机器学习常用性能度量中的Accuracy、Precision、Recall、ROC、F score等都是些什么东西?
一篇文章就搞懂啦,这个必须收藏!
我们以图片分类来举例,当然换成文本、语音等也是一样的。
Positive
正样本。比如你要识别一组图片是不是猫,那么你预测某张图片是猫,这张图片就被预测成了正样本。Negative
负样本。比如你要识别一组图片是不是猫,那么你预测某张图片不是猫,这张图片就被预测成了负样本。TP
一组预测为正样本的图片中,真的是正样本的图片数。TN:
一组预测为负样本的图片中,真的是负样本的图片数。FP:
一组预测为正样本的图片中,其实是负样本的图片数。又称“误检”FN:
一组预测为负样本的图片中,其实是正样本的图片数。又称“漏检”。精度(accuracy)
分类正确的样本数占总样本数的比例。
acc = (TP+TN)/ 总样本数查准率/准确率 precision
一组预测为正样本的图片中,真的是正样本的图片所占的比例。

为什么有了Accuracy还要提出Precision的概念呢?因为前者在测试样本集的正负样本数不均衡的时候,比如正样本数为1,负样本数为99时,模型只要每次都将给定的样本预测成负样本,那么Accuracy = (0+99)/100 = 0.99,精度依然可以很高,但这毫无意义。但是同样的样本集,同样的方法运用到查准率公式上,就不可能得到一个很高的值了。
查全率/召回率 recall
所有真的是正样本的图片中,被成功预测出来的图片所占的比例。

查准率和查全率的关系
一般来说,想查的准,那么往往查不全(想想宁缺毋滥);想查的全,又往往会不准(想想宁抓错不放过)。所以P和R是两个矛盾的量。P-R曲线 (查准率-查全率曲线)
该曲线是通过取不同的阈值下的P和R,绘制出来。这里的阈值就是指模型预测样本为正样本的概率。比如阈值取0.6,则所有被预测出的概率大于该阈值的样本,都认为是被预测成了正样本,这些被预测成正样本的样本中,实际是由TP(真的是正样本)和FP(并不是正样本)组成的。所以取一个阈值,就能计算出一组P-R,那么取多个阈值后,P-R曲线就绘制出来了。

从上图中可以看到,P-R曲线是采用平衡点(P=R的点)来判断哪个学习器更好(图中有A、B、C三个学习器),A好于B好于C。
- F1分数和Fβ分数
然而,上面的度量方法只能通过看图来理解,但是我们希望能更直接的通过一个分数来判定模型的好坏。所以更常用来度量的方法是取相同阈值下各模型的F1分数或Fβ分数(以下截图来自周志华老师的西瓜书[1]):

F1分数的公式是怎么来的呢?看下图:2.10的公式,其实是由下面的调和平均公式推导出来的。

所谓调和平均数就是:所有数字的倒数求算术平均后,再取倒数。该值平均考虑了P和R的表现。
为什么β>1时查全率有更大影响,而β<1时查准率有更大影响呢?看下图:2.11的公式,其实是由下面的加权调和平均公式推导出来的。

β的平方相当于1/R的权重,当β大于1,相当于提高1/R的重要度,当β小于1,相当于降低了1/R的重要度,而R正是查全率。
所以,当我们更倾向于查准率R的表现(即想查的更全,宁抓错不放过)时,可以将β设置为一个大于1的数字,具体设置多少,就要看倾向程度了,然后进行Fβ分数的比较。
- ROC曲线
ROC的全称是Receiver operating characteristic,翻译为受试者工作特征。先不用管这个名字有多难理解。我们先弄清楚ROC曲线是什么。ROC曲线如下图[2]:

纵坐标是真正率(其实就是召回率/查全率)=TP/(TP+FN),横坐标是假正率(误检率FPR)=FP/(FP+TN)。
该曲线是模型在不同阈值(与PR曲线中提到的阈值意思一样)下的查全率和误检率的表现。当阈值设为0时,相当于所有样本预测为正,查全率达到1,误检率当然也达到1;当阈值设为1时,相当于所有样本预测为负,查全率达到0(太严格了),误检率当然也达到0(因为严格嘛)。
因为我们希望召回率高,误检率低,所以曲线上越接近左上角(0,1)的点表现越好。所以ROC曲线是干嘛的?就是通过查全率和误检率的综合表现来评价模型的好坏用的。
你可以尝试大量增加测试样本的正样本或负样本的数量,让数据集变的不均衡,然后会发现ROC曲线可以几乎稳定不变,而PR曲线会发生巨大的变化。如下图:[5]。

