斯坦福大学公开课机器学习:machine learning system design | trading off precision and recall(F score公式的提出:学习算法中如何平衡(取舍)查准率和召回率的数值)
一般来说,召回率和查准率的关系如下:1、如果需要很高的置信度的话,查准率会很高,相应的召回率很低;2、如果需要避免假阴性的话,召回率会很高,查准率会很低。下图右边显示的是召回率和查准率在一个学习算法中的关系。值得注意的是,没有一个学习算法是能同时保证高查准率和召回率的,要高查准率还是高召回率,取决于自己的需求。此外,查准率和召回率之间的关系曲线可以是多样性,不一定是图示的形状。

如何取舍查准率和召回率数值:
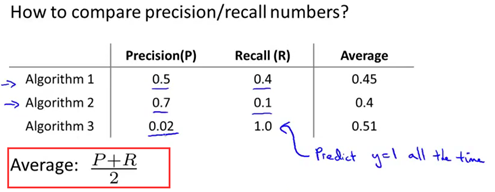
一开始提出来的算法有取查准率和召回率的平均值,如下面的公式average=(P+R)/2。显然,在给出的三个算法当中,算法3的平均值是最高的,然而通过查准率(0.02)和召回率(1.0)可以看出这并不是一个很好的模型。因此,取平均值这个评估模式是不可取的。
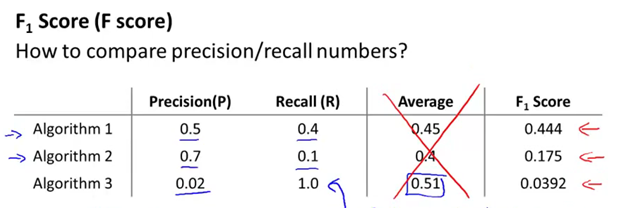
如果采用F score算法来同时评估查准率和召回率,则是比较有用的算法。分子的PR决定了查准率(P)和召回率(R)必须同时比较大,才能保证F score数值比较大。假如查准率或者召回率很低,接近于0,直接导致的后果PR值非常低,趋近于0,也就是F score也很低。

此时再比较三个算法,可发现算法1是最优的,同时我们观察到算法3在这个公式中F score值是最低的。很好的说明了算法3不是一个很好的模型(查准率太低)。说明F score是一个很好的同时评估查准率和召回率的公式。
斯坦福大学公开课机器学习:machine learning system design | trading off precision and recall(F score公式的提出:学习算法中如何平衡(取舍)查准率和召回率的数值)的更多相关文章
- 斯坦福大学公开课机器学习:advice for applying machine learning | diagnosing bias vs. variance(机器学习:诊断偏差和方差问题)
当我们运行一个学习算法时,如果这个算法的表现不理想,那么有两种原因导致:要么偏差比较大.要么方差比较大.换句话说,要么是欠拟合.要么是过拟合.那么这两种情况,哪个和偏差有关.哪个和方差有关,或者是不是 ...
- 第19月第8天 斯坦福大学公开课机器学习 (吴恩达 Andrew Ng)
1.斯坦福大学公开课机器学习 (吴恩达 Andrew Ng) http://open.163.com/special/opencourse/machinelearning.html 笔记 http:/ ...
- 斯坦福大学公开课机器学习:machine learning system design | error metrics for skewed classes(偏斜类问题的定义以及针对偏斜类问题的评估度量值:查准率(precision)和召回率(recall))
上篇文章提到了误差分析以及设定误差度量值的重要性.那就是设定某个实数来评估学习算法并衡量它的表现.有了算法的评估和误差度量值,有一件重要的事情要注意,就是使用一个合适的误差度量值,有时会对学习算法造成 ...
- 斯坦福大学公开课机器学习:advice for applying machine learning | model selection and training/validation/test sets(模型选择以及训练集、交叉验证集和测试集的概念)
怎样选用正确的特征构造学习算法或者如何选择学习算法中的正则化参数lambda?这些问题我们称之为模型选择问题. 在对于这一问题的讨论中,我们不仅将数据分为:训练集和测试集,而是将数据分为三个数据组:也 ...
- 斯坦福大学公开课机器学习: machine learning system design | error analysis(误差分析:检验算法是否有高偏差和高方差)
误差分析可以更系统地做出决定.如果你准备研究机器学习的东西或者构造机器学习应用程序,最好的实践方法不是建立一个非常复杂的系统.拥有多么复杂的变量,而是构建一个简单的算法.这样你可以很快地实现它.研究机 ...
