Python之路Python文件操作
Python之路Python文件操作
一、文件的操作
文件句柄 = open('文件路径+文件名', '模式')
例子
f = open("test.txt","r",encoding = “utf-8”)
分析:这里由于python文件和test.txt文件在同一文件夹里,不需要写test的绝对路径
如果要写绝对路径可以这样写
f = open(file = "d:/python/test.txt","r",encoding = “utf-8”)
文件打开模式有以下几种模式
1、文本文件的打开模式
“r” ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
“w”, 只写模式【不可读;不存在则创建;存在则清空内容】
"a",只追加写模式【不可读;不存在则创建;存在则只追加内容】
就是以二进制的方式打开文件,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
"+" 表示可以同时读写某个文件
"r+",读写【可读,可写】
"w+",写读【可读,可写】
"a+",写读【可读,可写】
2、readable()、writable()
readable()判断文件是否可读,返回True或者False,
writable()判断文件是否可写,返回True或者False,
例子
f.readable()
f.writable()
3、read()、readline() 、readlines()
f.read() #读取所有内容,光标移动到文件末尾
字符串的形式返回结果,read([size])方法从文件当前位置起读取size个字节,若无参数size,则表示读取至文件结束为止
f.readline() #读取一行内容,光标移动到第二行首部
以字符串的形式返回结果
f.readlines() #读取每一行内容,存放于列表中
读取文本所有内容,将每一行作为一个列表的元素,并且以列表的格式返回结果,但读取大文件会比较占内存。
4、write()、writelines( )
write()要写入字符串
writelines()既可以传入字符串又可以传入一个字符序列,并将该字符序列写入文件。 注意必须传入的是字符序列,不能是数字序列。
f.write('1111\n222\n') #针对文本模式的写,需要自己写换行符
f.write('1111\n222\n'.encode('utf-8')) #针对b模式的写,需要自己写换行符
f.writelines(['333\n','444\n']) #文件模式
f.writelines([bytes('333\n',encoding='utf-8'),'444\n'.encode('utf-8')]) #b模式
5、f.close() #关闭文件f.closed()#查看文件是否关闭
用open方法打开文件后,必须用f.close()关闭文件
文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的。
f.closed()#查看文件是否关闭,返回True或者False
6、with open as f打开方法
这种打开文件的方式不用写f.closed关闭文件
例子
with open('/path/to/file', 'r') as f:
with open("test.txt","r",encoding = “utf-8”) as f:
7、 对于非文本文件,我们只能使用b模式
非文本文件的打开模式,只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式,b模式可以跨平台使用)
"rb"
"wb"
"ab"
f = open("test.py","rb")
分析:注意这里不能在加,encoding = “utf-8”,因为这里是以二进制的方式打开,不需要再设置打开的编码方式
例子
f = open("test.py","rb")
data = f.read()
print(data)
test.py文件内容:
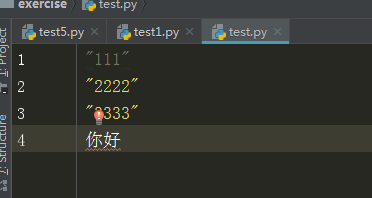
输出
b'"111"\r\n"2222"\r\n"3333"\r\n\xe4\xbd\xa0\xe5\xa5\xbd'
分析:这里的\r\n是Windows平台的换行,以b开头代表输出的是字节形式
这里的\xe4\xbd\xa0\xe5\xa5\xbd'代表汉字
f = open("test.py","rb")
data = f.read()
print(data.decode("utf-8"))
输出结果
""
""
""
你好
分析:这里在test.py文件存储时用的是utf-8存储的,在打印输出的时候以"utf-8"进行解码即可输出结果。
以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
例子2
f = open("test11.py","wb")f.write("111\n")
f.close()
输出结果:出错,提示这里需要字节,而不是字符串形式,这里写入必须以字节形式写入
可改为
f = open("test11.py","wb")
f.write(bytes("111\n",encoding="utf-8"))
f.close()
分析:这里就可以把字符串“111\n”写入文件了,这里bytes()一定要指定一个编码。
或者直接对字符串进行编码,不用bytes()方法
f = open("test11.py","wb")
f.write("222\n".encode("utf-8"))
f.close()
8、f.encoding
取文件打开的编码
例子