可以根据PR曲线中P(precision)的公式,R(recall)的公式,根据ROC曲线中R(recall)的公式,误检率(FPR)的公式来理解,这里不细说了。
- AUC
area under curve。定义为ROC曲线下的面积。然因为这个面积的计算比较麻烦。所以大牛们总结出了下面的等价的计算方法。
假设一组数据集中,实际有M个正样本,N个负样本。那么正负样本对就有M*N种。
AUC的值等同于在这M*N种组合中,正样本预测概率大于负样本预测概率的组合数所占的比例。

其中I函数定义如下:
P正>P负,输出1;
P正=P负,输出0.5;
P正<P负,输出0。
上面的计算方法已经比计算面积要愉快多了,但是还有相对更好的计算思路:
按照预测概率从小到大排序,得到排好序的M*N个组合,其中正样本的序号就表示比当前正样本概率小的样本个数,再从这些样本中减去正样本的个数,就得到了当前正样本概率大于负样本概率的组合数。
为了计算方便,我们先把排好序的M*N个组合中所有正样本的序号累加,然后减去正样本的个数的累加,就得到了所有正样本概率大于负样本概率的组合数,然后除以M*N,就得到了在这M*N种组合中,正样本预测概率大于负样本预测概率的组合数所占的比例,这个比例等同于AUC。下面我们来看看具体的计算公式[4] :
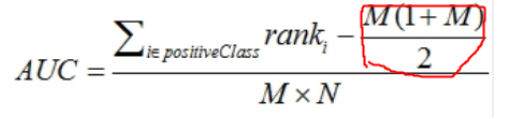
看上去挺复杂的,稍微解释一下你就明白了。
分子左边的部分就是排好序的M*N个组合中所有正样本的序号累加,
分子右边的部分其实就是正样本的个数的累加的公式,这个稍微解释一下:比如我们有5个正样本,那么正样本的个数累加就是1+2+3+4+5=15,带入公式就是5*(1+5)/2=15,而这个公式就是“高斯等差数列求和公式”: (首项+末项)x项数÷2。
分母部分比较好理解了,就是所有的正负样本的组合数。
如果在排序的时候遇到了概率值相同的情况,其实谁前谁后是没有关系的,只是在累加正样本的序号的时候,如果有正样本的概率值和其他样本(包括正和负)的概率值一样,那么序号是通过这些相同概率值的样本的序号的算术平均数来计算的。举例如下[3]:
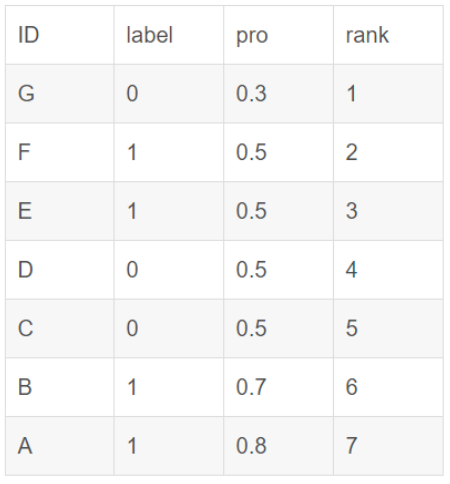
在累加正样本的序号的时候,正样本的rank(序号)值:
对于正样本A,其rank值为7
对于正样本B,其rank值为6
对于正样本E,其rank值为(5+4+3+2)/4
对于正样本F,其rank值为(5+4+3+2)/4
最后正样本的序号累加计算就是:

