图的遍历——DFS
原创
图的遍历有DFS和BFS两种,现选用DFS遍历图。
存储图用邻接矩阵,图有v个顶点,e条边,邻接矩阵就是一个VxV的矩阵;
若顶点1和顶点5之间有连线,则矩阵元素[1,5]置1,若是无向图[5,1]也
置1,两顶点之间无连线则置无穷,顶点到顶点本身置0。
例如:
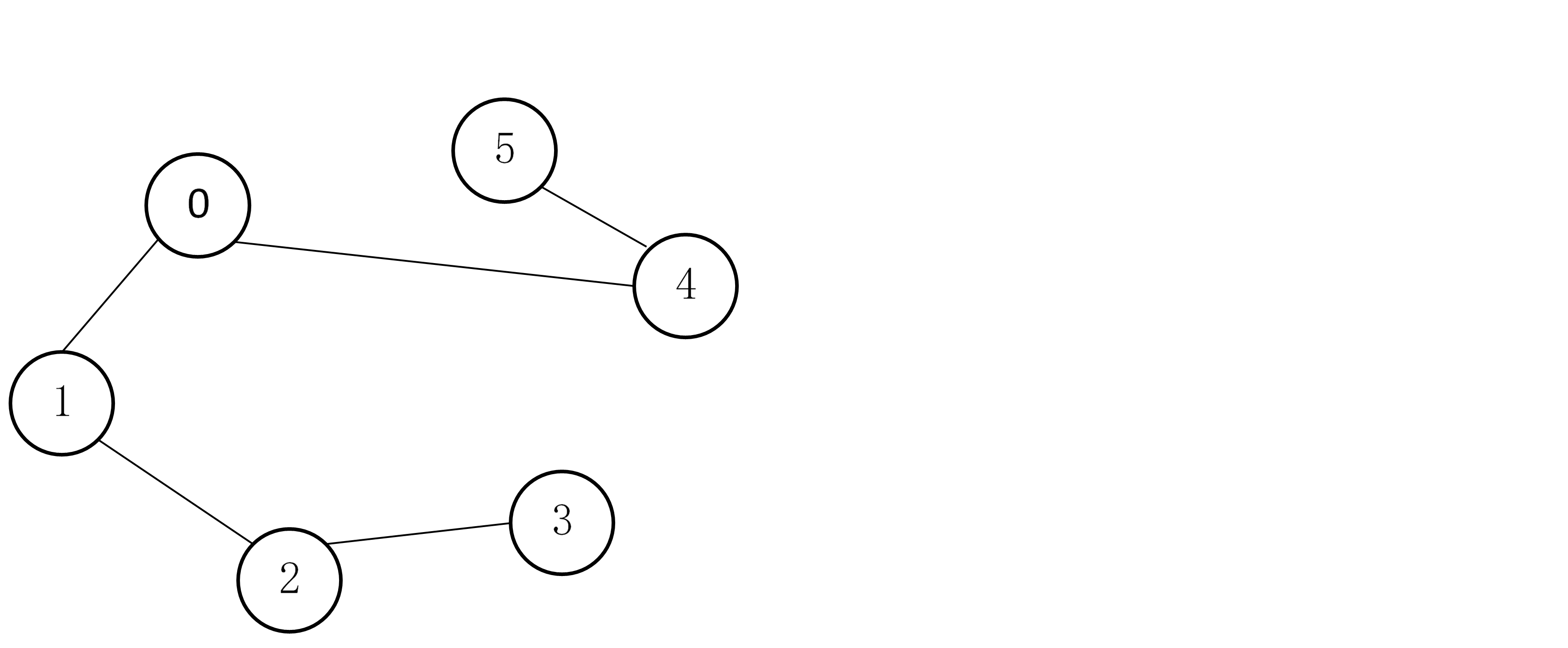
邻接矩阵为:

遍历思路:
随便选择一未访问过的顶点v1作为遍历起点,访问v1,再选择与v1连接的点v2作为起始点,访问v2;
再选择与v2连接的点作为起始点v3,访问v3,假设v3是孤立点,则v3不能往下访问,回溯到v2,再以v2
作为起点,访问与v2连接的其他未被访问过的顶点,假设是v4,则再以v4为顶点,访问v4,再选择与v4
连接的顶点为起始点......直到全部顶点都被访问过一遍。
在上图中,假设以顶点2为起点进行图的遍历,则先访问顶点2,再访问顶点1,注意,并不是先访问
3,因为在扫描邻接矩阵时,在每行是从左向右扫描的;再访问顶点0,再深搜下去访问顶点4,访问顶点
5,一直回溯,回溯到顶点2,再访问顶点3;访问顺序为:2 1 0 4 5 3
Java:
import java.util.*;
public class 图的遍历_dfs {
static int v; //顶点数
static int e; //边数
static int arr[][];
static int book[]; //标识顶点是否访问
static int max=99999; //无穷
static int total=0; //统计已访问顶点个数
static void graph_dfs(int ver) { //ver表示顶点
total++;
book[ver]=1; //标记顶点ver已经访问过
System.out.print(ver+" ");
if(total==v) {
return;
}
for(int i=0;i<v;i++) {
if(arr[ver][i]==1 && book[i]==0) {
graph_dfs(i);
}
}
return;
}
public static void main(String[] args) {
Scanner reader=new Scanner(System.in);
v=reader.nextInt();
e=reader.nextInt();
arr=new int[v][v];
book=new int[v];
//邻接矩阵初始化
for(int i=0;i<v;i++) {
book[i]=0;
for(int j=0;j<v;j++) {
if(i==j) {
arr[i][j]=0;
}
else {
arr[i][j]=max;
}
}
}
//读入边
for(int i=0;i<e;i++) {
int first_E=reader.nextInt();
int second_E=reader.nextInt();
arr[first_E][second_E]=1;
arr[second_E][first_E]=1;
}
graph_dfs(0); //从顶点0开始遍历
}
}
18:08:52
2018-07-22
图的遍历——DFS的更多相关文章
- 图的遍历DFS
图的遍历DFS 与树的深度优先遍历之间的联系 树的深度优先遍历分为:先根,后根 //树的先根遍历 void PreOrder(TreeNode *R){ if(R!=NULL){ visit(R); ...
