整个ssd的网络和multibox_loss_layer
总结说来prior_box层只完成了一个提取anchor的过程,其他与gt的match,筛选正负样本比例都是在multibox_loss_layer完成的
http://www.360doc.com/content/17/0810/10/10408243_678091430.shtml
1.以mobileNet-ssd为例子:https://github.com/chuanqi305/MobileNet-SSD/blob/master/train.prototxt
ssd在6个层上进行了预测,从6个feature map分别做了confidence和location预测,这些预测都是从相应层的feature map做一个1*1卷积,w和h是不变的,但channel会做改变,confidence:prior_num*class_num, location:prior_num*4
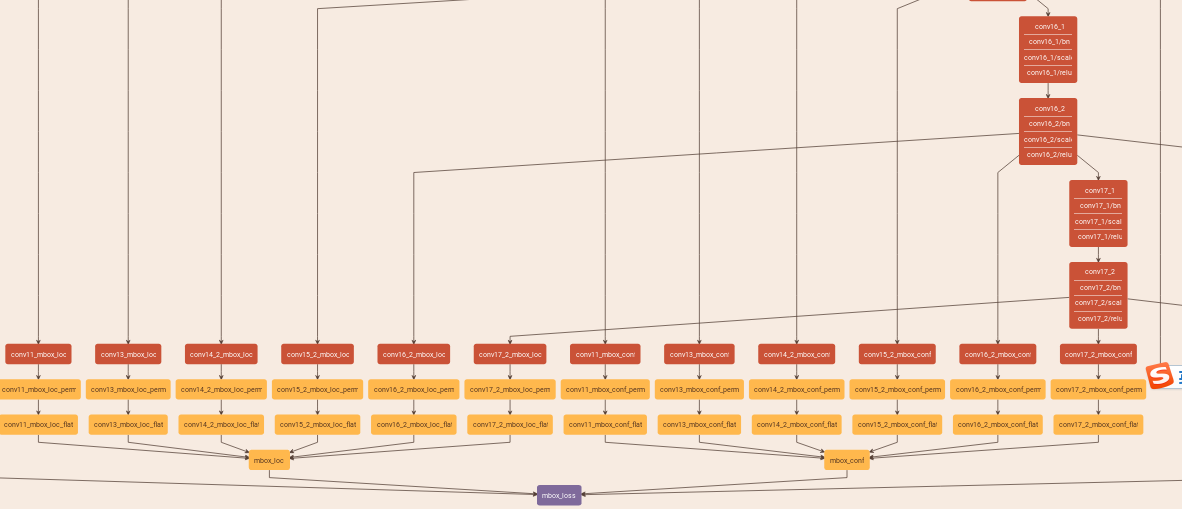
卷积都会经过一个permute层把原来的blob从nchw的顺序变成n,h,w,c,然后在flatten变成n,h*w*c,最后再通过concat把6个预测连接起来,最后就变成了一个一维的blob,比如mbox_conf前4个值代表的是4个prior为第0类的概率,shape的变化可以看下图:
为什么是conv4_3的channel是84,16;fc7的channel是126,24?
84 = 4*21,16 = 4*4
126 = 6*21,24 = 6*4
conv4_3的anchor是4个,fc7的anchor是6个,分类的channel是anchor数*分类数,bouding box的channel是anchor数*4个坐标

https://www.zhihu.com/question/269160464/answer/400342428,这个解释了为什么要进行permute,如果不进行permute直接进行flatten会让prior的值不在连续的存储空间
可以这样理解,flatten从axis=1开始摊开,先摊开的是第四维,摊完之后再是第三维,再是第二维.所以把84所代表的prior换到第四维,就先摊开类别和anchor个数
其实最终这个一维的blob都会对应某一个feature map中的某一个点的某一个anchor
2.https://blog.csdn.net/qianqing13579/article/details/80146425:
* Forward_cpu的主要流程: FindMatches:确定哪些priorbox是正样本,哪些是负样本,存放在all_match_indices_中
MineHardExamples:Minig出符合条件的负样本 计算正样本的定位
loss 计算所有正样本+Mining出来的负样本的分类loss
最后的loss为定位和分类loss的加权和
先GetGroundTruth、GetPriorBBoxes、GetLocPredictions分别得到gt,prior_box和预测的bounding box regression的值,然后FindMatches将prior的坐标和boudingbox坐标相加变成真正的预测框再和gt进行一个匹配.值得注意的是先是从groudtruth box出发给每个groudtruth box找到了最匹配的prior box放入候选正样本集,然后再从prior box出发为prior box集中寻找与groundtruth box满足IOU>0.5的一个IOU最大的prior box(如果有的话)放入候选正样本集,这样显然就增大了候选正样本集的数量.https://www.cnblogs.com/xuanyuyt/p/7447111.html
https://www.cnblogs.com/lillylin/p/6207292.html 然后MineHardExamples根据confidence loss排序,选取loss最大的前面一些并保证正负比1:3进行训练
https://www.sohu.com/a/168738025_717210,这个网页的ssd网络图比较完整,并且是以vgg为backbone,从conv6_1开始是ssd在vgg上添加的网络层,ssd是在6个层进行了预测

其他层都是直接从feature map上直接使用3*3,pad=1,stride=1的卷积生成分类和回归,但conv4_3的分类和回归是先norm了再用的卷积
整个ssd的网络和multibox_loss_layer的更多相关文章
- SSD训练网络参数计算
一个预测层的网络结构如下所示: 可以看到,是由三个分支组成的,分别是"PriorBox"层,以及conf.loc的预测层,其中,conf与loc的预测层的参数是由PriorBox的 ...