f = open("test11.py","w",encoding="gbk")
f.write("222\n")
f.close()
print(f.encoding)
输出
gbk
分析:这里取的是文件打开的编码,即open语句里的编码,与源文件实际的编码无关。
9、f.flush() 、f.tell()
f.flush() 立刻将文件内容从内存刷到硬盘,这里需要用命令提示行操作,在pycharm里会直接将写入内容写入硬盘,不需要flush()
f.tell()获取当前光标所在的位置
10、文件内光标移动
read(3):
a、文件打开方式为文本模式时,代表读取3个字符
b、文件打开方式为b模式时,代表读取3个字节
read()默认读取整个文件
其余的文件内光标移动都是以字节为单位如seek,tell,truncate
例子
test.txt文件内容
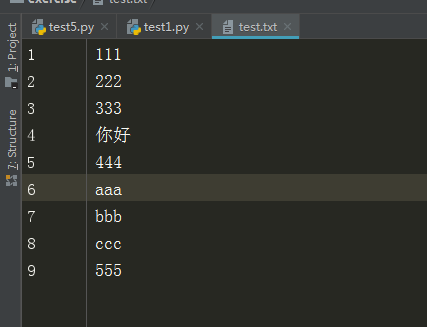
f = open("test.txt","rb")
data = f.read(6)
f.close()
print(data)
输出结果
b'111\r\n2'
分析:这里的111算3个字节,\r\n算2个字节,2算1个字节,这里是b模式,以字节进行计算,这里不能指定编码即不能写encoding = "xx",否则会报错
例子2
文件内容与上面相同
f = open("test.txt","r+",encoding="utf-8")
data = f.read(6)
f.close()
print(data)
输出结果
111
22
分析:这是文本模式,这里的111算3个字符,换行符\r\n算一个字符,22算2个字符,共计6个字符。
11、seek()
seek()移动文件光标到到指定位置。
seek()语法
f.seek(offset[, whence])
offset即移动多少个字节数,whence有0,1,2三种模式,0 代表文件开始算, 1 代表当前位置开始算, 2 代表文件末尾开始算,默认是0。其中1和2必须在b模式下进行,但无论哪种模式,都是以bytes为单位移动的,Widnows 系统下的换行代表2个字节大小(\r\n)。
例子
test.txt文件内容
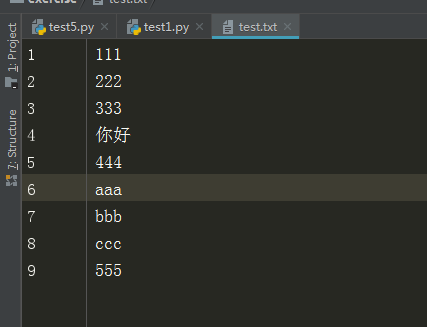
f = open("test.txt","r+",encoding="utf-8")
f.seek(3,0)
data = f.read()
f.close()
print(data)
输出结果
222
333
你好
444
aaa
bbb
ccc
555
例子2
文件内容与上面相同
f = open("test.txt","rb")
f.seek(5)
f.seek(11,1)
print(f.tell())
data = f.read()
f.close()
print(data)
输出结果
16 b'\xbd\xa0\xe5\xa5\xbd\r\n444\r\naaa\r\nbbb\r\nccc\r\n555'
分析

这里是以二进制打开的,111算3个字节,后面有个看不见的\r\n换行符,因此,seek(5)的位置就是第一行的最后
seek(11,1)是从当前位置继续移动光标,即222\r\n算5个字节,同理333\r\n算5个字节,“你好”(文本文件是utf-8编码的)算6个字节,因此这时只取“你”这个字的3个字节的第一个字节,光标移动到你的第一个字节之后,所以最后输出了\xbd\xa0\xe5\xa5\xbd共5个字节。
注意这里的光标操作要用seek()方法,直接用鼠标移动光标是无效的。
例子3
文件内容
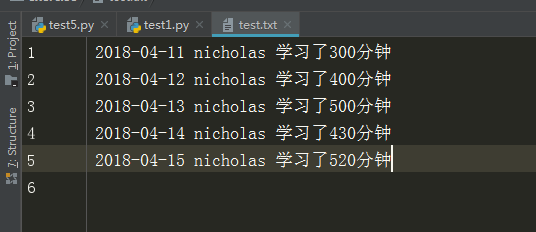
f = open("test.txt","rb")
offs = -20
while True:
f.seek(offs,2)
data = f.readlines()
if len(data) > 1:
print("文件的最后一行是%s"%data[-1].decode("utf-8"))
breakf = open("test.txt","rb")
offs = -20
while True:
f.seek(offs,2)
data = f.readlines()
if len(data) > 1:
print("文件的最后一行是%s"%data[-1].decode("utf-8"))
break
这里目的是在不知道一行是多少字节的情况下输入最后一行
输出结果
文件的最后一行是2018-04-15 nicholas 学习了520分钟
分析:seek(-20,2)是从文件的最后开始计算的,必须以b模式进行。
12、 truncate()
truncate() 方法用于从文件的首行首字节开始截断,截断文件为 size 个字节,无 size 表示从当前位置截断;截断后面的所有字节被删除,其中 Widnows 系统下的换行代表2个字节大小。
例子
文件内容
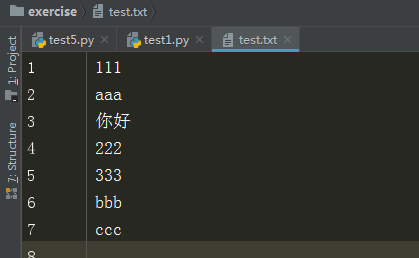
f = open("test.txt","r+")
f.truncate(10)
data = f.read()
print(data)
输出结果
111 aaa
分析:这里是以字节进行计算的,111算3个字节,后面的换行符算2个字节,所以这里截取了111aaa和之后的2个换行符,共计10个字节。
Python之路Python文件操作的更多相关文章
- 小白的Python之路 day2 文件操作
文件操作 对文件操作流程 打开文件,得到文件句柄并赋值给一个变量 通过句柄对文件进行操作 关闭文件 现有文件如下 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 1 ...