- 图的遍历——DFS(矩形空间)
首先,这里的图不是指的我们一般所说的图结构,而是大小为M*N的矩形区域(也可以看成是一个矩阵).而关于矩形区域的遍历问题经常出现,如“寻找矩阵中的路径”.“找到矩形区域的某个特殊点”等等之类的题目,在 ...
- 图的遍历——DFS和BFS模板(一般的图)
关于图的遍历,通常有深度优先搜索(DFS)和广度优先搜索(BFS),本文结合一般的图结构(邻接矩阵和邻接表),给出两种遍历算法的模板 1.深度优先搜索(DFS) #include<iostrea ...
- 图的遍历——DFS(邻接矩阵)
递归 + 标记 一个连通图只要DFS一次,即可打印所有的点. #include <iostream> #include <cstdio> #include <cstdli ...
- 图的遍历---DFS
类型一:邻接表 题目一:员工的重要性 题目描述 给定一个保存员工信息的数据结构,它包含了员工唯一的id,重要度 和 直系下属的id. 比如,员工1是员工2的领导,员工2是员工3的领导.他们相应的重要度 ...
- 图的遍历(DFS、BFS)
理论: 深度优先搜索(Depth_Fisrst Search)遍历类似于树的先根遍历,是树的先根遍历的推广: 广度优先搜索(Breadth_First Search) 遍历类似于树的按层次遍历的过程: ...
- 16.boost图深度优先遍历DFS
#include <iostream> #include <boost/config.hpp> //图(矩阵实现) #include <boost/graph/adjac ...
- 图的遍历[DFS][BFS]
#include<iostream> #include<iostream> #include<cstring> #include<queue> #inc ...
- 图的数据结构的实现与遍历(DFS,BFS)
//图的存储结构:const int MAXSIZE = 10;//邻接矩阵template<class T>class MGraph {public: MGraph(T a[], ...
随机推荐
- 关于android方向传感器的使用
Android2.2以后 orientation sensors 就被deprecated了 官方建议用acceleration and magnetic sensor 来算 关于这个问题,CSDN上 ...
- nginx虚拟主机的配置
nginx虚拟主机的配置 server { listen ; server_name 127.0.0.1; access_log off; root /var/www/html/; location ...
- Windows10 官方原版镜像下载途径 Label:win10解决方案
https://www.microsoft.com/en-gb/software-download/windows10ISO 设置浏览标签为手机以避免跳转,下载即可 或者手机打开该网址,获取下载链接 ...
- Java-Maven-Runoob:Maven POM
ylbtech-Java-Maven-Runoob:Maven POM 1.返回顶部 1. Maven POM POM( Project Object Model,项目对象模型 ) 是 Maven 工 ...
- Shell编程的基本语法
Shell编程 创建sh文件 touch test.sh vim test.sh 写入如下内容 #!/bin/bash a="hello" 运行 chmod +x /root/te ...
- Python中的 set 与 深浅拷贝
字符串 join() 格式: "拼接的东西".join(可迭代对象) 可以加列表转换成字符串 lis = ['a','b','c','d'] s = "//" ...
- MAPREDUCE原理篇2
mapreduce的shuffle机制 概述: mapreduce中,map阶段处理的数据如何传递给reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle: shuf ...
- SonarQube在CentOS上的安装
1 简介 SonarQube 是一个用于代码质量管理的开放平台.通过插件机制,Sonar 可以集成不同的测试工具,代码分析工具,以及持续集成工具.与持续集成工具(例如 Hudson/Jenkins 等 ...
- Java基础知识(二)之控制语句
1.条件运算符 ⑴if...else... ⑵三目表达式——X?Y:Z 当X为真时,结果为Y:反之,为Z. ⑶switch(表达式){ case 1: 执行代码块 1; break: cas ...
- Spring总结八:jdbcTemplate的简单使用
简介: Srping毕竟是一站式框架,所以也有操作数据库的东西,那就是jdbcTemplate,介绍一下jdbcTemplate的简单使用. 除了要引入必要的包以外,还需要引入 spring-jdbc ...