求出了各个模型的ROC曲线下的面积,也就是AUC,就可以比较模型之间的好坏啦。
注意
以上度量指标一般都是用于二元分类,如果是在多分类的场景下,可以拆成多个二分类问题来度量。而如果除了分类还有其他预测的任务,就需要针对性的度量指标来评估模型的好坏了。比如像目标检测,除了目标分类,还要预测目标的边界框位置,所以用的是mAP指标,具体可以参考下一篇文章《目标检测中为什么常提到IoU和mAP,它们究竟是什么?》
参考文献
[1]《西瓜书》周志华 著
[2]《机器学习实战》Peter Harrington 著
[3] https://blog.csdn.net/qq_22238533/article/details/78666436
[4] https://blog.csdn.net/pzy20062141/article/details/48711355
[5] https://www.cnblogs.com/dlml/p/4403482.html
ok,本篇就这么多内容啦~,感谢阅读O(∩_∩)O,88~
机器学习常用性能度量中的Accuracy、Precision、Recall、ROC、F score等都是些什么东西?的更多相关文章
- 机器学习--如何理解Accuracy, Precision, Recall, F1 score
当我们在谈论一个模型好坏的时候,我们常常会听到准确率(Accuracy)这个词,我们也会听到"如何才能使模型的Accurcy更高".那么是不是准确率最高的模型就一定是最好的模型? 这篇博文会向大家解释 ...
- 机器学习基础梳理—(accuracy,precision,recall浅谈)
一.TP TN FP FN TP:标签为正例,预测为正例(P),即预测正确(T) TN:标签为负例,预测为负例(N),即预测正确(T) FP:标签为负例,预测为正例(P),即预测错误(F) FN:标签 ...
- 斯坦福大学公开课机器学习:machine learning system design | trading off precision and recall(F score公式的提出:学习算法中如何平衡(取舍)查准率和召回率的数值)
一般来说,召回率和查准率的关系如下:1.如果需要很高的置信度的话,查准率会很高,相应的召回率很低:2.如果需要避免假阴性的话,召回率会很高,查准率会很低.下图右边显示的是召回率和查准率在一个学习算法中 ...
- 目标检测的评价标准mAP, Precision, Recall, Accuracy
目录 metrics 评价方法 TP , FP , TN , FN 概念 计算流程 Accuracy , Precision ,Recall Average Precision PR曲线 AP计算 A ...
- Classification week6: precision & recall 笔记
华盛顿大学 machine learning :classification 笔记 第6周 precision & recall 1.accuracy 局限性 我们习惯用 accuracy ...
- Precision,Recall,F1的计算
Precision又叫查准率,Recall又叫查全率.这两个指标共同衡量才能评价模型输出结果. TP: 预测为1(Positive),实际也为1(Truth-预测对了) TN: 预测为0(Negati ...
- 查准与召回(Precision & Recall)
Precision & Recall 先看下面这张图来理解了,后面再具体分析.下面用P代表Precision,R代表Recall 通俗的讲,Precision 就是检索出来的条目中(比如网页) ...
- 机器学习实战笔记(Python实现)-07-模型评估与分类性能度量
1.经验误差与过拟合 通常我们把分类错误的样本数占样本总数的比例称为“错误率”(error rate),即如果在m个样本中有a个样本分类错误,则错误率E=a/m:相应的,1-a/m称为“精度”(acc ...
- 【分类问题中模型的性能度量(一)】错误率、精度、查准率、查全率、F1详细讲解
文章目录 1.错误率与精度 2.查准率.查全率与F1 2.1 查准率.查全率 2.2 P-R曲线(P.R到F1的思维过渡) 2.3 F1度量 2.4 扩展 性能度量是用来衡量模型泛化能力的评价标准,错 ...
随机推荐
- 通过livy向CDH集群的spark提交任务
场景 产品中需要通过前端界面选择执行某种任务(spark任务),然后通过livy 的restful api 提交集群的spark任务 简单介绍下livy,翻译自官网: Livy是基于Apache许可的 ...
- Memcached的原理分析与配置
一.Why Memcached? • 高并发访问数据库的痛楚:死锁! • 硬盘IO之痛:本机:AspNet:HttpRuntime.Cache • 多客户端共享缓存 • Net+Memory>& ...
- Vue实现静态数据分页
<div style="padding:20px;" id="app"> <div class="panel panel-prima ...
- C#开发BIMFACE系列6 服务端API之获取文件信息
在<C#开发BIMFACE系列4 服务端API之源上传文件>.<C#开发BIMFACE系列5 服务端API之文件直传>两篇文章中详细介绍了如何将本地文件上传到BIMFACE服务 ...
- EF-运行原理
一.什么是EF? 实体架构(Entity Framework)是微软以来ADO.Net为基础开发出来的对象关系映射(ORM)解决方案,它解决了对象持久化问题,将程序员从编写麻烦的SQL语句中解放出来. ...
- jvm系列(五):Java GC 分析
Java GC就是JVM记录仪,书画了JVM各个分区的表演. 什么是 Java GC Java GC(Garbage Collection,垃圾收集,垃圾回收)机制,是Java与C++/C的主要区别之 ...
- 设计模式(C#)——11代理模式
推荐阅读: 我的CSDN 我的博客园 QQ群:704621321 前言 在软件开发过程中,当无法直接访问某个对象或访问某个对象存在困难时,我们希望可以通过一个中介来间接访问,这就是 ...
- MySQL IN和EXISTS的效率问题,以及执行优化
网上可以查到很多这样的说法: 如果查询的两个表大小相当,那么用in和exists差别不大.如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in: 例如:表A(小表),表B ...
- 图论之拓扑排序 poj 2367 Genealogical tree
题目链接 http://poj.org/problem?id=2367 题意就是给定一系列关系,按这些关系拓扑排序. #include<cstdio> #include<cstrin ...
- codeforces 808 D. Array Division(二分)
题目链接:http://codeforces.com/contest/808/problem/D 题意:有一串长度为n的数组,要求选择一个数字交换它的位置使得这串数能够分成两串连续的和一样的数组. 这 ...