- python之路(五)-文件操作
文件操作无非两个,即:读.写 python 2.x: 文件句柄 = file('文件路径', '模式') python3.x: 文件句柄 = open('文件路径', '模式') 打开文件的模式有: ...
- python之路---08 文件操作
二十六. 文件 f = open(文件路径,mode = '模式',encoding = '编码格式') 1.基础 ① 读写时,主要看光标的位置 ②操作完成要写 f.close( ) f.f ...
- Python之路Python内置函数、zip()、max()、min()
Python之路Python内置函数.zip().max().min() 一.python内置函数 abs() 求绝对值 例子 print(abs(-2)) all() 把序列中每一个元素做布尔运算, ...
- 自学Python之路-Python基础+模块+面向对象+函数
自学Python之路-Python基础+模块+面向对象+函数 自学Python之路[第一回]:初识Python 1.1 自学Python1.1-简介 1.2 自学Python1.2-环境的 ...
- Python之路Python作用域、匿名函数、函数式编程、map函数、filter函数、reduce函数
Python之路Python作用域.匿名函数.函数式编程.map函数.filter函数.reduce函数 一.作用域 return 可以返回任意值例子 def test1(): print(" ...
- Python之路Python全局变量与局部变量、函数多层嵌套、函数递归
Python之路Python全局变量与局部变量.函数多层嵌套.函数递归 一.局部变量与全局变量 1.在子程序中定义的变量称为局部变量,在程序的一开始定义的变量称为全局变量.全局变量作用域是整个程序,局 ...
- 自学Python之路-Python核心编程
自学Python之路-Python核心编程 自学Python之路[第六回]:Python模块 6.1 自学Python6.1-模块简介 6.2 自学Python6.2-类.模块.包 ...
- 自学Python之路-Python并发编程+数据库+前端
自学Python之路-Python并发编程+数据库+前端 自学Python之路[第一回]:1.11.2 1.3
随机推荐
- Android 截屏检测
最近项目中新接到一个需求,对手机截屏进行检测并进行后续操作,类似于Snapchat,iOS具有先天优势,因iOS系统提供了相关API!Google无果之后原作者决定再次造轮子,为了持续表达对Rx的敬意 ...
- wordpress get_query_var()函数
get_query_var函数的最主要作用就是能够查询得到当前文章的分类及分页.定义在:wp-includes/query.php 定义: function get_query_var($var) { ...
- 斯坦福CS229机器学习课程笔记 part3:广义线性模型 Greneralized Linear Models (GLMs)
指数分布族 The exponential family 因为广义线性模型是围绕指数分布族的.大多数常用分布都属于指数分布族,服从指数分布族的条件是概率分布可以写成如下形式:η 被称作自然参数(nat ...
- 粗粒度(Coarse-grained)vs细粒度(fine-grained)
在读的一篇文献中关于RDF的描述: As we know, RDF data is a set of triples with the form (subject, property, object) ...
- c++原型模式(Prototype)
原型模式是通过已经存在的对象的接口快速方便的创建新的对象. #include <iostream> #include <string> using namespace std; ...
- SpringBoot22 Ajax跨域、SpringBoot返回JSONP、CSRF、CORS
1 扫盲知识 1.1 Ajax为什么存在跨域问题 因为浏览器处于安全性的考虑不允许JS执行跨域请求. 1.2 浏览器为什么要限制JS的跨域访问 如果浏览器允许JS的跨域请求就很容易造成 CSRF (C ...
- ShopNc登录验证码
- GridView删除行
在GridView绑定数据的时候需要设置该GridView的主键值,设置的这个主键与取出来的数据的一个字段对应.比如,取出来的数据表中有个ID的字段,那设这个ID为该GridView的主键是比较好的. ...
- sql语句in超过1000时的写法
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- Tarjan算法求出强连通分量(包含若干个节点)
[功能] Tarjan算法的用途之一是,求一个有向图G=(V,E)里极大强连通分量.强连通分量是指有向图G里顶点间能互相到达的子图.而如果一个强连通分量已经没有被其它强通分量完全包含的话,那么这个强连 ...