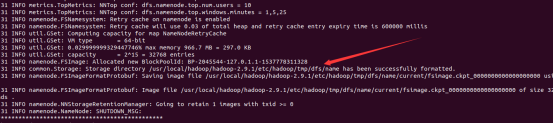
格式化成功,看一下相应的目录
可以看到之前新建的空目录,里面已经有东西了。
如果需要密码,就输入这两行,就可以免密码登陆了
最后启动一下hadoop
ssh-keygen -t rsa -P
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys

4.安装maven
我安装到了/usr/local/java目录下,然后在~/.bashrc中配置环境变量
export JAVA_HOME=/usr/local/java/jdk1.8.0_181
export PATH=$JAVA_HOME/bin:$PATH
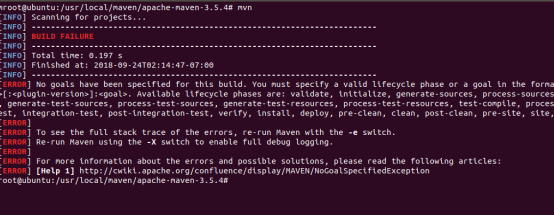
输入mvn输出如下,说明安装成功
5.安装python
直接apt-get install python3即可
6.安装spark
我安装到了/usr/local/目录下,然后在~/.bashrc中配置环境变量
export SPARK_HOME=/usr/local/spark/spark-2.3.1-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$PATH

输入pyspark成功进入。
1.hadoop环境搭建以及配置的更多相关文章
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- 【转】RHadoop实践系列之一:Hadoop环境搭建
RHadoop实践系列之一:Hadoop环境搭建 RHadoop实践系列文章,包含了R语言与Hadoop结合进行海量数据分析.Hadoop主要用来存储海量数据,R语言完成MapReduce 算法,用来 ...
- hadoop环境搭建之关于NAT模式静态IP的设置 ---VMware12+CentOs7
很久没有更新了,主要是没有时间,今天挤出时间验证了一下,果然还是有些问题的,不过已经解决了,就发上来吧. PS:小豆腐看仔细了哦~ 关于hadoop环境搭建,从单机模式,到伪分布式,再到完全分布式,我 ...
- eclipse工具下hadoop环境搭建
eclipse工具下hadoop环境搭建: window10操作系统中搭建eclipse64开发系统,配置hadoop的eclipse插件,让eclipse可以查看Hdfs中的文件内容. ...
- 大数据学习之Hadoop环境搭建
一.Hadoop的优势 1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理. 2)高扩展性:在集群间分配任务数据,可方便的 ...
- Hadoop环境搭建、启动和管理界面查看
一.hadoop环境搭建: 1. hadoop 6个核心配置文件的作用:core-site.xml:核心配置文件,主要定义了我们文件访问的格式 hdfs://hadoop-env.sh:主要配置我们的 ...
- Ubuntu中Hadoop环境搭建
Ubuntu中Hadoop环境搭建 JDK安装 方法一:通过命令行直接安装(不建议) 有两种java可以安装oracle-java8-installer以及openjdk (1)安装oracle-ja ...
- Linux集群搭建与Hadoop环境搭建
今天是8月19日,距离开学还有15天,假期作业完成还是遥遥无期,看来开学之前的恶补是躲不过了 今天总结一下在Linux环境下安装Hadoop的过程,首先是对Linux环境的配置,设置主机名称,网络设置 ...
- 转 史上最详细的Hadoop环境搭建
GitChat 作者:鸣宇淳 原文:史上最详细的Hadoop环境搭建 关注公众号:GitChat 技术杂谈,一本正经的讲技术 [不要错过文末活动哦] 前言 Hadoop在大数据技术体系中的地位至关重要 ...
随机推荐
- ISAP 最大流 最小割 模板
虽然这道题用最小割没有做出来,但是这个板子还是很棒: #include<stdio.h> #include<math.h> #include<string.h> # ...
- 剑指offer:正则表达式匹配
目录 题目 解题思路 具体代码 题目 题目链接 剑指offer:正则表达式匹配 题目描述 请实现一个函数用来匹配包括'.'和'*'的正则表达式.模式中的字符.表示任意一个字符,而*表示它前面的字符可以 ...
- exec族
在之前我们已经知道用fork创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支),子进程往往要调用一种exec函数以执行另一个程序.当进程调用一种exec函数时,该进程的用户空间代码和 ...
- lintcode-99-重排链表
99-重排链表 给定一个单链表L: L0→L1→-→Ln-1→Ln, 重新排列后为:L0→Ln→L1→Ln-1→L2→Ln-2→- 必须在不改变节点值的情况下进行原地操作. 样例 给出链表 1-> ...
- jsp中的session和上下文
Session的典型应用: 防止用户非法登录到某个页面. 网上商城的购物车 保存用户登录信息 注:多个请求要用的东西放在session中,多个会话之间要用的东西放在上下文中. 如何创建session? ...
- hadoop 集群常见错误解决办法
hadoop 集群常见错误解决办法 hadoop 集群常见错误解决办法: (一)启动Hadoop集群时易出现的错误: 1. 错误现象:Java.NET.NoRouteToHostException ...
- P1717 钓鱼
题目描述 话说发源于小朋友精心设计的游戏被电脑组的童鞋们藐杀之后非常不爽,为了表示安慰和鼓励,VIP999决定请他吃一次“年年大丰收”,为了表示诚意,他还决定亲自去钓鱼,但是,因为还要准备2013NO ...
- 国内各运营商(ISP)IP段表
国内各运营商(ISP)IP段表 来源:http://bbs.hh010.com/forum.php?mod=viewthread&tid=490529&orderby=dateline ...
- BZOJ_DAY6???
昨天没睡好啊啊啊,真是要命,睡不着,今天状态爆炸...34题击破. 下一步目标:网络流24题,树链剖分. (洛谷比赛了好开心,希望这次能比以前强吧,嗯)
- 【BZOJ 3505】 [Cqoi2014]数三角形 容斥原理+排列组合+GCD
我们先把所有三角形用排列组合算出来,再把一行一列上的三点共线减去,然后我们只观察向右上的三点共线,向左上的乘二即可,我们发现我们如果枚举所有的两边点再乘中间点的个数(GCD),那么我们发现所有的两边点 ...