- SSD源码解读——网络搭建
之前,对SSD的论文进行了解读,可以回顾之前的博客:https://www.cnblogs.com/dengshunge/p/11665929.html. 为了加深对SSD的理解,因此对SSD的源码进 ...
- 『TensorFlow』SSD源码学习_其六:标签整理
Fork版本项目地址:SSD 一.输入标签生成 在数据预处理之后,图片.类别.真实框格式较为原始,不能够直接作为损失函数的输入标签(ssd向前网络只需要图像就行,这里的处理主要需要满足loss的计算) ...
- [目标检测]SSD原理
1 SSD基础原理 1.1 SSD网络结构 SSD使用VGG-16-Atrous作为基础网络,其中黄色部分为在VGG-16基础网络上填加的特征提取层.SSD与yolo不同之处是除了在最终特征图上做目标 ...
- 转:SSD详解
原文:http://blog.csdn.net/a8039974/article/details/77592395, http://blog.csdn.net/jesse_mx/article/det ...
- 【目标检测】SSD:
slides 讲得是相当清楚了: http://www.cs.unc.edu/~wliu/papers/ssd_eccv2016_slide.pdf 配合中文翻译来看: https://www.cnb ...
- SSD源码解读——网络测试
之前,对SSD的论文进行了解读,可以回顾之前的博客:https://www.cnblogs.com/dengshunge/p/11665929.html. 为了加深对SSD的理解,因此对SSD的源码进 ...
- SSD算法的实现
本文目的:介绍一个超赞的项目--用Keras来实现SSD算法. 本文目录: 0 前言 1 如何训练SSD模型 2 如何评估SSD模型 3 如何微调SSD模型 4 其他注意点 0 前言 我在学习完SSD ...
- 目标检测算法的总结(R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD、FNP、ALEXnet、RetianNet、VGG Net-16)
目标检测解决的是计算机视觉任务的基本问题:即What objects are where?图像中有什么目标,在哪里?这意味着,我们不仅要用算法判断图片中是不是要检测的目标, 还要在图片中标记出它的位置 ...
随机推荐
- How to fix the issue that GEM_HOME and/or GEM_PATH not set issue for rvm in mac version 10.12
add following lines below "export PATH="$PATH:$HOME/.rvm/bin" # Add RVM to PATH for s ...
- (Frontend Newbie)JavaScript基础之函数
函数可以说是任何一门编程语言的核心概念.要能熟练掌握JavaScript,对于函数及其相关概念的学习是非常重要的一步.本篇从函数的基本知识.执行环境与作用域.闭包.this关键字等方面简单介绍Java ...
- 如何看linux是32位还是64位--转
地址:http://hi.baidu.com/hehongrong/item/20c296bcf8d834432aebe3b2 如何看linux是32位还是64位 如何看linux是32位还是64位 ...
- gcc 链接非标准名称库
一般库的标准名称是libxxx.so或者libxxx.a, 如果没有, 也可以搞个linkname出来, 那就可以直接用 "-lxxx" 来链接了, 但要是你想直接用realnam ...
- swpuctf-web部分学习总结
1.用优惠码 买个 X ? (1)第一步: 这道题第一步主要知道利用php的随机种子数泄露以后就可以利用该种子数来预测序列,而在题目中会返回15位的优惠码,但是必须要24位的优惠码,因此要根据15位的 ...
- 利用pandas生成csv文件
# -*- coding:UTF-8 -*- import json from collections import OrderedDict with open('dns_status.json',' ...
- 【Xshell】设置XShell最大的显示行数
选择会话,依次点击“文件"->"属性”,打开“会话属性”窗体 在“会话属性”窗体中,选择“终端”,下图中红框标注的地方是“缓冲区大小”,修改其中的值,其范围在0~2,14 ...
- python爬虫学习(一)
#简单例子:抓取网页全部内容后,根据正则表达式,获取符合条件的字符串列表from urllib import request#正则表达式import re url = "http://www ...
- MySQL中在原表中做数据去重(按日期去重,保留id最小的记录)
表名称 code600300 delete from code600300 where id not in (select minid from (select min(id) as minid fr ...
- spynner解析中文页面,应该显示中文字符的地方都是?的解决方案
这个是底层的QtWebKit相关库里 用的是Qt的QString spynner在将QString转为Python的通用字符串时,没有考虑到中文编码这一块的问题. Python27\Lib\site- ...