- 斯坦福大学公开课机器学习: machine learning system design | prioritizing what to work on : spam classification example(设计复杂机器学习系统的主要问题及构建复杂的机器学习系统的建议)
当我们在进行机器学习时着重要考虑什么问题.以垃圾邮件分类为例子.假如你想建立一个垃圾邮件分类器,看这些垃圾邮件与非垃圾邮件的例子.左边这封邮件想向你推销东西.注意这封垃圾邮件有意的拼错一些单词,就像M ...
- 斯坦福大学公开课机器学习:Neural Networks,representation: non-linear hypotheses(为什么需要做非线性分类器)
如上图所示,如果用逻辑回归来解决这个问题,首先需要构造一个包含很多非线性项的逻辑回归函数g(x).这里g仍是s型函数(即 ).我们能让函数包含很多像这的多项式,当多项式足够多时,那么你也许能够得到可以 ...
- 斯坦福大学公开课机器学习:machine learning system design | data for machine learning(数据量很大时,学习算法表现比较好的原理)
下图为四种不同算法应用在不同大小数据量时的表现,可以看出,随着数据量的增大,算法的表现趋于接近.即不管多么糟糕的算法,数据量非常大的时候,算法表现也可以很好. 数据量很大时,学习算法表现比较好的原理: ...
- 斯坦福大学公开课机器学习:advice for applying machine learning - deciding what to try next(设计机器学习系统时,怎样确定最适合、最正确的方法)
假如我们在开发一个机器学习系统,想试着改进一个机器学习系统的性能,我们应该如何决定接下来应该选择哪条道路? 为了解释这一问题,以预测房价的学习例子.假如我们已经得到学习参数以后,要将我们的假设函数放到 ...
随机推荐
- 进程有一个全局变量i,还有有两个线程。i++在两个线程里边分别执行100次,能得到的最大值和最小值分别是多少?
转自https://blog.csdn.net/biubiu741/article/details/77990592 i++不是原子操作,也就是说,它不是单独一条指令,而是3条指令: 1.从内存中把i ...
- Gevent 性能和 gevent.loop 的运用和带来的思考
知乎自己在底层造了非常多的轮子,而且也在服务器部署方面和数据获取方面广泛使用 gevent 来提高并发获取数据的能力.现在开始我将结合实际使用与测试慢慢完善自己对 gevent 更全面的使用和扫盲. ...
- drf图片字段序列化完整路径
一.需求 前端需要它想要的数据格式: 原有的数据格式: 二.定制化: 1.可以嵌套序列化pol_type,lit_des,area_detail,但结构如下: class ChrDetailSeria ...
- 如何快速定位到DBGrid的某一行!!!急...
比如我查找张三,那么DBGrid就可以定位到张三那行并选中这行,除了用循环实现还有没有快速定位的方法,谢谢! 解决方案 » to SuperTitan001 那如何找到张三的这行呢?除了用循环还有什么 ...
- C#使用WebClient下载文件到本地目录
C#使用WebClient下载文件到本地目录. 1.配置本地目录路径 <appSettings> <!--文件下载目录--> <add key="Downloa ...
- mybatis-spring-1.2.2.jar下载地址
http://www.java2s.com/Code/Jar/m/Downloadmybatisspring120jar.htm
- 皮皮虾FAQ
我们提供的软件,是市场上比较好操作的,如果有其他的软件也是可以使用我们的ip的 Windows 1.windows找不到粘贴的地方 window打开窗口后,请在屏幕右下角找小飞机,右键即可 2.win ...
- FTP登录不上 显示“找不到元素”
FTP登录不上 显示“找不到元素” 问题描述: 资源管理器登陆不上ftp服务器,ie现在打不开网页(包括普通的网页和ftp)360等其他浏览器可以正常打开网页. 解决方法: 应该是用了代理软件的问题, ...
- python爬虫requests模块
requests库的七个主要方法 1. requests.requests(method, url, **kwargs) 构造一个请求,支撑以下各方法的基础方法 method:请求方式,对应get/p ...
- Keepalived+LVS高可用负载均衡集群
概述 Keepalived是专门针对LVS设计的一款强大的辅助工具,主要用来提供故障切换(Failover)和健康检查(HeathChecking)功能——判断LVS负载调度器.节点服务器的可用性,及 ...